







目录
一、正则表达式
1. 概念
正则表达式,又称规则表达式。(英语:Regular Expression),在代码中常简写为 regex、regexp 或 RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模
式(规则)的文本。
正则表达式不只有一种,而且 LINUX 中不同的程序可能会使用不同的正则表达式,如:
工具:grep sed awk egrep
正则表达式---通常用于判断语句中,用来检查某一字符串是否满足某一格式。
正则表达式是由普通字符与元字符组成:
- 普通字符包括大小写字母、数字、标点符号及一些其他符号
- 元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式
2. grep 命令
格式:grep [选项]… 查找条件 目标文件
| -E | 开启扩展(Extend)的正则表达式,需要输入-E,否则无法索取数据;egrep自动开启正则表达式 |
| -c | 计算找到 '搜寻字符串' 的次数 |
| -i | 忽略大小写的不同,所有大小写视为相同 |
| -o | 只显示被模式匹配到的字符串 |
| -v | 反向选择,亦即显示出没有 '搜寻字符串' 内容的那一行!(反向查找,输出与查找条件不相符的行) |
| --color=auto | 可以将找到的关键词部分加上颜色的显示 |
| -n | 顺便输出行号 |
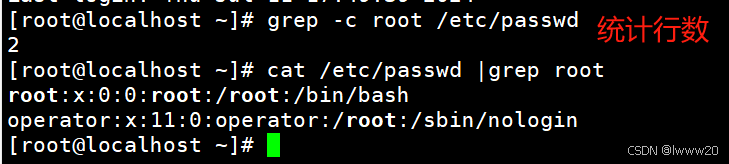
案例1:grep -c root /etc/passwd //统计root字符总行数;或cat /etc/passwd | grep root
案例2:grep -i "the" lianxi.txt //不区分大小写查找the所有的行

案例3:grep -v root /etc/passwd 或cat /etc/passwd |grep -v root //将/etc/passwd,将没有出现 root 的行取出来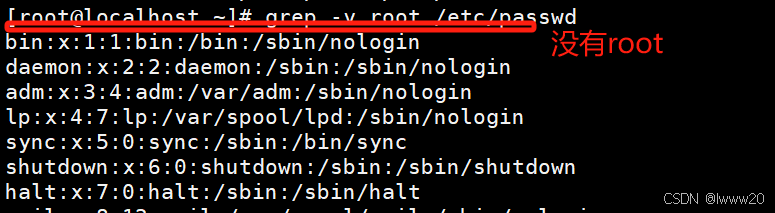
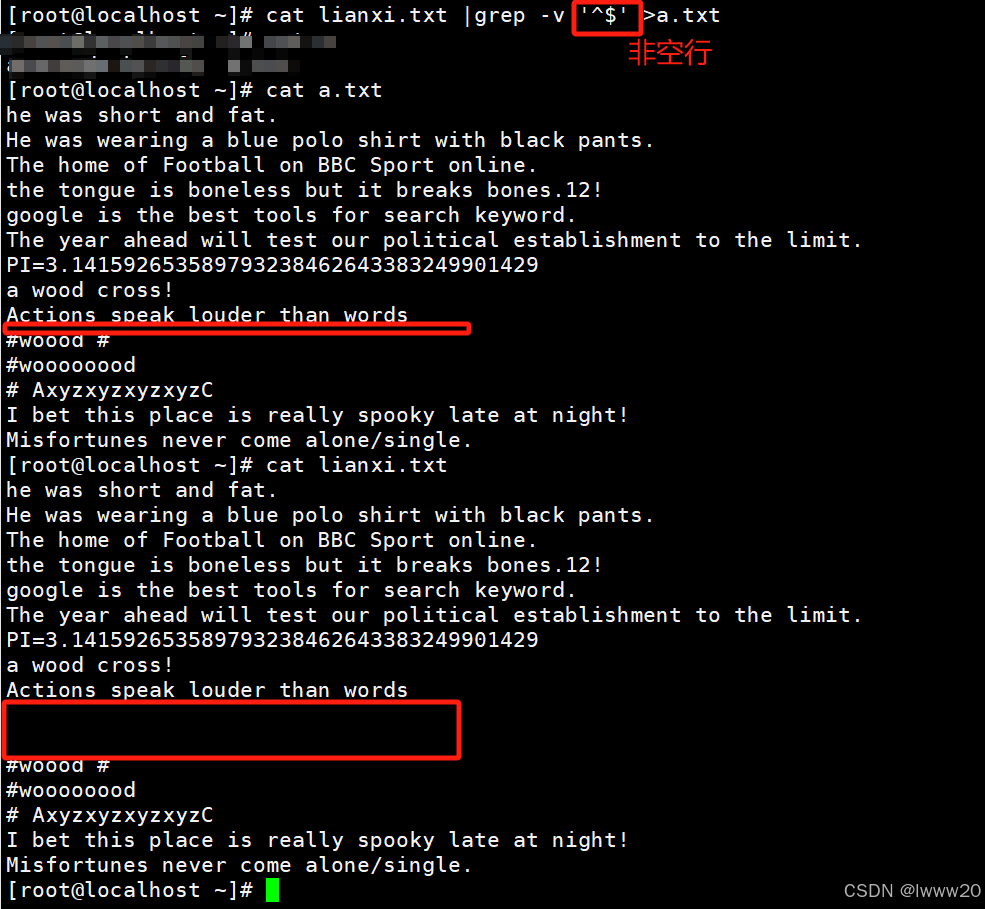
案例4:cat web.sh |grep -v '^$' >test.txt //将非空行写入到test.txt文件
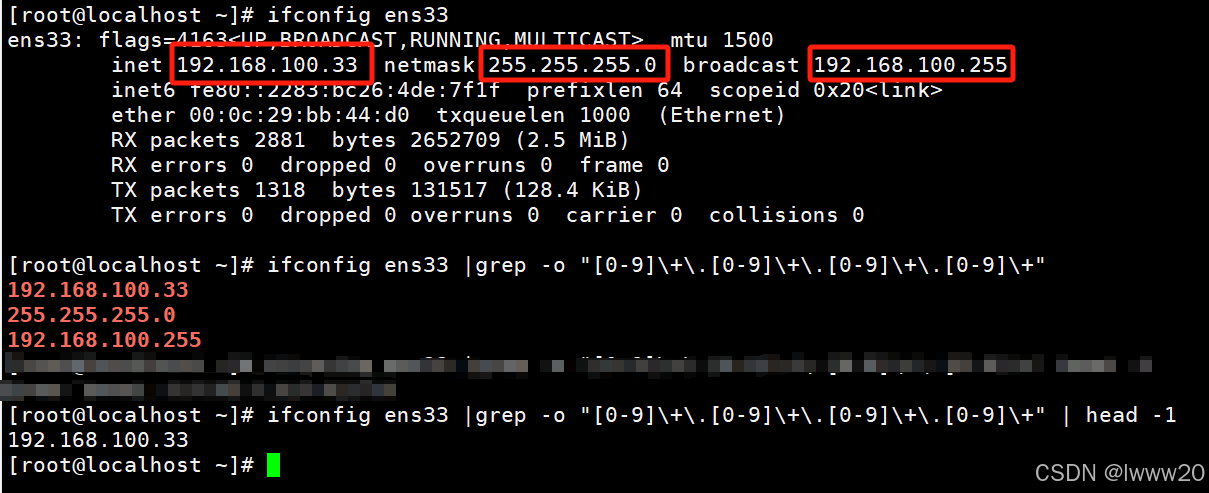
案例5:ifconfig ens33 |grep -o "[0-9]\+\.[0-9]\+\.[0-9]\+\.[0-9]\+"|head -1 //过滤出IP
3. 基础正则表达式常见元字符
(支持的工具:grep、egrep、sed、awk)
特殊字符:
| \ | 转义符,将特殊字符进行转义,忽略其特殊意义a\.b匹配a.b,但不能匹配ajb,.被转义为特殊意义 |
| ^ | 匹配行首,^则是匹配字符串的开始^tux匹配以tux开头的行 |
| $ | 匹配行尾,$则是匹配字符串的结尾tux$匹配以tux结尾的行 |
| . | 匹配除换行符\r\n之外的任意单个字符 |
| \+ | 匹配 list 列表中的一个字符 #匹配其前面的字符出现最少1次,即:肯定有且 >=1 次; |
| [list] | 匹配list列表中的一个字符 例: go[ola]d,[abc]、[a-z]、[a-z0-9] |
| [^list] | 匹配任意不在list列表中的一个字符 例: [^a-z]、[^0-9]、[^A-Z0-9] |
| * | 匹配前面子表达式0次或者多次 例:goo*d、go.*d |
| \{n\} | 匹配前面的子表达式n次,例:go\{2\}d、'[O-9]\{2\}'匹配两位数字 |
| \{n,\} | 匹配前面的子表达式不少于n次,例: go\{2,\}d、' [0-9]\{2,\}'匹配两位及两位以上数宁 |
| \{n,m\} | 匹配前面的子表达式n到m次,例: go\{2,3\)d、'[0-9]\{2,3\}'匹配两位到三位数字 注: egrep、awk使用{n}、{n, }、{n, m}匹配时“{}"前不用加"\” |

注:egrep、awk使用{n}、{n, }、{n, m}匹配时 “{}" 前不用
egrep -E -n 'wo{2}d' test.txt //-E 用于显示文件中符合条件的字符
egrep -E -n 'wo{2,3}d' test.txt

定位符:
| ^ | 匹配输入字符串开始的位置 |
| $ | 匹配输入字符串结尾的位置 |
非打印字符:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1378
1378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









