




 本文详细介绍了SQL查询的各种操作,包括选择表中的特定列和元组、使用聚集函数、进行连接查询(等值连接、自身连接、外连接和多表连接)、嵌套查询(如IN、LIKE、ANY/SOME、ALL和EXISTS谓词)以及集合查询。此外,还讨论了基于派生表的查询,展示了如何通过子查询生成临时表并进行操作。无论你是初学者还是有经验的开发者,这篇文章都是深入理解SQL查询的好资源。
本文详细介绍了SQL查询的各种操作,包括选择表中的特定列和元组、使用聚集函数、进行连接查询(等值连接、自身连接、外连接和多表连接)、嵌套查询(如IN、LIKE、ANY/SOME、ALL和EXISTS谓词)以及集合查询。此外,还讨论了基于派生表的查询,展示了如何通过子查询生成临时表并进行操作。无论你是初学者还是有经验的开发者,这篇文章都是深入理解SQL查询的好资源。
目录
一、查询语句
select 列名 ···
from 表名···
where 条件
group by 列名 1[having 条件]
order by 列名 asc |desc
(1)group by 将结果按照列名1的值进行分组,属性列值相等的为一组
(2)having短语 满足条件的组输出
(3)order by 按照列名2的值排序 asc (升序),desc (降序)
二、单表查询
--选择表中的若干列
(1)查询指定列
select sno,sname
from student;
--改变列的显示顺序
select sname,sno
from student;
(2)查询所有列
select *
from student;
--等价于
select 列名···
from student;(3)查询经过计算的值
select 子句可以是 属性列,表达式,字符串常数,函数
--属性列
select sname
from student;
--表达式
select 2022-sage
from studnet;
--字符串常数
select 'year of birth'
from student
--函数
select lower(sdept)--小写字母
from student
tips:用户可以通过指定别名来改变查询结果的列标题
select sname NAME
from student;


--选择表中的若干元组
(1)消除取值重复的行--distinct
select distinct sno
from sc;(2)查询满足条件的元组
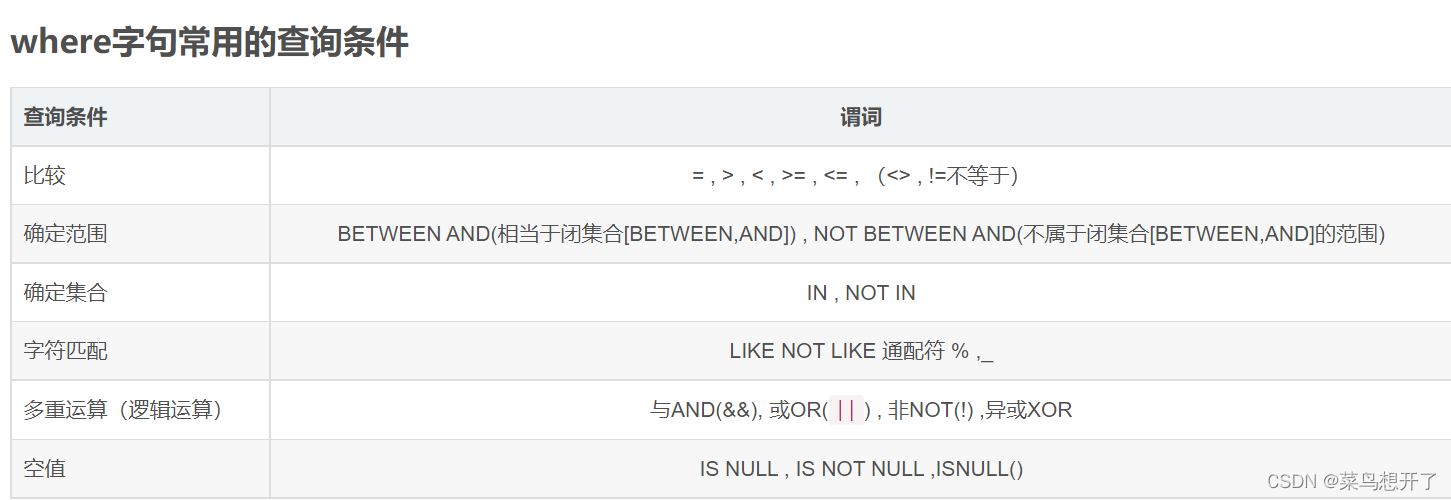
in 用来查找属性值属于指定集合的元组
like 用来进行字符串匹配,查找属性列值与 字符串相匹配的元组
语句:not like ’匹配串‘ [escape '换码字符’]
匹配串可以是完整字符串,也可以含有通配字符%和_
%代表任意长度的字符串
_代表任意单个字符
escape ‘\'表示”\"为换码字符,在\后面的%或者_不具有通配字符的含义
-- 聚集函数
count(*) --统计元组个数
count ([distinct |all] 列名) --统计一列中值的个数
sum ([distinct |all] 列名) --计算一列值的总和(值必须为数值型)
avg([distinct |all] 列名) --计算一列值的平均值(值必须为数值型)
max([distinct |all] 列名) --求一列值中的最大值
min([distinct |all] 列名) --求一列值中的最小值
distinct 表示计算时要不计算列中的重复值,每个值只计算一次
all为默认值,表示计算重复值
除count(*)函数外,聚集函数只处理非空值,跳过空值null
where子句中 不能用聚集函数作条件表达式
聚集函数只用在select子句和group by子句中
三、连接查询
1、等值连接查询
select stuent.*,sc.*
from student ,sc
where student.sno=sc.sno注意:表中的属性名不唯一时,select子句和where子句的属名前加表名前缀,会报错!
2、自身连接
3、外连接
如果学生没选课,等值连接会舍弃相关元组
若学生没选课,把student的悬浮元组保存在相关结果中,有一部分属性为null,使用外连接。
左连接 表1life outer join 表2 on()列出表1所有的元组
右连接 表1right outer join 表2 on()列出表2所有的元组
全外连接 表1full outer join 表2 on
4、多表连接
多个等值连接 and起来
四、嵌套查询
注意:子查询的select语句中不能用使用order by子句
1、带有in谓词的子查询
2、带有比较运算符的子查询
3、带有any(some)或all谓词的子查询
4、带有exists谓词的子查询
五、集合查询
多个select语句可以进行集合操作
集合操作包括1.并操作 union、2.交操作intersect 3.差操作 except
参与集合操作的查询结果的列名必须相同,数据类型也必须相同
六、基于派生表的查询
子查询出现在from子句中,生成的临时派生表成为主查询的查询对象
select sname
from student,(select sno from sc where cno='1') AS sc1
--子查询生成派生表
--as 关键词,通过from子句生成派生表时,可以省略
--sc1为派生表的别名,必须制定一个别名
where student.sno=sc1.sno;
--主查询将student表与sc1进行等值连接
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









