









 本文介绍Caffe支持的数据格式lmdb和h5py,分别适用于单标签和多标签数据,以及如何使用这些格式处理MNIST数据集。MNIST数据集包含手写数字图片,可用于训练和测试分类模型。
本文介绍Caffe支持的数据格式lmdb和h5py,分别适用于单标签和多标签数据,以及如何使用这些格式处理MNIST数据集。MNIST数据集包含手写数字图片,可用于训练和测试分类模型。
caffe对于训练数据格式,支持:lmdb、h5py……
lmdb:常用于单标签数据,像分类等
h5py:用于多标签数据,对于回归等问题
原因:
1、数据类型多种多样,有二进制文件、文本文件、编码后的图像文件(如JPEG、PNG、网络爬取的数据等),不可能用一套代码实现所有类型的输入数据读取,转换为统一格式可以简化数据读取层的实现;
2、使用LMDB、LEVELDB可以提高磁盘IO利用率。
MNIST数据集
MNIST 数据集可在 http://yann.lecun.com/exdb/mnist/ 获取, 它包含了四个部分:
每张图都已经进行尺寸归一化,数字居中处理,固定尺寸为 28×28。
Training set images: train-images-idx3-ubyte.gz (9.45MB, 包含60,000个样本)
Training set labels: train-labels-idx1-ubyte.gz (28.2KB, 包含60,000个标签)
Test set images: t10k-images-idx3-ubyte.gz (1.57MB, 包含10,000个样本)
Test set labels: t10k-labels-idx1-ubyte.gz (4.43KB, 包含10,000个标签)
MNIST数据集来自美国国家标准与技术研究所,National Institute of Standards and Technology (NIST)。训练集(training set)由来自250个不同人手写的数字构成,其中50%是高中学生,50%来自人口普查局(the Census Bureau)的工作人员。测试集(test set)也是同样比例的手写数字数据。
MNIST也可以通过在caffe目录下执行下面脚本获取:
./data/mnist/get_mnist.sh
下载到的原始数据为二进制文件,通过执行下面脚本可以将二进制数据,生成LMDB格式数据:
./examples/mnist/create_mnist.sh
执行后,会生成examples/mnist/mnist_train_lmdb/和examples/mnist/mnist_test_lmdb/ 这两个目录。每个目录下都有两个文件:data.mdb和lock.mdb。

LMDB数据库(Lightning Memory-Mapped Database)
LMDB和SQLite/MySQL等关系型数据库不同,属于key-value数据库(把LMDB想成dict会比较容易理解),键key与值value都是字符串。
文件结构简单,一个文件夹,里面一个数据文件,一个锁文件。数据随意复制,随意传输。它的访问简单,不需要运行单独的数据管理进程。只要在访问的代码里引用 LMDB 库,访问时给文件路径即可。
1、Python环境下使用LMDB:
pip install lmdb
使用时,import lmdb调用
2、LMDB基本操作流程:
env = lmdb.open() # 打开环境
txn = env.begin() # 建立事务
txn.put(key, value) # 进行插入和修改
txn.delete(key) # 进行删除
txn.get(key) # 进行查询
txn.cursor() # 进行遍历
txn.commit() # 提交更改
测试示例见:bu5/bu5project/LMDB-lwp/lmdb_test.py
3、实际操作
(1)lmdb转image和label
对MNIST数据集转换得到的lmdb文件进行解析,得到image和label。
脚本见lmdb_to_image_label.py,运行脚本对MNIST进行解析,并将图片按label命名并分别存放或者存放在一个文件夹。
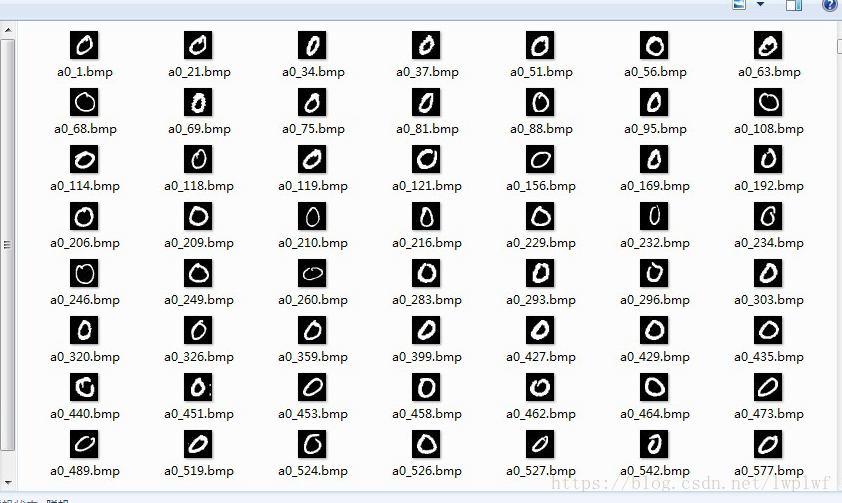
(2)Image 和label转lmdb
脚本见create_lmdb_and_filelist.py脚本根据实际数据灵活修改,目前脚本针对MNIST数据集。
脚本同时也生成了图片和label列表清单txt文件,在生成lmdb时会用到。

转换测试:
对生成的lmdb文件,使用3(1)中的方法再次进行转换,查看结果:
经测试,格式转换可复原数据。
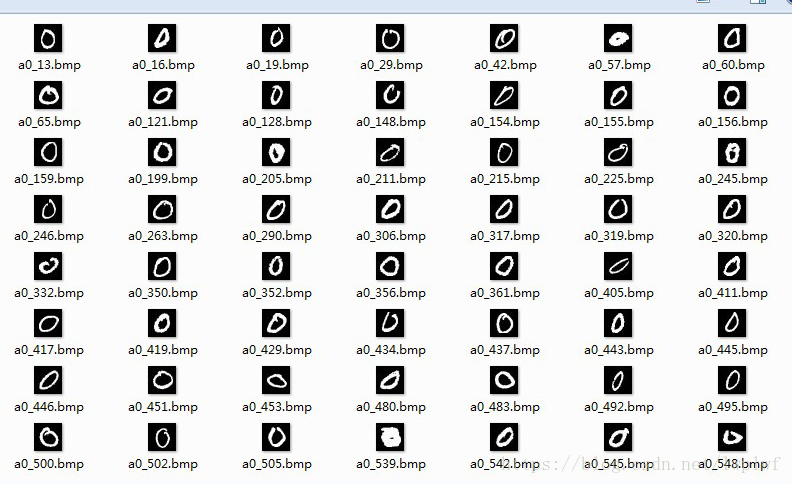

















 9570
9570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









