







Python基础
1.第一个Python程序
- 创建01-HelloPython.py文件
- 编辑文件
print("hello python")
print("hello world")
- 使用cmd进入文件所在目录,使用命令执行Python文件
python 01-HelloPython.py
- cmd窗口打印出文本

1.1 注意事项
同行错误
多条print语句写到同一行
print("hello world")print("hello pythone")
出现的错误
File "D:\桌面\Python-test\01-HelloPython.py", line 1
print("hello python")print("你好,世界")
^
SyntaxError: invalid syntax
语法错误:语法无效
每行代码负责完成一个动作
缩进错误
第二条语句开头多打几个空格
print("hello world")
pring("hello python")
出现的错误
File "D:\桌面\Python-test\01-HelloPython.py", line 2
print("你好,世界")
IndentationError: unexpected indent
缩进错误:不期望出现的缩进
格式严格
2.交互式执行python
- 打开cmd,输入python命令回车进入python的shell
python
- 输入print函数回车执行
>>> print("hello python")
hello python
- 退出输入exit()
>>> exit()
适合验证少量的代码
2.1 ipython
安装
在电脑安装过python后,使用cmd命令安装
pip install ipython
特点
- IPython是python的交互式shell
- 支持自动补全
- 自动缩进
- 内置bash shell,支持linux命令
- 内置很多有用的功能和函数
- IPython是基于BSD开源的
1> 输入exit退出
exit
2> 使用ctrl+d退出
在ipython中只用热键退出会询问是否退出
In [1]:
Do you really want to exit ([y]/n)?
3.pycharm
3.1 创建项目
-
双击打开pycharm,选择New Project
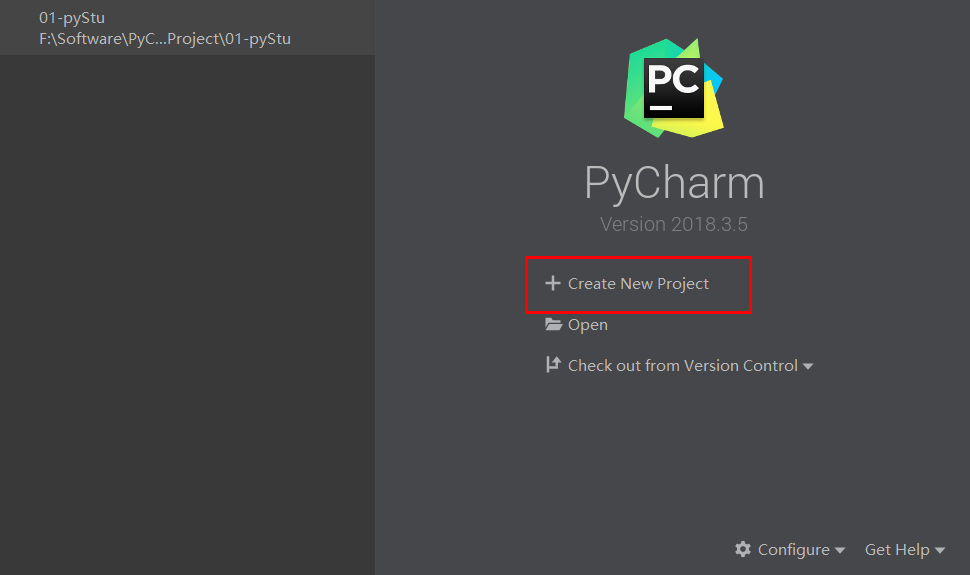
-
选择Pure Python,在location中选择项目的路径,勾选Existing interpreter,选择对应的解释器版本,点击Create即可创建一个python项目。
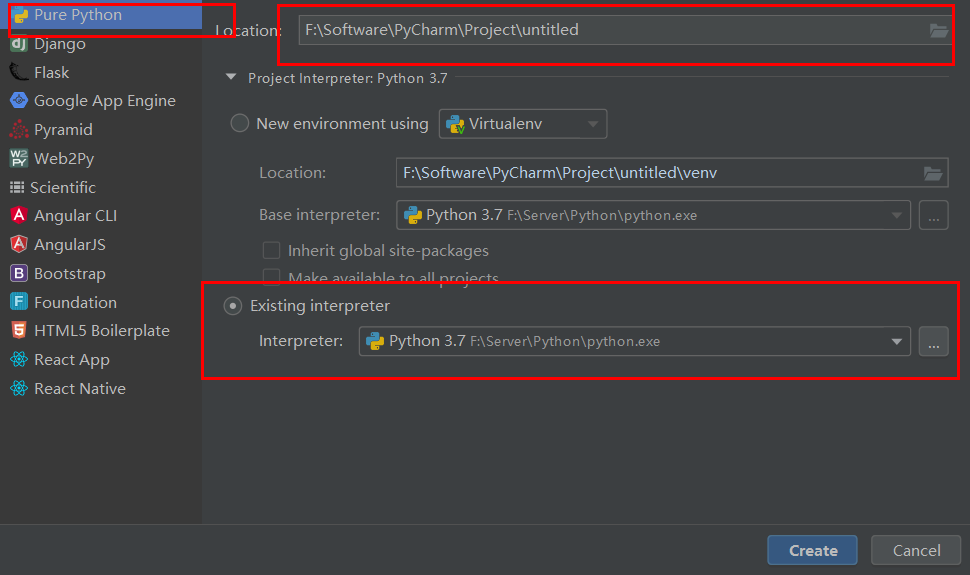
3.2 更换解释器版本
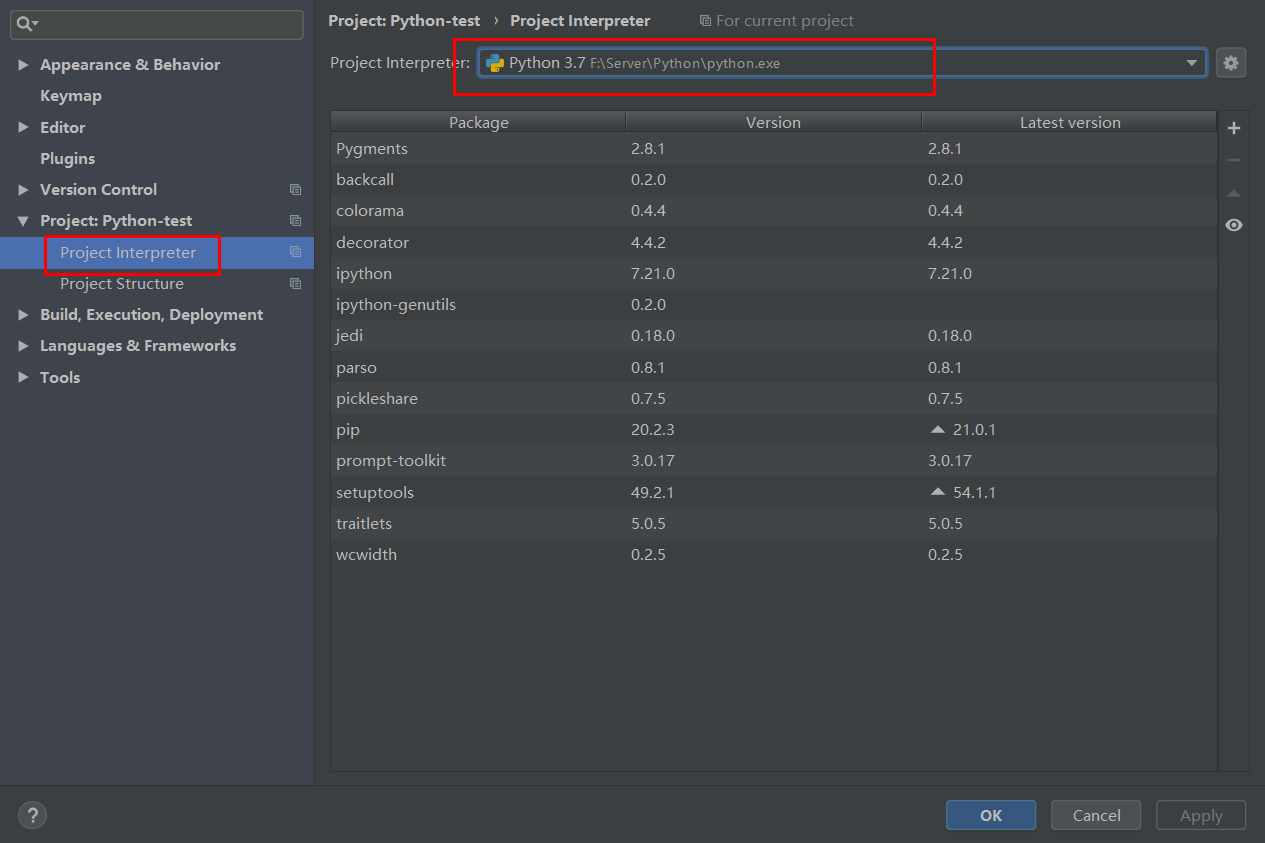
选择左上角的File→Settings→Project:项目名→Project Interpreter在下拉窗口中可选择对应的解释器版本
4.注释
4.1 单行注释
可使用使用快捷键ctrl+l
# 注释内容(注意#和注释内容间要空格)
4.2 多行注释
"""
注释1
注释2
注释3
...
"""
'''
注释1
注释2
注释3
...
'''
5.变量
变量就是一个储存数据的时候当前数据所在的内存地址的名字而已。
5.1 定义变量
变量名 = 值
变量名自定义,要满足标识符命名规则
5.1.1 标识符
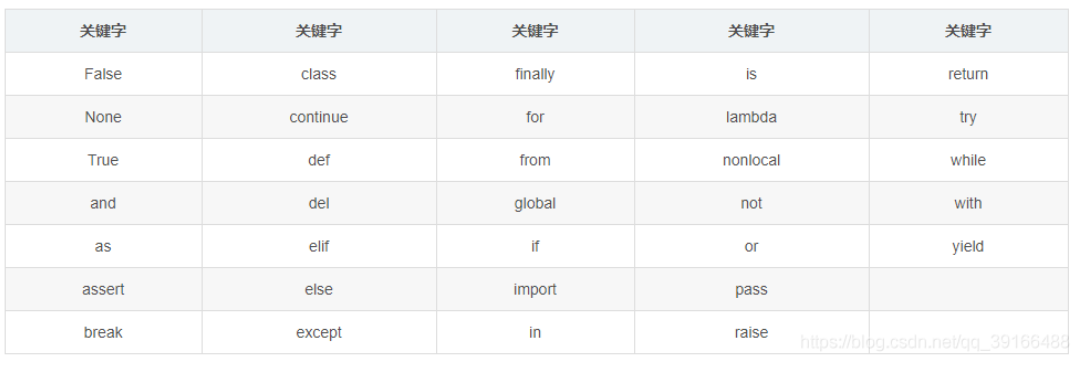
标识符规则:
- 由数字,字母,下划线组成
- 不能数字开头
- 不能使用内置关键字
- 严格区分大小写
关键字:
5.1.2 命名习惯
- 见名知义
- 大驼峰:首字母大写
- 小驼峰:第二个单词开始首字母大写
- 下划线
5.2 使用变量
my_name = "lyx"
print(my_name)
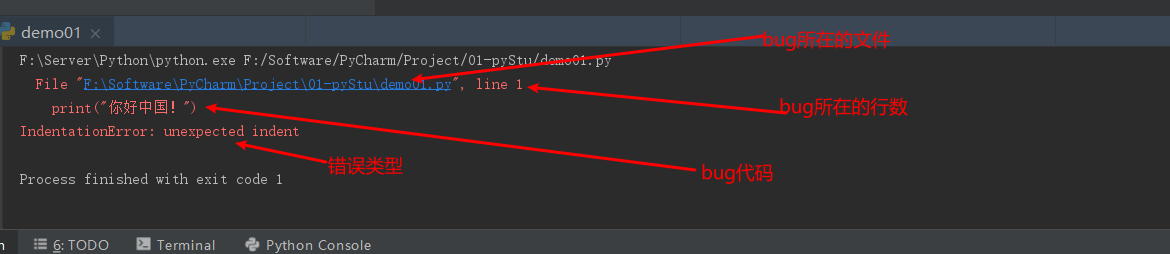
6.认识Bug
6.1 bug提示
7.Debug工具
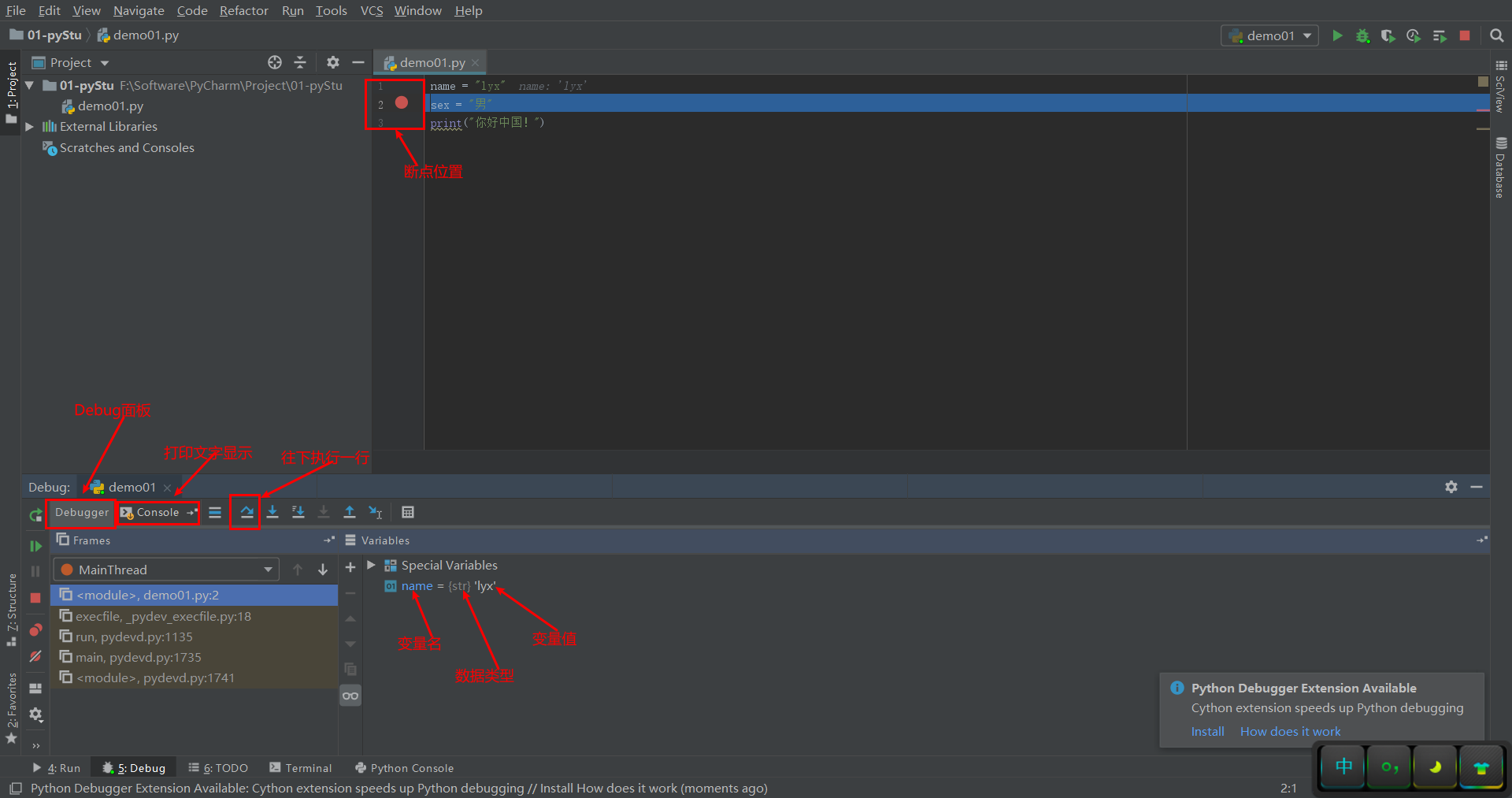
Debug是工具pycharm IDE中集成用来调试程序的工具,在这里程序员可以查看程序执行细节和流程或者调试bug。
Debug工具使用步骤:
- 打断点
- Debug调试
7.1 打断点
- 断点位置:目标要调试的代码块的第一行代码即可
- 打断点方法:单击目标代码行左侧空白位置
8.数据类型
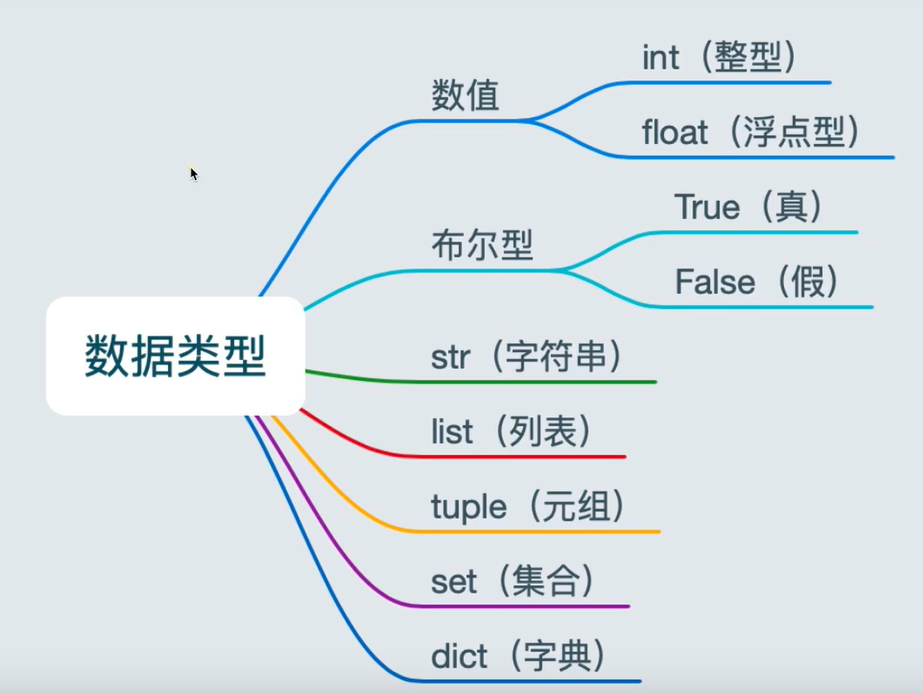
8.1 数据类型的表示
# int -- 整型
num1 = 1
# float -- 浮点型
num2 = 1.1
# bool -- 布尔型
num3 = True
num4 = False
# str -- 字符串
num5 = "hello world"
# list -- 列表
num6 = [1, 22, 44, 66, 88]
# tuple -- 元组
num7 = (1, 22, 33, 44, 66)
# set -- 集合
num8 = {1, 22, 33, 44, 66}
# dict -- 字典
num9 = {"name": "lyx", "age": "22"}
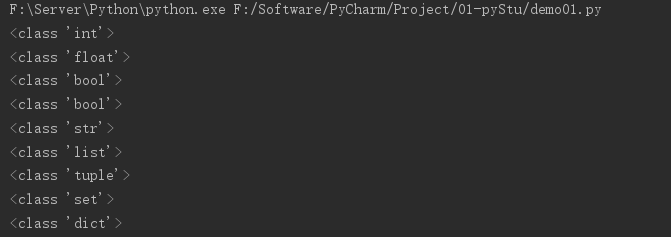
# 验证类型,使用type函数返回数据类型
print(type(num1))
print(type(num2))
print(type(num3))
print(type(num4))
print(type(num5))
print(type(num6))
print(type(num7))
print(type(num8))
print(type(num9))
运行结果:
9.输出
目标
- 格式化输出
- 格式化符号
- f-字符串
- format
- print的结束符
9.1 格式化输出
9.1.1 格式化符号
| 格式化符号 | 转换 |
|---|---|
| %s | 字符串 |
| %d | 有符号的十进制整数 |
| %f | 浮点数 |
| %c | 字符 |
| %u | 无符号的十进制整数 |
| %o | 八进制整数 |
| %x | 十六进制整数(小写ox) |
| %X | 十六进制整数(大写OX) |
| %e | 科学计数法(小写e) |
| %E | 科学计数法(大写e) |
| %g | %f和%e的简写 |
| %G | %f和%E的简写 |
9.1.2 格式化符号的使用
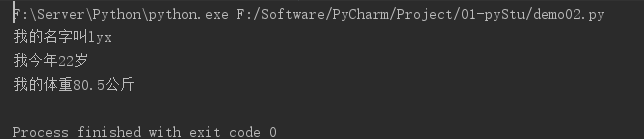
name = "lyx"
age = 22
weight = 80.5
# 输出:我的名字叫x
print("我的名字叫%s" % name)
# 输出:我今年x岁
print("我今年%d岁" % age)
# 输出:我的体重x公斤 (其中%.1f表示保留小数点后1位)
print("我的体重%.1f公斤" % weight)
运行结果:
9.1.3 使用技巧
%06d:表示不足6位则以0补全,超出则原样输出%.3f:表示保留3位小数,不足则以0补全- 同时输出多个数据,用小括号括起来,从左到右用逗号分割
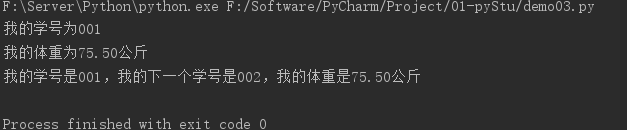
stu_id = 1
weight = 75.5
# 输出:我的学号为001
print("我的学号为%03d" % stu_id)
# 输出:我的体重为75.50公斤
print("我的体重为%.2f公斤" % weight)
# 输出:我的学号是001,我的下一个学号是002,我的体重是75.50公斤
print("我的学号是%03d,我的下一个学号是%03d,我的体重是%.2f公斤" % (stu_id, stu_id + 1, weight))
输出结果:
9.1.4使用%s输出各种类型数据
非字符串型数据也可以用%s来输出
name = "lyx"
age = 18
weight = 75.5
# 输出:我的名字x,我的年龄x,我的体重x
print("我的名字%s,我的年龄%s,我的体重%s" % (name, age, weight))
输出结果:

9.2 f格式化字符串
优点:
- 代码量少
- 更高效
语法:
f"{表达式}"
name = "lyx"
age = 18
weight = 75.5
# 输出:我的名字x,我的年龄x,我的体重x
print(f"我的名字{name},我的年龄{age}岁,明年我{age + 1}岁,我的体重{weight}")
输出结果:

9.3 format格式化字符串
name = "lyx"
age = 18
weight = 75.5
# 输出:我的名字x,我的年龄x,我的体重x
print("我的名字{},我的年龄{}岁,我的体重{}".format(name, age, weight))
运行结果:

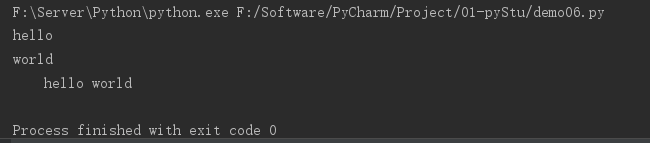
9.4 转义字符
\n:换行\t:制表符
print("hello\nworld")
print("\thello world")
输出结果:
9.5 结束符
print()函数默认结束符为:end="\n",所以省略不写结束符时print()函数默认换行。
end中也可以写自定义的结束符
print("hello", end="\t")
print("world", end="\n\t")
print("hello", end="***")
print("python", end="\n")
输出结果:

10.输入
10.1 语法
input("提示信息")
10.2 特点
- 当程序执行到
input,会等待用户输入完成后继续执行 - 在python中,
input接收用户输入后,一般存储到变量,方便使用 - 在python中,
input会把接收到的任意用户输入的数据都当做字符串处理
10.3 输入功能实现
password = input("请输入密码:")
print(f"您的密码是{passowrd}")
print(type(password))
输出结果:

11.转换数据类型
11.1 转换数据类型的函数
| 函数 | 实例 | 说明 |
|---|---|---|
| int(x [,base]) | int(“8”) | 可以转换的包括String类型和其他数字类型,但是会丢失精度 |
| float(x) | float(1)或者float(“1”) | 可以转换String和其他数字类型,不足的位数用0补齐,例如1会变成1.0 |
| complex(real ,imag) | complex(“1”)或者complex(1,2) | 第一个参数可以是String或者数字,第二个参数只能为数字类型,第二个参数没有时默认为0 |
| str(x) | str(1) | 将数字转化为String |
| repr(x) | repr(Object) | 返回一个对象的String格式 |
| eval(str) | eval(“12+23”) | 执行一个字符串表达式,返回计算的结果,如例子中返回35 |
| tuple(seq) | tuple((1,2,3,4)) | 参数可以是元组、列表或者字典,wie字典时,返回字典的key组成的集合 |
| list(s) | list((1,2,3,4)) | 将序列转变成一个列表,参数可为元组、字典、列表,为字典时,返回字典的key组成的集合 |
| set(s) | set([‘b’, ‘r’, ‘u’, ‘o’, ‘n’])或者set(“asdfg”) | 将一个可以迭代对象转变为可变集合,并且去重复,返回结果可以用来计算差集x - y、并集x | y、交集x & y |
| frozenset(s) | frozenset([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) | 将一个可迭代对象转变成不可变集合,参数为元组、字典、列表等, |
| chr(x) | chr(0x30) | chr()用一个范围在 range(256)内的(就是0~255)整数作参数,返回一个对应的字符。返回值是当前整数对应的ascii字符。 |
| ord(x) | ord(‘a’) | 返回对应的 ASCII 数值,或者 Unicode 数值 |
| hex(x) | hex(12) | 把一个整数转换为十六进制字符串 |
| oct(x) | oct(12) | 把一个整数转换为八进制字符串 |
| bin(x) | bin(15) | 把一个整数转换为二进制字符串 |
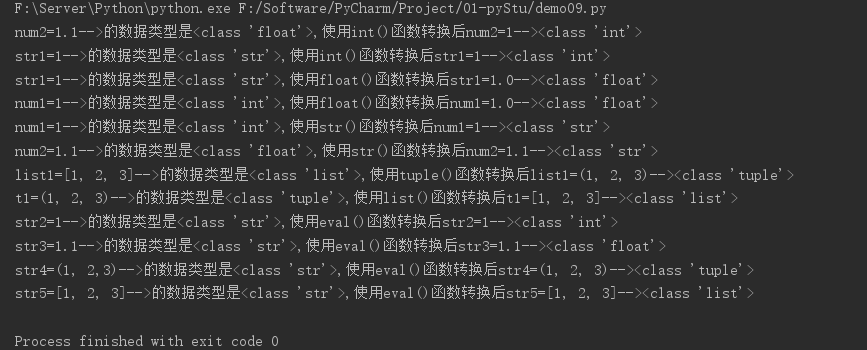
重点函数使用方法示例:
num1 = 1
num2 = 1.1
str1 = "1"
list1 = [1, 2, 3]
t1 = (1, 2, 3)
# 使用int()函数转换
print(f"num2={num2}-->的数据类型是{type(num2)},使用int()函数转换后num2={int(num2)}-->{type(int(num2))}")
print(f"str1={str1}-->的数据类型是{type(str1)},使用int()函数转换后str1={int(str1)}-->{type(int(str1))}")
# 使用float()函数转换
print(f"str1={str1}-->的数据类型是{type(str1)},使用float()函数转换后str1={float(str1)}-->{type(float(str1))}")
print(f"num1={num1}-->的数据类型是{type(num1)},使用float()函数转换后num1={float(num1)}-->{type(float(num1))}")
# 使用str()函数转换
print(f"num1={num1}-->的数据类型是{type(num1)},使用str()函数转换后num1={str(num1)}-->{type(str(num1))}")
print(f"num2={num2}-->的数据类型是{type(num2)},使用str()函数转换后num2={str(num2)}-->{type(str(num2))}")
# 使用tuple()函数转换
print(f"list1={list1}-->的数据类型是{type(list1)},使用tuple()函数转换后list1={tuple(list1)}-->{type(tuple(list1))}")
# 使用list()函数转换
print(f"t1={t1}-->的数据类型是{type(t1)},使用list()函数转换后t1={list(t1)}-->{type(list(t1))}")
# 使用eval()函数转换(键字符串中的数据转换成原本的数据类型)
str2 = "1"
str3 = "1.1"
str4 = "(1, 2,3)"
str5 = "[1, 2, 3]"
print(f"str2={str2}-->的数据类型是{type(str2)},使用eval()函数转换后str2={eval(str2)}-->{type(eval(str2))}")
print(f"str3={str3}-->的数据类型是{type(str3)},使用eval()函数转换后str3={eval(str3)}-->{type(eval(str3))}")
print(f"str4={str4}-->的数据类型是{type(str4)},使用eval()函数转换后str4={eval(str4)}-->{type(eval(str4))}")
print(f"str5={str5}-->的数据类型是{type(str5)},使用eval()函数转换后str5={eval(str5)}-->{type(eval(str5))}")
运行结果:
11.运算符
11.1 运算符分类
- 算数运算符
- 赋值运算符
- 复合赋值运算符
- 比较运算符
- 逻辑运算符
11.2 算数运算符
- 加:
+- 减:
-- 乘:
*- 除:
/- 整除:
//- 取余:
%- 指数:
**(如2**4为,2的四次方)- 小括号:
()提高优先级
优先级:()高于**高于* / // % 高于 + -
11.3 赋值运算符
- 单个变量赋值
a = 10
- 多个变量赋值
name, age, sex = "lyx", 18, "男"
- 多个变量赋相同值
a = b = 10
11.4 复合运算符
| 运算符 | 描述 |
|---|---|
| += | c += a 等价于 c = c+a |
| -= | c -= a 等价于 c = c - a |
| *= | c *= a 等价于 c = c * a |
| /= | c /= a 等价于 c = c / a |
| //= | c //= a 等价于 c = c // a |
| %= | c %= a 等价于 c = c % a |
| **= | c ** = a 等价于 c = c ** a |
注意:有复合运算符时,先算复合运算符后面的表达式
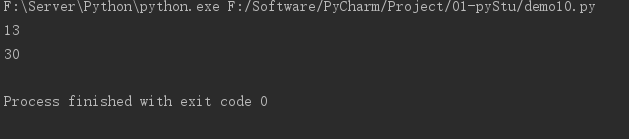
a, b = 10, 10
# a += 1 + 2 等价于 a = a + (1 + 2)
a += 1 + 2
# b *= 1 + 2 等价于 b = b * (1 + 2)
b *= 1 + 2
print(a)
print(b)
运算结果:
11.5 比较运算符
| 运算符 | 描述 |
|---|---|
| == | 比较相等,相等返回True,不想等返回False |
| != | 比价不相等,相等返回False,不想等返回True |
| > | 比较大于,大于返回True,小于等于返回False |
| < | 比较小于,大于等于返回False,小于等于返回True |
| >= | 比较大于等于,大于等于返回True,小于返回False |
| <= | 比较小于等于,大于返回False,小于等于等于返回True |
11.6 逻辑运算符
| 运算符 | 描述 |
|---|---|
| and | x and y ,相当于java中的&& |
| or | x or y,相当于java中的|| |
| not | no x,相当于java中的! |
优先级:
not高于and高于or
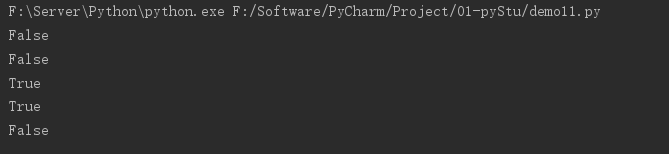
a = True
b = False
print(a and b)
print(b and a)
print(a or b)
print(b or a)
print(not a)
运行结果:
11.7 拓展
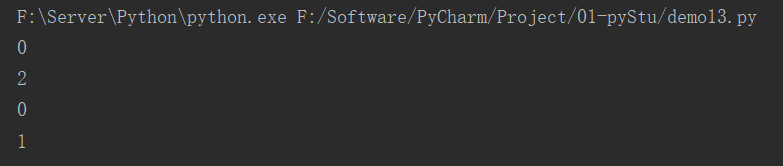
**数字之间的逻辑运算符规律: **
- and逻辑运算符,只要有一个0,结果就为0,否则就返回最后一个非0数字
- or逻辑运算符,只有都为0,结果才是0,否则返回第一个非0数字
print(0 and 1)
print(1 and 2)
print(0 or 0)
print(1 or 2)
运行结果:
12.条件语句
条件符合,则执行某些代码,条件不符合就不执行这些代码。
12.1 if语句
语法:
if 条件:
条件成立执行的代码
....
模拟案例:网吧上网
# 模拟网吧上网,如果用户输入的年龄小于18岁,则赶出网吧,如果用户输入的年龄大于18岁,则可以整除上网
age = int(input("请输入您的年龄:"))
if age >= 18: # 条件成立
print("上机成功!")
else:
print("请退出网吧!")
运行结果:

12.2 if…else…语句
语法:
if 条件:
条件成立执行的代码
....
else:
条件不成立执行的代码
...
12.3 多重判断
语法:
if 条件1:
条件1成立执行的代码
....
elif 条件2:
条件2立执行的代码
...
else:
所有条件都不满足执行的代码
...
模拟案例:网吧上机
"""
模拟用户网吧上机
1.用户输入用户名和密码
2.分别储存用户输入的用户名和密码
3.使用多重判断,验证登录信息
"""
name, pwd = input("请输入用户名:"), input("请输入密码:")
if name != "lyx":
print("您输入的用户名有误,登录失败!")
elif pwd != "888888":
print("您输入的密码有误,登录失败!")
else:
print("登录成功!")
运行结果:

12.4 拓展写法
当在条件中使用and连接同一个变量的判断时可以简化。
如:age >= 16 and age < 18 可化简为:16 <= age < 18
# 判断分数在什么水平
source = float(input("请输入您的分数:"))
if source < 60:
print("不及格")
elif 60 <= source < 80:
print("及格")
elif 80 <= source < 100:
print("优秀")
elif source >= 100:
print("学霸")
运行结果:

12.5 if语句的嵌套
"""
模拟坐公交车
1.有钱可以上车没钱不能上车
2.上车后有座位可以坐,没有空位不能坐
"""
money = 1
seat = 1
if money >= 1:
print("上公交车了!")
if seat >= 1:
print("有座位,可以坐了!")
else:
print("没有座位,只能站着了!")
else:
print("没有钱,无法上车!")
运行结果:

13 随机数
使用方法:
- 导入模块:import 模块名
- 使用:模块名.函数
import random
user = int(input("玩家出拳:"))
computer = random.randint(0, 2)
str1 = "石头"
str2 = "剪刀"
str3 = "布"
result1 = "您赢了"
result2 = "您输了"
result3 = "平局"
if user == 0:
print(f"您出的是{str1}")
if computer == 0:
print(f"电脑出的是{str1}\n{result3}")
elif computer == 1:
print(f"电脑出的是{str2}\n{result1}")
elif computer == 2:
print(f"电脑出的是{str3}\n{result2}")
elif user == 1:
print(f"您出的是{str2}")
if computer == 0:
print(f"电脑出的是{str1}\n{result2}")
elif computer == 1:
print(f"电脑出的是{str2}\n{result3}")
elif computer == 2:
print(f"电脑出的是{str3}\n{result1}")
elif user == 2:
print(f"您出的是{str3}")
if computer == 0:
print(f"电脑出的是{str1}\n{result1}")
elif computer == 1:
print(f"电脑出的是{str2}\n{result2}")
elif computer == 2:
print(f"电脑出的是{str3}\n{result3}")
运行结果:

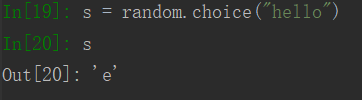
choice():随机选取给定字符串的字符
shuffle():打散数组
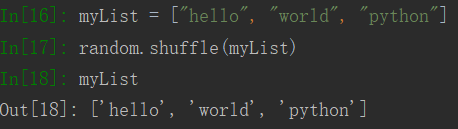
14 三目运算符
简化简单的if…else…表达式
语法:
条件成立的表达式 if 条件 else 条件不成立的表达式
a, b = 10, 15
# 条件成立则返回b-a,条件不成立则返回a-b
print(b-a if a < b else a-b)
运行结果:

13.循环语句
作用:让代码更高效的执行
在Python中循环分为
for循环和while循环两种
13.1 while循环
语法:
while 条件:
条件成立执行代码1
条件成立执行代码2
...
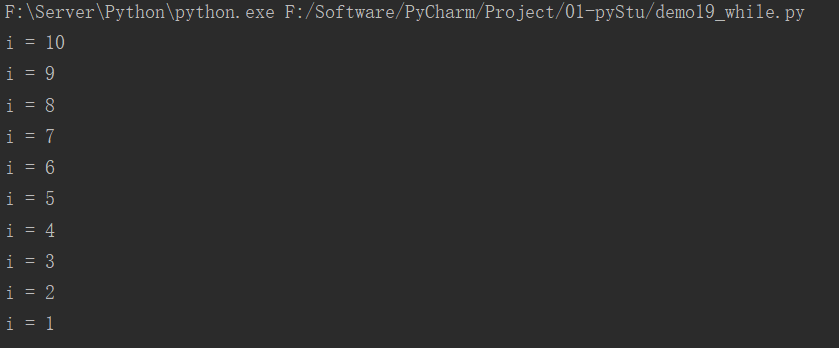
# 计数器
i = 10
while i > 0:
print(f"i = {i}")
i -= 1
运行结果:
13.2 退出循环
break和continue是循环中满足一定条件退出循环的两种方式。
break:终止整个循环
continue:退出当前循环,执行下一次循环
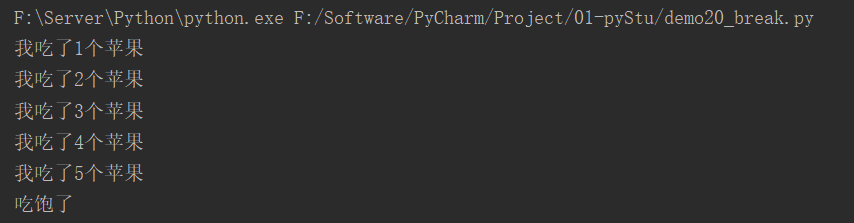
break应用:
i = 0
while True:
i += 1
print(f"我吃了{i}个苹果")
if i >= 5:
print("吃饱了")
break # 终止循环
运行结果:
continue应用:
i = 0
while i <= 10:
i += 1
if i % 2 != 0:
continue
print(i, end="\t")
运行结果:

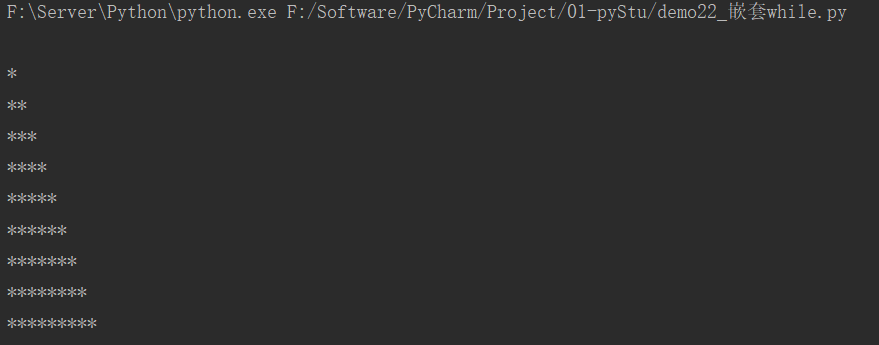
13.3 嵌套while
i = 0
while i < 10:
j = 0
while j < i:
print("*", end="")
j += 1
print() # 用于换行
i += 1
运行结果:
13.4 for循环
语法:
for 临时变量 in 序列:
重复执行的代码1
重复执行的代码2
...
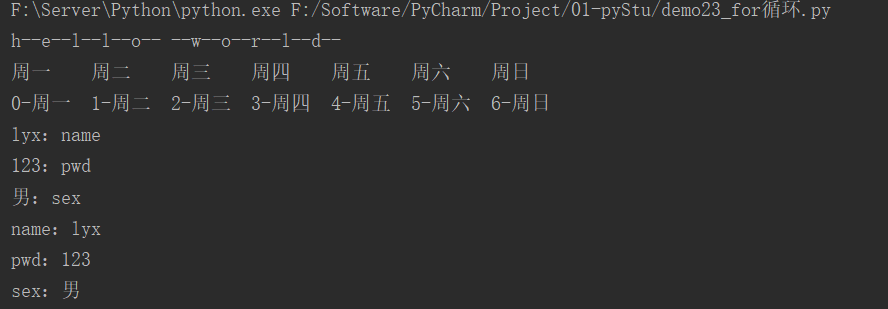
# 遍历字符串,执行流程:x依次表示y中的一个元素,遍历完所有元素循环结束。
str1 = "hello world"
for i in str1:
print(i, end="--")
print()
# 便利列表,可以获取下表,enumerate每次循环可以得到下表及元素
list1 = ["周一", "周二", "周三", "周四", "周五", "周六", "周日"]
for temp in list1:
print(temp, end="\t")
print()
for index, value in enumerate(list1): # 使用enumerate后,index表示数组下标,value表示值
print(f"{index}-{value}", end="\t")
print()
# 便利字典
user = {"name": "lyx", "pwd": "123", "sex": "男"}
for key in user:
print(f"{user.get(key)}:{key}")
for key, value in user.items():
print(f"{key}:{value}")
运行结果:
13.4.1 退出for循环
str1 = "hello world"
# 使用break遇到空格终止循环
for item in str1:
if item == " ":
break
print(item, end="")
print()
# 使用continue遇到空格跳出当前循环
for item in str1:
if item == " ":
continue
print(item, end="")
运行结果:

13.5 循环else
循环可以和else配合使用,else下方缩进的代码指的是当循环正常结束后要执行的代码
- continue,可正常结束循环,for循环的else可正常执行
- break,非正常结束循环,for循环的else不可执行
- 程序异常,非正常结束,for循环后的else不可执行
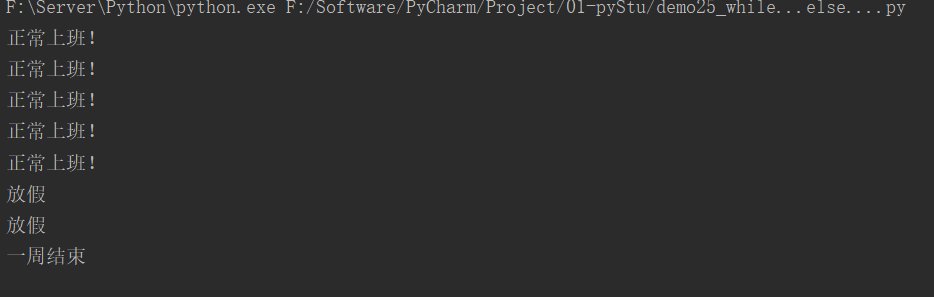
13.5.1 while…else…
i = 0
while i < 7:
i += 1
if i < 6:
print("正常上班!")
else:
print("放假")
# continue,可正常结束循环,for循环的else可正常执行
# break,非正常结束循环,for循环的else不可执行
# 1 / 0,模拟程序异常,非正常结束,for循环后的else不可执行
else:
print("一周结束")
运行结果:
13.5.2 for…else…
str1 = "hello world"
for item in str1:
if item == " ":
continue
# continue,可正常结束循环,for循环的else可正常执行
# break,非正常结束循环,for循环的else不可执行
# 1 / 0,模拟程序异常,非正常结束,for循环后的else不可执行
print(item, end="")
else:
print("结束程序")
运行结果:

14.字符串
字符串是python中最常用的数据类型。我们一般使用引号来创建字符串。字符串常见很简单,只要为变量分配一个值即可。
# 单引号和双引号,不支持换行书写
str1 = 'hello'
str2 = 'world'
print(type(str1))
# 三引号,支持换行书写
str3 = '''hello
world'''
str4 = """world"""
print(str3, type(str3))
运行结果:

14.1 下标
下标又叫索引,字符串从左到右给每一个字符都分配了一个下标。
str1 = 'hello world'
i = 0
while i < 11:
print(str1[i], end="---")
i += 1
运行结果:
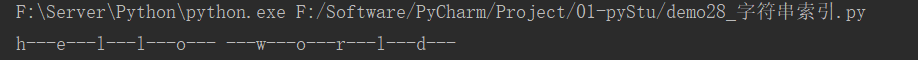
14.2 切片
切片是指对操作对象截取其中一部分的操作。字符串,列表,元组都支持切片操作。
语法:
序列[开始位置下标:结束位置下标:步长]
注意:
- 不包含结束位置下标对应的数据,正负整数均可
- 步长是选取间隔,正负整数均可,默认步长为1
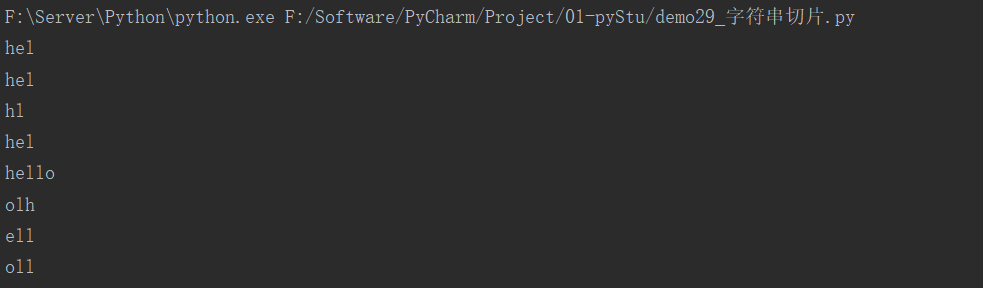
str1 = "hello"
print(str1[0:3])
print(str1[0:3:1])
print(str1[0:4:2])
print(str1[:3:1]) # 如果开始下标没有写,默认从0开始
print(str1[0::1]) # 如果结束下标没有写,默认到最后一个字符
print(str1[::-2]) # 步长负数表示从后往前数,步长和下标不能同时为负
print(str1[-4:-1:1]) # 下标负数表示从后往前,-1表示最后一个
print(str1[-1:-4:-1])
运行结果:
注意:
- 开始和结束下标构成的选取顺序必须和步长正负代表的选取顺序相同。
- 如:str1[-4 : -1 : -1],开始下标-4到结束下标-1,表示从左往右的顺序,而步长-1表示从右往左,选取的顺序不一致,无法选取。
14.3 常用方法
14.3.1 查找
find():检测某个子串是否包含在这个字符串中,如果在返回这个子串开始的位置下标,否则则返回-1rfind():功能和find()相同,当查找方向从右侧开始index():检测子串是否包含在这个字符串中,如果在返回这个子串开始的位置下标,否则报异常。rindex():功能和index()相同,当查找方向从右侧开始count():返回某个子串在字符串中出现的次数
语法:
字符串序列.find(子串,开始位置下标,结束位置下标) # 开始下标和结束下标可以省略,表示在整个字符串中查找
字符串序列.index(子串,开始位置下标,结束位置下标)
字符串序列.count(子串,开始位置下标,结束位置下标)
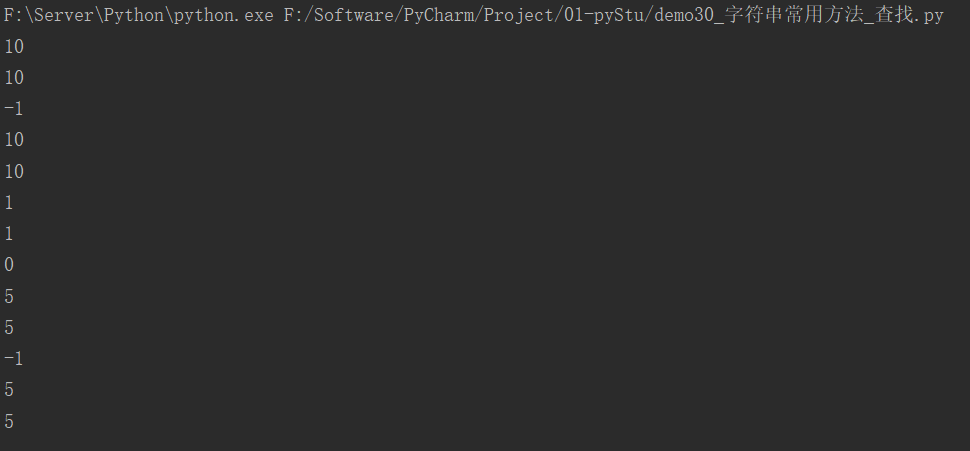
myStr = "good good study day day up"
# find()
print(myStr.find("study"))
print(myStr.find("study", 8, 20))
print(myStr.find("hello"))
# index()
print(myStr.index("study"))
print(myStr.index("study", 8, 20))
# print(myStr.index("hello")) # 报错 ValueError: substring not found
# count()
print(myStr.count("study"))
print(myStr.count("study", 8, 20))
print(myStr.count("hello"))
# rfind()
print(myStr.rfind("good"))
print(myStr.rfind("good", 0, 20))
print(myStr.rfind("hello"))
# rindex
print(myStr.rindex("good"))
print(myStr.rindex("good", 0, 20))
# print(myStr.rindex("hello")) # 报错 ValueError: substring not found
运行结果:
14.3.2 修改
-
replace():替换语法:
字符串序列.replace(旧子串, 新子串, 替换次数)
注意:
- 原变量不变,需要重新定义变量接收。
- 替换次数如果超出子串出现次数,则替换次数为该子串出现的次数
- 字符串是不可变数据类型
split():分割
语法:
字符串序列.split(分割字符, 分割次数)
join:将一个字符或子串合并成一个新的字符串
语法:
字符或子串.join(多字符串组成的序列)
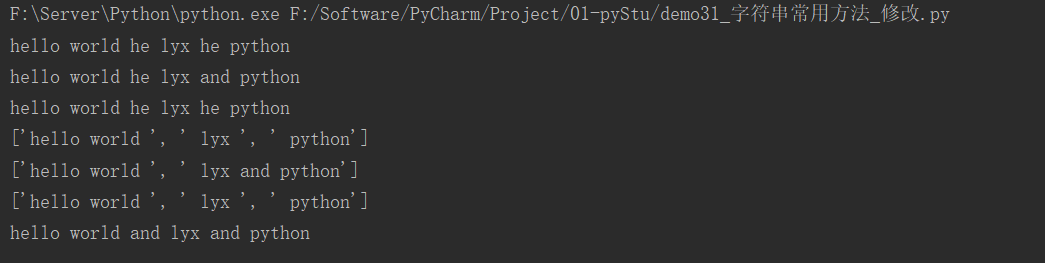
快速体验:
myStr = "hello world and lyx and python"
# replace
str1 = myStr.replace("and", "he", 5)
str2 = myStr.replace("and", "he", 1)
str3 = myStr.replace("and", "he")
print(str1)
print(str2)
print(str3)
# split
str4 = myStr.split("and", 3)
str5 = myStr.split("and", 1)
str6 = myStr.split("and")
print(str4)
print(str5)
print(str6)
# join
myStr = str6
new_str = "and".join(myStr)
print(new_str)
运行结果:
14.3.2.1 大小写转换
capitalize():将字符串第一个字符串转换成大写,其他字符串大写会改成小写title():将字符串每个单词首字母转换成大写,其他字母大写会改成小写lower():将字符串中所有大写转小写upper():将字符串中所有小写转大写
快速体验:
myStr = "hello world and LYX and Python"
print(myStr.capitalize())
print(myStr.title())
print(myStr.lower())
print(myStr.upper())
运行结果:

14.3.2.2 删除
lstrip():删除字符串左侧空白字符rstrip():删除字符串右侧空白字符strip():删除字符串两侧字符
快速体验:
myStr = " hello world "
print(f"{myStr.lstrip()}|")
print(f"{myStr.rstrip()}|")
print(f"{myStr.split()}|")
运行结果:

14.3.2.3 对齐
- ljust():返回一个原字符串左对齐,并使用指定字符串(默认空格)填充至对应的长度的新字符串
- rjust():返回一个原字符串左对齐,并使用指定字符串(默认空格)填充至对应的长度的新字符串
- center():返回一个原字符串居中对齐,并使用指定字符串(默认空格)填充至对应的长度的新字符串
快速体验:
"""
注意:
1.若不给定字符,则默认空格填充
2.若给定的长度没有字符长度长,则不发生对齐
"""
myStr = "hello world"
print(myStr.ljust(20, "*"))
print(myStr.rjust(20, " "))
print(myStr.center(20))
运行结果:

14.3.3 判断
所谓判断即是判断真假,返回的结果是布尔型数据:True或False。
startswitch():检查字符串是否以指定子串开头,是则返回True,否则返回False。如果设置开始和结束位置的下标,则在指定范围内检查。endswitch():检查字符串是否以指定子串结尾,是则返回True,否则返回False。如果设置开始和结束位置的下标,则在指定范围内检查。
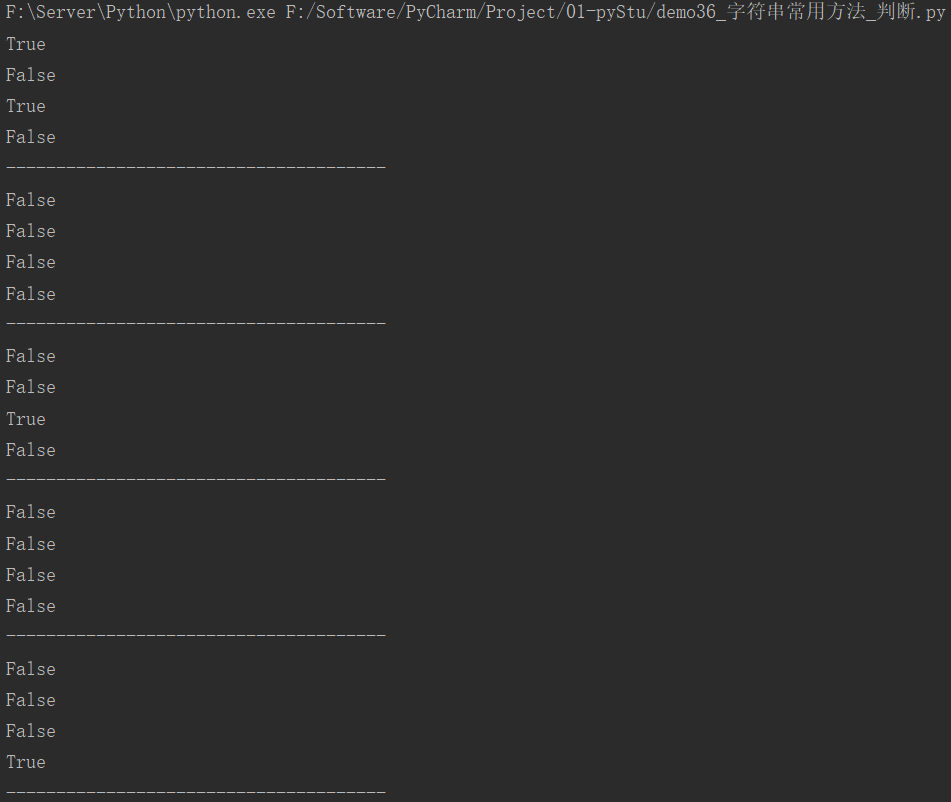
快速体验:
myStr = "hello world and lyx and python"
print(myStr.startswith("hello"))
print(myStr.endswith("python"))
print(myStr.startswith("hello", 3, 8))
print(myStr.endswith("python", 5, 9))
运行结果:

其他判断:
isalpha():如果字符串至少有一个字符并且所有字符都是字母则返回True,否则返回Falseisdigit():如果字符串只包含数字则返回True否则返回Falseisalnum():如果字符串至少有一个字符并且所有字符都是字母或数字则返回True,否则返回Falseisspace():如果字符串中只包含空白,则返回True,否则返回False
快速体验:
strList = ["hello", "hello world", "hello123", "hello123*", " "]
for item in strList:
print(item.isalpha())
print(item.isdigit())
print(item.isalnum())
print(item.isspace())
print("--------------------------------------")
运行结果:
15.列表
列表格式:
[数据1, 数据2, 数据3...]
- 列表可以一次性存储多个数据,且可以是不同类型的。
- 列表是可变序列,可变数据类型
15.1 查找
下标:
name_list = ["gzh", "lyx", "tom"]
print(name_list[0]) # gzh
查找的函数:
index():返回指定数据所在位置的下标count(): 统计指定数据在当前列表中出现的次数len():访问列表长度,即列表中数据个数
语法:
列表序列.index(数据, 开始位置下标, 结束位置下标)
列表序列.count(数据)
len(列表序列)
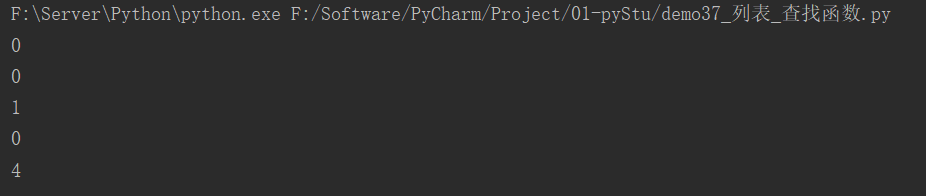
快速体验:
names = ["Tom", "Tony", "Jack", "Lyx"]
# index()
print(names.index("Tom"))
# print(names.index("Sss")) # 如果没有找到则会报错 ValueError: 'Sss' is not in list
print(names.index("Tom", 0, 2))
# count()
print(names.count("Tom"))
print(names.count("Toms"))
# len()
print(len(names))
运行结果:
15.2 判断是否存在
in:判断指定数据在某个列表序列,如果在返回True,否则返回Falsenot int:判断指定数据不在某个列表序列,如果不在返回True,否则返回False
快速体验:
names = ["Tom", "Tony", "Jack", "Lyx"]
# in
print("Lyx" in names)
print("sss" in names)
# not in
print("Lyx" not in names)
print("sss" not in names)
运行结果:

15.3 增加
append():列表结尾追加数据extend():列表结尾追加数据,如果是一个序列,则将这个序列逐一添加到结尾insert():列表指定位置增加数据
语法:
列表序列.append(数据)
列表序列.extend(数据)
列表序列.insert(位置下标,数据)
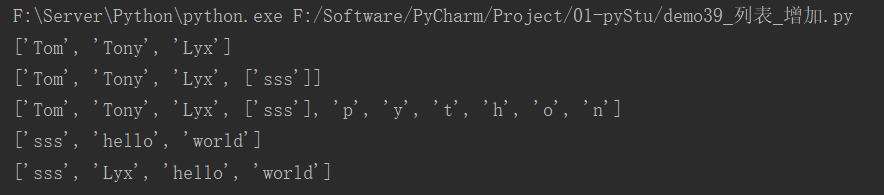
快速体验:
nameList = ["Tom", "Tony"]
nameList2 = ["sss"]
# append()
nameList.append("Lyx")
print(nameList)
nameList.append(nameList2)
print(nameList) # 会将整个列表当成一个数据条件到被添加列表结尾
# extend()
nameList.extend("python")
print(nameList) # 如果是字符串,会将字符串的每一个字符按顺序在结尾添加
nameList2.extend(["hello", "world"])
print(nameList2)
nameList2.insert(1, "Lyx") # 会将数据添加到指定下标位置,原下标位置及后面所有元素下标加1
print(nameList2)
运行结果:
15.4 删除
del:删除整个列表,或指定下标元素pop():删除指定下标的数据(默认最后一个),并返回该数据remove():移除列表中某个数据的第一个匹配项clear():清空列表
语法:
del 列表序列
del 列表序列[下标]
列表序列.pop(下标)
列表数据.remove(数据)
数据列表.clear()
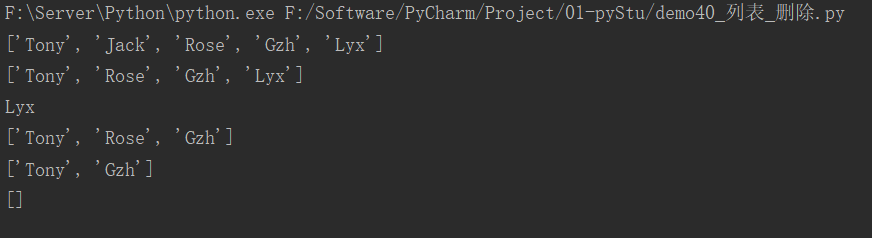
快速体验:
myList = ["Tom", "Tony", "Jack", "Rose", "Gzh", "Lyx"]
# del
# del myList
# print(myList) # 由于myList被删除,系统会报错 NameError: name 'myList' is not defined
del myList[0]
print(myList)
# pop()
myList.pop(1)
print(myList)
print(myList.pop())
print(myList)
# remove()
# myList.remove("Lyx") # 如果数据不存在,则会报错 ValueError: list.remove(x): x not in list
myList.remove("Rose")
print(myList)
# clear()
myList.clear()
print(myList)
运行结果:
15.5 修改
- 修改指定下标数据
reverse():逆置sort():排序
语法:
列表序列[下标] = 数据
列表序列.reverser()
列表序列.sort(key=none, reverse=True) # reverse=True 降序, reverse=False 升序 默认
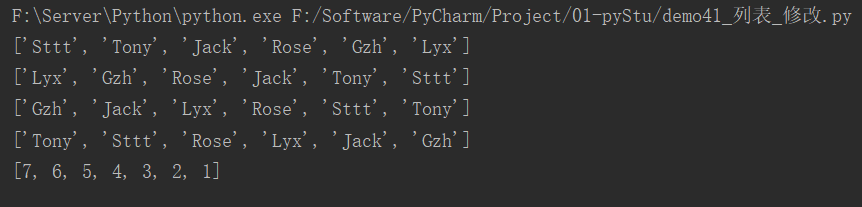
快速体验:
myList = ["Tom", "Tony", "Jack", "Rose", "Gzh", "Lyx"]
# 修改指定下标数据
myList[0] = "Sttt"
print(myList)
# reverse()
myList.reverse()
print(myList)
# sort()
myList.sort() # 按照字母顺序升序排序 默认升序 reverse=False
print(myList)
myList.sort(reverse=True) # 按照字符顺序降序排序
print(myList)
list1 = [1, 2, 3, 4, 5, 6, 7]
list1.sort(reverse=True) # 按照大小顺序降序排序
print(list1)
运行结果:
15.6 复制
copy():复制列表=:复制列表
copy与等号的区别是:等号是将内存地址复制给了变量,属于浅层复制,而copy直接创建了新的内存地址,属于深层复制
语法:
新列表序列 = 列表序列.copy()
新列表序列 = 列表序列
快速体验:
list1 = [1, 2, 3, 4, 5, 6]
list2 = [1, 2, 3, 4, 5, 6]
# =
list3 = list1
list1.pop()
print(list3) # 原值改变,等号复制的新列表也会改变
# copy()
list4 = list2.copy()
list2.pop()
print(list4) # 重新开辟了内存地址,原值改变,复制的新的列表不变
运行结果:

15.7 遍历
15.7.1 while遍历
代码:
name_list = ["Tom", "Jack", "Rose", "Lyx"]
i = 0
while i < len(name_list):
print(name_list[i])
i += 1
运行结果:

15.7.2 for遍历
代码:
name_list = ["Tom", "Jack", "Rose", "Lyx"]
for item in name_list:
print(item)
运行结果:

15.8 列表嵌套
所谓列表嵌套,即一个列表里面包含了其他的子列表。
name_list = [['小明', '小红', '小吕'], ['Tom', "Jack", "Tony"], ['张三'], ['李四'], ['王五']]
快速体验:
name_list = [['小明', '小红', '小吕'], ['Tom', "Jack", "Tony"], ['张三', '李四', '王五']]
print(name_list[0][1])
for item in name_list:
for name in item:
print(name, end="\t")
print()
运行结果:
15.9 综合案例
将8位老师随机分配到3个办公室
代码实现:
import random
teacher = ['Tom', 'Jack', 'Rose', 'Tony', 'Lyx', 'Pink', 'Gzh', 'Lhx']
office = [[], [], []]
i = 0
while i < 8:
name = teacher.pop(random.randint(0, len(teacher)-1))
office_id = random.randint(0, 2)
office[office_id].append(name)
i += 1
print(office)
运行结果:

16.元组
- 可以存储多个数据
- 存储后无法更改
- 定义元组使用小括号,且用逗号隔开各个数据,数据类型可以是不同的
快速体验:
# 多个数据元组定义
t1 = (1, 2, 3)
print(type(t1))
# 单个数据元组定义
t2 = (1,) # 数据结尾要加逗号
print(type(t2))
# 如果数据结尾没有加逗号,则返回的是数据本身的数据类型
t3 = (1)
t4 = ("aaa")
print(type(t3))
print(type(t4))
运行结果:

16.1 查找
- 按下标查找
index():查找某个数据,如果数据存在则返回对应的下标,否则报错,语法和列表,字符串的index方法相同count():统计某个数据在当前元组中出现的次数len():统计元组中数据的个数
快速体验:
t1 = ("aa", "bb", "cc", "dd")
# 通过数组下标查找
print(t1[0])
# print(t1[8]) # 如果下标不存在,则报错 IndexError: tuple index out of range
# index
print(t1.index("aa"))
# print(t1.index("a")) # 如果数据不存在,则报错 ValueError: tuple.index(x): x not in tuple
# count
print(t1.count("aa"))
# len
print(len(t1))
运行结果:

16.2 修改
元组本身不支持修改,如果元组中包含列表,列表支持修改
快速体验:
t1 = ("aa", "bb", "cc", ["Tom", "Jack"])
# t1[0] = "dd" # 元组数据不支持修改,报错 TypeError: 'tuple' object does not support item assignment
t1[3][0] = "Lyx"
print(t1)
运行结果:

17.字典
- 字典中的数据是以键值对的形式出现的
- 字典数据和数据顺序没有关系,即字段不支持下标
- 后期无论如何变化,只需要按照对应的键的名字查找数据即可
17.1 字典创建
字典特点:
- 符号为大括号
- 数据为键值对形式出现
- 各个键值对之间用逗号隔开
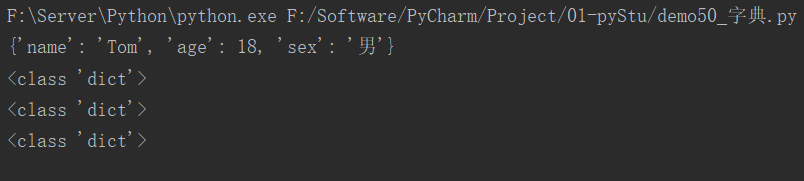
dict1 = {"name": "Tom", "age": 18, "sex": "男"}
print(dict1)
print(type(dict1))
dict2 = {}
print(type(dict2))
dict3 = dict()
print(type(dict3))
运行结果:
17.2 增
- 字典是可变字符序列
- 如果key存在,则修改对应的值,如果key不存在,则添加新的键值对
语法:
字典名["key名"] = 值
快速体验
user_info = {"name": "Tom", "age": 18, "sex": "男"}
user_info["name"] = "Lyx"
print(user_info)
user_info["id"] = 15
print(user_info)
运行结果:

17.3 删
del()/del:删除整个字典,或者删除指定键值对clear():清空字典
语法:
del 字典
del(字典)
del 字典["键"]
del(字典["键"])
字典.clear()
快速体验:
user_info = {"name": "Tom", "age": 18, "sex": "男"}
# 删除指定键值对
del user_info["name"]
print(user_info)
del (user_info["age"])
print(user_info)
# 删除整个字典
user_info2 = {"name": "Tom", "age": 18, "sex": "男"}
del user_info2
# print(user_info2) # user_info2已经删除,报错 NameError: name 'user_info2' is not defined
user_info3 = {"name": "Tom", "age": 18, "sex": "男"}
del (user_info3)
# print(user_info3) # user_info3已经删除,报错 NameError: name 'user_info2' is not defined
# 清空字典
user_info4 = {"name": "Tom", "age": 18, "sex": "男"}
user_info4.clear()
print(user_info4)
运行结果:

17.4 改
语法:
字典["key"] = 值
如增加中的用法相同,但是key的值要存在,否则创建新的键值对
17.5 查
- 通过key值查找:如果key值存在,则返回对应的值,否则报错
get():如果当前查找的key值不存在,则返回第二个自定义的默认值,如果没有设置默认值则返回Nonekeys():查找字典中所有的key,返回可迭代的对象,即可用for循环变量values():查找字典中所有的value,返回可迭代的对象items:查找字典中所有的键值对,返回可迭代的对象
语法:
字典["key"]
字典.get("key", 默认值)
字典.keys()
字典.values()
字典.items()
快速体验:
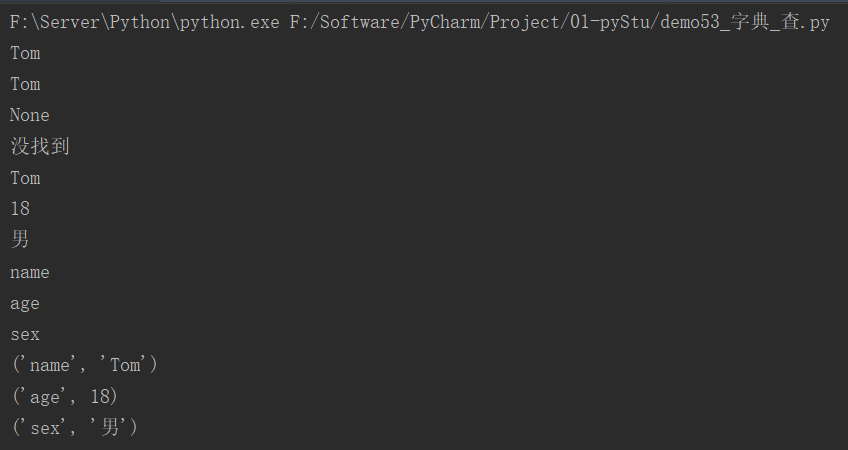
user_info = {"name": "Tom", "age": 18, "sex": "男"}
# 通过key查找
print(user_info["name"])
# get()
print(user_info.get("name"))
print(user_info.get("ccc"))
print(user_info.get("ccc", "没找到"))
# values()
for value in user_info.values():
print(value)
# keys()
for key in user_info.keys():
print(key)
# items()
for item in user_info.items():
print(item)
运行结果:
17.6 遍历
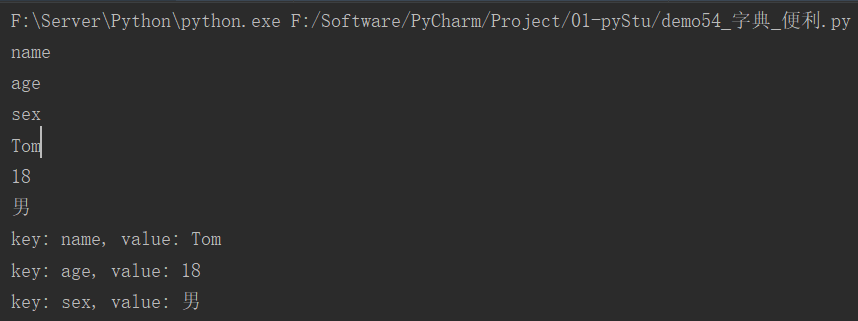
user_info = {"name": "Tom", "age": 18, "sex": "男"}
for key in user_info.keys():
print(key)
for value in user_info.values():
print(value)
for key, value in user_info.items():
print(f"key: {key}, value: {value}")
运行结果:
18.集合
集合(set)是一个无序的不重复元素序列。
可以使用大括号 { } 或者 set() 函数创建集合
创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
集合是一个可变类型数据
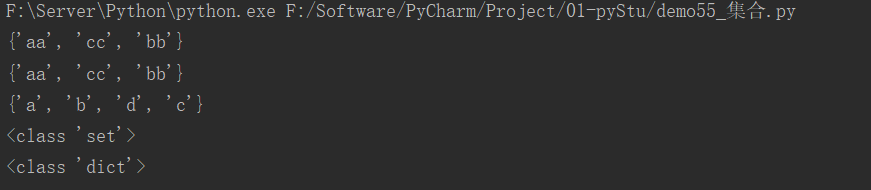
# 使用{}创建集合
s1 = {'aa', 'bb', 'cc'} # 集合中的数据无顺序
print(s1)
s2 = {'aa', 'bb', 'cc', "bb"} # 相同的数据自动去重
print(s2)
# 使用set()创建集合
s3 = set("abcd")
print(s3)
# 创建空集合
s4 = set()
print(type(s4))
s5 = {} # 空的大括号默认创建的是 dict
print(type(s5))
运行结果:
18.1 增
add():添加单一数据到原集合中来update():添加一个数据序列到原集合中来
s1 = {10, 20, 30}
# add()
s1.add("123")
s1.add(55)
print(s1)
# s1.add([10]) # add()只能添加单一数据,报错 TypeError: unhashable type: 'list'
# print(s1)
# update()
s1.update("abc") # 使用update()添加字符串,会将字符串拆分为单个字符
print(s1)
# s1.update(15) # update()只能添加数据序列,不能添加单一数据 报错 TypeError: 'int' object is not iterable
# print(s1)
运行结果:

18.2 删
remove(): 删除集合中的指定数据,如果数据不存在,则报错discard(): 删除集合中的指定数据,如果数据不存在不会报错pop():岁间删除集合中的某个数据,并返回这个数据
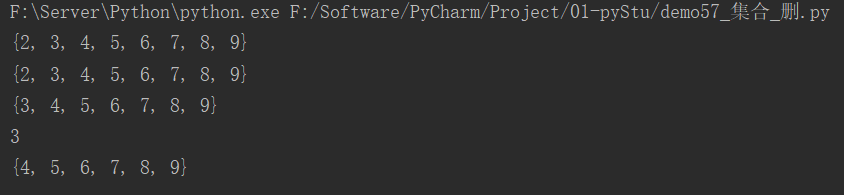
s1 = {1, 2, 3, 4, 5, 6, 7, 8, 9}
# remove()
s1.remove(1)
print(s1)
# s1.remove("a") # 集合中不存在,报错 KeyError: 'a'
# print(s1)
# discard()
s1.discard("a")
print(s1)
s1.discard(2)
print(s1)
# pop()
num = s1.pop()
print(num)
print(s1)
运行结果:
18.3 改
in:判断数据在集合中
not in:判断数据不在集合中
s1 = {1, 2, 3, 4, 5, 6, 7, 8, 9}
# in
print(1 in s1)
print('a' in s1)
# not in
print(1 not in s1)
print("a" not in s1)
运行结果:

19.公共操作
19.1 运算符
| 运算符 | 描述 | 支持容器 |
|---|---|---|
| + | 合并 | 字符串,列表,元组 |
| * | 复制 | 字符串,列表,元组 |
| in | 元素是否存在 | 字符串,列表,元组,字典,集合 |
| not in | 元素是否不存在 | 字符串,列表,元组,字典,集合 |
19.1.1 +
合并
str1 = 'aa'
str2 = 'bb'
list1 = [0, 1]
list2 = [2, 3]
t1 = (1, 2)
t2 = (4, 5)
dict1 = {"name": "Lyx", "age": 18}
dict2 = {"sex": "男", "height": 185.0}
# 合并+
print(str1 + str2)
print(list1 + list2)
print(t1 + t2)
# print(dict1 + dict2) # 字典无合并操作,报错 TypeError: unsupported operand type(s) for +: 'dict' and 'dict'
# print(s1 + s2) # 集合无合并操作,报错 TypeError: unsupported operand type(s) for +: 'set' and 'set'
运行结果:

19.1.2 *
复制
str1 = '*'
list1 = ['a', 'b']
t1 = (1, 2)
dict1 = {"name": "Lyx"}
# *复制
print(str1 * 5)
print(list1 * 5)
print(t1 * 5)
# print(dict1 * 5) # dict不支持复制操作。报错 TypeError: unsupported operand type(s) for *: 'dict' and 'int'
# print(s1 * 5) # set不支持复制操作,报错 TypeError: unsupported operand type(s) for *: 'set' and 'int'
运行结果:

19.1.3 in / not in
元素是否存在
str1 = 'abc'
list1 = ['a', 'b']
t1 = (1, 2)
dict1 = {"name": "Lyx"}
s1 = {"aa", "bb"}
# in / not in
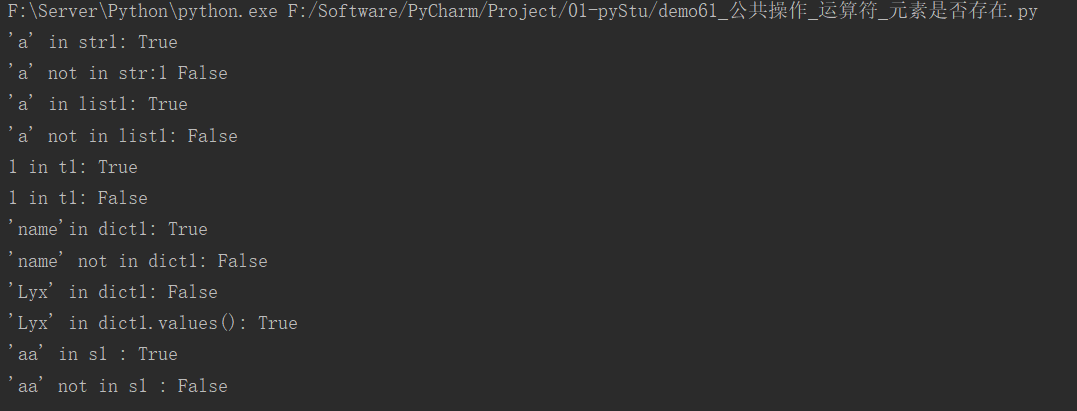
print("'a' in str1:", 'a' in str1)
print("'a' not in str:1", 'a' not in str1)
print("'a' in list1:", 'a' in list1)
print("'a' not in list1:", 'a' not in list1)
print("1 in t1:", 1 in t1)
print("1 in t1:", 1 not in t1)
print("'name'in dict1:", 'name'in dict1)
print("'name' not in dict1:", 'name' not in dict1)
print("'Lyx' in dict1:", 'Lyx' in dict1) # 只能判断key是否在字典中
print("'Lyx' in dict1.values():", 'Lyx' in dict1.values())
print("'aa' in s1 :", 'aa' in s1)
print("'aa' not in s1 :", 'aa' not in s1)
运行结果:
19.2 公共方法
| 函数 | 描述 |
|---|---|
| len() | 计算容器中元素个数 |
| del 或 del() | 删除 |
| max() | 返回容器中元素的最大值 |
| min() | 返回容器中元素的最小值 |
| range(start, end, step) | 生成从start到end的数字,步长为step, 供for循环使用 |
| enumerate() | 函数用于将一个可遍历的数据对象(如列表,元组或字符串)组合为一个索引列,同时列出数据和数据下标,一般在for循环中使用 |
19.2.1 len()
计算容器中元素个数
str1 = "abcde"
list1 = [0, 1, 2, 3]
t1 = (0, 1, 2, 3)
dict1 = {"name": "Lyx", "age": 18}
s1 = {"aa", "bb"}
# len()
print("str1:", len(str1))
print("list1:", len(list1))
print("t1:", len(t1))
print("dict1:", len(dict1))
print("s1:", len(s1))
运行结果:

19.2.3 del/del()
删除
str1 = "abcde"
list1 = [0, 1, 2, 3]
t1 = (0, 1, 2, 3)
dict1 = {"name": "Lyx", "age": 18}
s1 = {"aa", "bb"}
# del str1
# print(str1) # 数据已删除,报错:NameError: name 'str1' is not defined
# del list1
# print(list1) # 数据已删除,报错:NameError: name 'list1' is not defined
# del t1
# print(t1) # 数据已删除,报错:NameError: name 't1' is not defined
# del dict1
# print(dict1) # 数据已删除,报错:NameError: name 'dict1' is not defined
# del s1
# print(s1) # 数据已删除,报错:NameError: name 's1' is not defined
# del(str1[0]) # 字符串不支持del,报错 TypeError: 'str' object doesn't support item deletion
# print("str1 : ", str1)
del(list1[0])
print("list1 : ", list1)
# del(t1[0])
# print("t1 : ", t1) # 元组不支持del,报错 TypeError: 'str' object doesn't support item deletion
del(dict1["name"])
print("dict1 : ", dict1)
# del(s1["aa"])
# print(s1) # 元组不支持del,报错 TypeError: 'str' object doesn't support item deletion
运行结果:

19.2.4 max()/min()
返回容器中元素的最大最小值
str1 = "abcde"
list1 = [0, 1, 2, 3]
t1 = (0, 1, 2, 3)
dict1 = {"name": "Lyx", "age": 18}
s1 = {"aa", "bb"}
# max()
print("str1 max : ", max(s1))
print("list1 max : ", max(list1))
print("t1 max : ", max(t1))
print("dict1 max : ", max(dict1)) # 会输出最大值的键
print("s1 max : ", max(s1))
运行结果:

19.2.5 range()
生成从start到end的数字,步长为step, 供for循环使用
语法:
range(start, end, step)
快速体验:
for i in range(0, 10): # 不包含结束为,默认步长为1
print("i = ", i, end=";\t")
print()
for i in range(0, 10, 2):
print("i = ", i, end=";\t")
print()
运行结果:

19.2.6 enumerate()
函数用于将一个可遍历的数据对象(如列表,元组或字符串)组合为一个索引列,同时列出数据和数据下标,一般在for循环中使用
返回的结果是元组,返回的第一个数据是原迭代对象的数据对应的下标,返回的第二个数据是原迭代对象的数据
语法:
enumerate(可遍历对象, start)
快速体验:
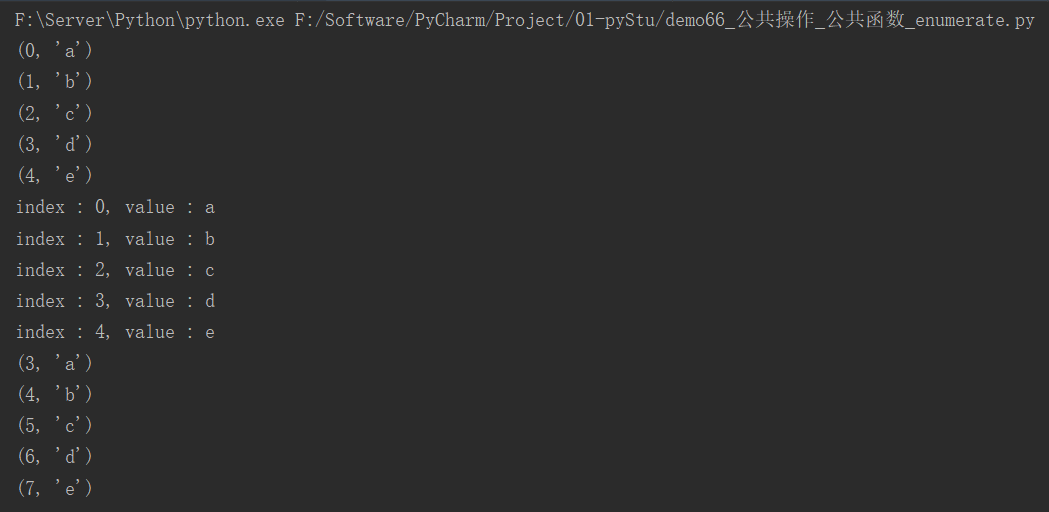
list1 = ["a", "b", "c", "d", "e"]
# enumerate()
for t in enumerate(list1):
print(t)
for index, value in enumerate(list1):
print(f"index : {index}, value : {value}")
for t in enumerate(list1, start=3): # 让容器从下标3开始计数
print(t)
运行结果:
19.3 容器类型转换
- tuple():将容器转换成元组
- list():将容器转换成列表
- set():将容器类型转换成集合
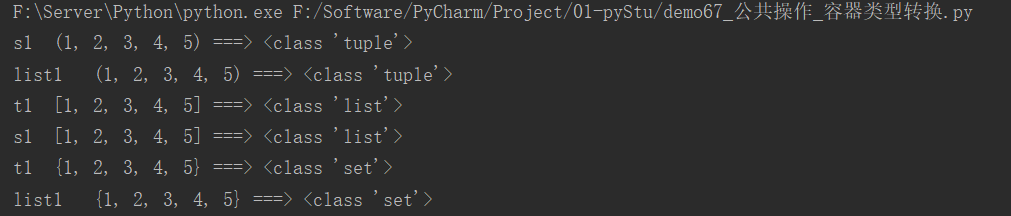
t1 = (1, 2, 3, 4, 5)
list1 = [1, 2, 3, 4, 5]
s1 = {1, 2, 3, 4, 5}
# tuple()
print(f"s1\t{tuple(s1)} ===> {type(tuple(s1))}")
print(f"list1\t{tuple(list1)} ===> {type(tuple(list1))}")
# list()
print(f"t1\t{list(t1)} ===> {type(list(t1))}")
print(f"s1\t{list(s1)} ===> {type(list(s1))}")
# set()
print(f"t1\t{set(t1)} ===> {type(set(t1))}")
print(f"list1\t{set(list1)} ===> {type(set(list1))}")
运行结果:
20.推导式
- 列表推导式
- 集合推导式
- ‘字典推导式
20.1 列表推导式
作用:用一个表达式创建一个有规律的列表或控制一个有规律的列表
列表推导式又叫列表生成式
要求:生成一个列表,里面的数据1,2,3…9
# 创建一个列表,里面数据0,1,2...9
# while
i = 0
list1 = []
while i < 10:
list1.append(i)
i += 1
print(list1)
# for
list2 = []
for i in range(10):
list2.append(i)
print(list2)
# 列表推导式
list3 = [i for i in range(10)]
print(list3)
运行结果:

20.1.1 带if的列表推导式
要求:创建列表,里面包含1~10之间的偶数
# 要求:创建列表,里面包含0~10之间的偶数
# while
list1 = []
i = 0
while i < 11:
if i % 2 == 0:
list1.append(i)
i += 1
print(list1)
# for
list2 = []
for i in range(0, 11, 2):
list2.append(i)
print(list2)
# 推导式
list3 = [i for i in range(0, 11, 2)]
print(list3)
# 带if推导式
list4 = [i for i in range(11) if i % 2 == 0]
print(list4)
运行结果:

20.1.2 多个for循环推导式
类似for循环嵌套的写法
需求:创建如下格式列表
[(1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2), (3, 0), (3, 1), (3, 2)]
代码如下:
# 需求:创建如下格式列表
# [(1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2), (3, 0), (3, 1), (3, 2)]
list1 = [(i, j) for i in range(1, 4) for j in range(3)]
print(list1)
运行结果:

20.2 字典推导式
作用:快速合并列表为字典或提取字典中的目标数据
-
要求:创建一个字典,key式1~5,value式key的平方
代码如下:
# 要求:创建一个字典,key式1~5,value是key的平方 dict1 = {key: key**2 for key in range(1, 6)} print(dict1)运行结果:

-
要求:将两个列表和在一起
["Tom", 18, "男"] ["name", "age", "sex"]代码如下:
# 合并两个列表为字典 list1 = ["Tom", 18, "男"] list2 = ["name", "age", "sex"] dict1 = {list2[i]: list1[i] for i in range(len(list1))} print(dict1)运行结果:

-
提取列表中的数据
# 提取销售量大于100的数据 counts = {hp: 150, dell: 75, ause: 105, lenovo: 90, mac: 200}代码如下:
# 提取销售量大于100的数据 counts = {"hp": 150, "dell": 75, "ause": 105, "lenovo": 90, "mac": 200} count = {key: value for key, value in counts.items() if value > 100} print(count)运行结果:

20.3 集合推导式
目标:将下列数据的二次方传入集合中区
list1 = [1,2,3,4]
代码如下:
# 目标:将下列数据的二次方传入集合中
list1 = [1, 2, 3, 4]
s1 = {i ** 2 for i in list1}
print(s1)
运行结果:

21.函数
- 函数就是将一段具有独立功能的代码块整合到一个整体并命名,在需要的位置调用这个名称即可完成对应的需求。
- 在函数开发过程中,可以更高效的实现代码重用
21.1 函数使用方法
21.1.1 定义函数
def 函数名(参数):
代码1
代码2
...
21.1.2 调用函数
函数名(参数)
注意:
- 不同的需求,参数可有可无
- 在python中,函数必须先定义后使用
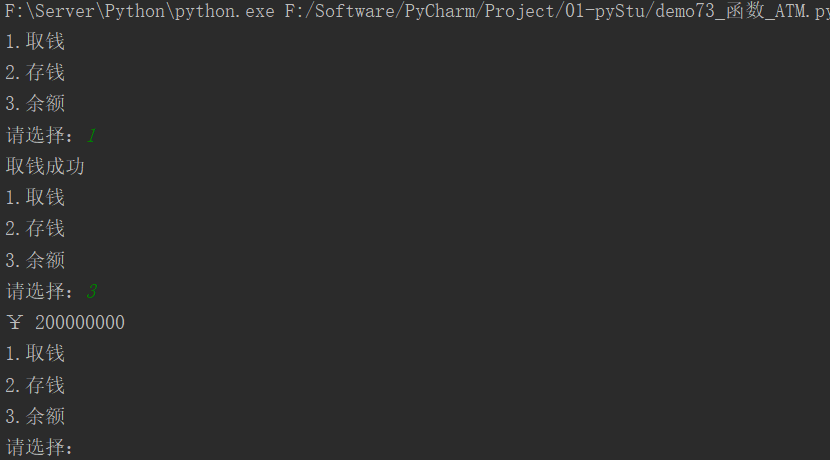
21.1.3 ATM案例
# 模拟ATM
# 功能选择界面
def function_list():
print("1.取钱")
print("2.存钱")
print("3.余额")
# 取钱
def take_money():
print("取钱成功")
# 存钱
def deposit():
print("存钱成功")
# 余额
def balance():
print("¥ 200000000")
while True:
function_list()
select = int(input("请选择:"))
if select == 1:
take_money()
elif select == 2:
deposit()
elif select == 3:
balance()
else:
print("您的输入有误请重新输入!")
运行结果:
21.2 参数
写一个加法函数,输入两个数调用加法函数相加
# 加
def sum(num1, num2):
print(f"{num1} + {num2} = {num1 + num2}")
num1 = int(input("请输入一个数:"))
num2 = int(input("请输入另一个数:"))
sum(num1, num2)
运行结果:

21.3 返回值
return作用:
- 返回值
- 结束当前函数
快速体验:
# 买烟
def buy():
return "烟"
str1 = buy()
print(str1)
运行结果:

21.4 函数说明文档
- 查看函数说明文档语法
help(函数名)
快速体验:
help(len)
运行结果:

- 创建函数说明文档语法
def 函数名():
"""函数说明文档"""
代码
...
快速体验:
def buy():
"""购买商品"""
print("买糖")
help(buy)
运行结果:

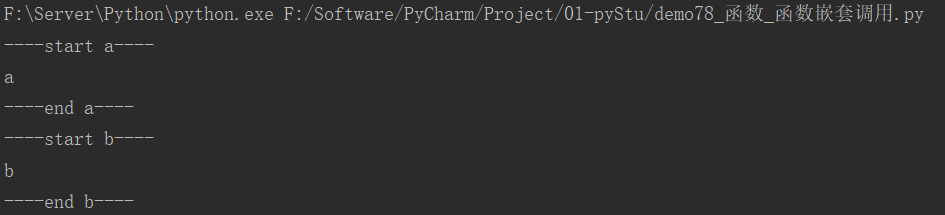
21.5 函数嵌套调用
def a():
print("----start a----")
print("a")
print("----end a----")
def b():
print("----start b----")
print("b")
print("----end b----")
def c():
a()
b()
c()
运行结果:
21.6 变量的作用域
变量的作用域指的是变量生效的范围,主要分为两类:局部变量和全局变量
-
局部变量
- 只在函数体内有效
def testA(): a = 100 print("a") testA() # print(a) # a是局部变量,只在方法内有效,报错:NameError: name 'a' is not defined运行结果:

局部变量作用:在函数体内临时保存数据,当函数调用完后,则立即销毁局部变量
-
全局变量
- 在函数体内外都能生效的变量
a = 100 def testA(): print(a) def testB(): print(a) testA() testB() print(a)运行结果:

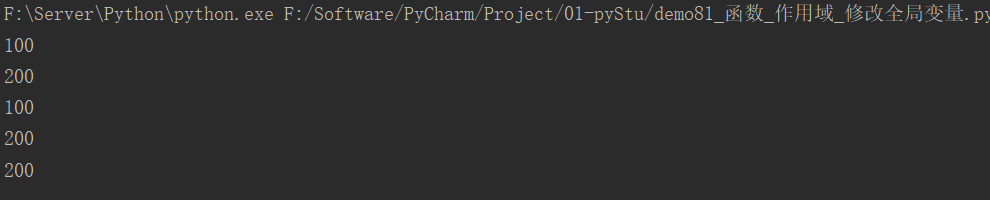
26.1 修改函数全局变量
a = 100
def testA():
print(a)
def testB():
a = 200 # 相当于声明了局部变量,无法修改全局变量
print(a)
def testC():
global a # 声明a为全局变量
a = 200
print(a)
testA()
testB()
print(a)
testC()
print(a)
运行结果:
21.7 返回值作为参数传递
def testA():
return 50
def testB(num):
print(num)
testB(testA())
运行结果:

21.8 多个返回值
def testA():
return 1
return 2 # 由于上一个return已经结束方法,这个return将不会执行
def testB():
return 1, 2 # 返回多个值,默认格式为元组
print(testA())
print(testB())
运行结果:

注意:
- return a, b 的写法,返回多个数据的时候,默认是元组
- return 后面可以连接列表,元组,以返回多个值
21.9 函数的参数
21.9.1 位置参数
位置参数:调用函数时根据函数定义的参数位置来传递参数
def user_info(name, age, sex):
print(f"您的姓名是{name},年龄是{age}, 性别{sex}")
user_info("Tom", 18, "男")
user_info("Tom", "男", 18) # 函数传入的参数与实际不匹配,无意义
# user_info("Tom", 18) # 缺少参数,报错TypeError: user_info() missing 1 required positional argument: 'sex'
运行结果:

21.9.2 关键字参数
函数调用,通过"键" = "值"的形式指定,可以让函数更加清晰,容易使用,同时也清除了函数参数的顺序需求
def user_info(name, age, sex):
print(f"您的姓名是{name},年龄是{age}, 性别{sex}")
user_info("Tom", age=18, sex="男")
user_info(age=18, name="Tom", sex="男")
运行结果:

21.9.3 缺省参数(默认参数)
- 缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数式可以不用传入该默认参数
def user_info(name, age, sex="男"):
print(f"您的姓名是{name},年龄是{age}, 性别{sex}")
user_info("Tom", 18)
user_info("Rose", 20, "女")
注意:所有位置参数必须出现在默认参数之前,包括函数的定义和调用
21.9.4 不定长参数
不定长参数也叫可变参数,用于不确定调用的时候会传递多少个参数(不传参也可以)的场景。此时,可以包裹(packing)位置参数,或者包裹关键字参数,来进行参数传递,会显得非常方便
- 包裹位置传递
def user_info(*args):
print(args)
user_info("Tom", 18)
user_info("Tom", 18, "男")
运行结果:

注意:传进的所有参数都会被args收集,会根据传递进来的参数位置合并成一个元组,ages是元组类型,这就是包裹位置传递
- 包裹关键字传递
def user_info(**kwargs):
print(kwargs)
user_info(name="Tom")
user_info(name="Tom", age=18)
综合:无论是包裹位置还是包裹关键字传递都是一个组包的过程
22.拆包和交换变量值
22.1 拆包
- 拆包:元组
num1, num2 = (100, 200)
print(f"num1={num1}, num2={num2}")
def return_num():
return 100, 200
num3, num4 = return_num()
print(f"num3={num3}, num4={num4}")
运行结果:

- 拆包:字典
name, age = {"name": "Tom", "age": 18}
print(f"name = {name}, age = {age}")
运行结果:

22.2 交换变量的值
a = 10
b = 20
a, b = b, a
print(f"a={a}, b={b}")
运行结果:

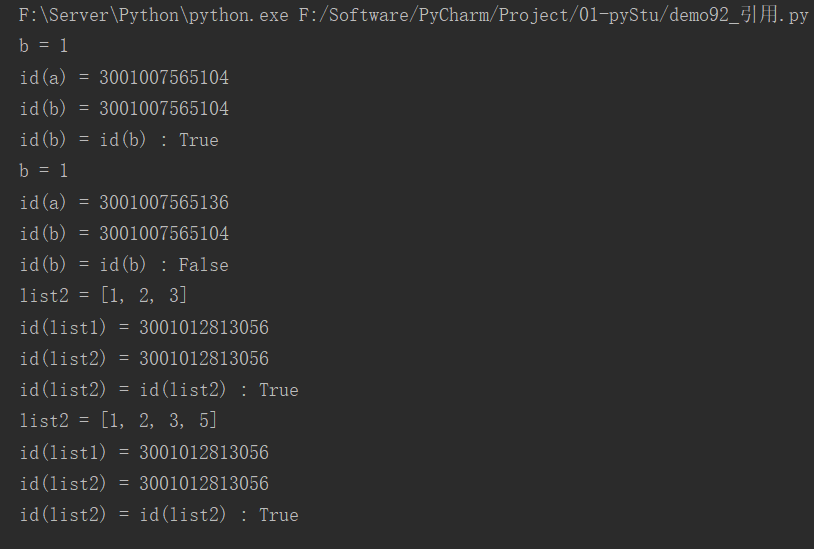
23.引用
在python中值是靠引用来传递的
我们可以使用id()来判断两个变量是否为同一个引用地址。
a = 1
b = a
print(f"b = {b}")
print(f"id(a) = {id(a)}")
print(f"id(b) = {id(b)}")
print(f"id(b) = id(b) : {id(a) == id(b)}")
a += 1 # int是不可变数据类型,b不会改变内存地址
print(f"b = {b}")
print(f"id(a) = {id(a)}")
print(f"id(b) = {id(b)}")
print(f"id(b) = id(b) : {id(a) == id(b)}")
list1 = [1, 2, 3]
list2 = list1
print(f"list2 = {list2}")
print(f"id(list1) = {id(list1)}")
print(f"id(list2) = {id(list2)}")
print(f"id(list2) = id(list2) : {id(list1) == id(list2)}")
list1.append(5) # list是可变类型,list1改变,list2也会跟着改变
print(f"list2 = {list2}")
print(f"id(list1) = {id(list1)}")
print(f"id(list2) = {id(list2)}")
print(f"id(list2) = id(list2) : {id(list1) == id(list2)}")
运行结果:
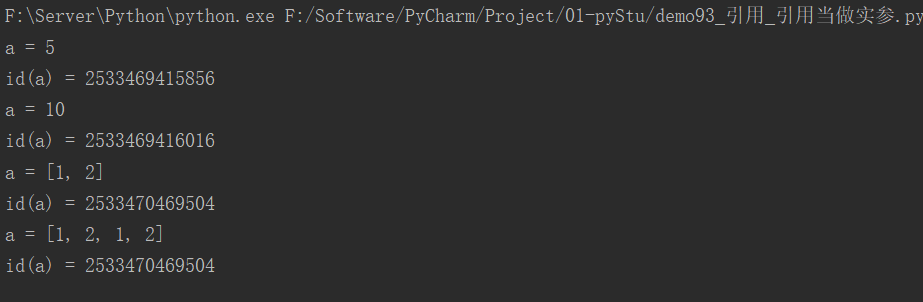
23.1 引用当做实参
def test(a):
print(f"a = {a}")
print(f"id(a) = {id(a)}")
a += a
print(f"a = {a}")
print(f"id(a) = {id(a)}")
test(5)
test([1, 2])
运行结果:
24.可变类型和不可变类型
所谓可变类型和不可变类型是指:数据能够直接进行修改,如果能直接修改那么就是可变,否则就是不可变
- 可变类型
- 列表
- 字典
- 集合
- 不可变类型
- 整数型
- 浮点型
- 字符串
- 元组
25.递归
特点:
- 函数内部自己调用自己
- 必须有出口
25.1 递归应用:数字累加
要求:5以内数字累加
# 5以内数字累加
def sum_number(num):
if num == 1: # 出口
return 1
return num + sum_number(num-1)
print(sum_number(5))
运行结果:

26.lambda
如果一个函数有一个返回值,并且只有一句代码,就可以用lambda简化
语法:
lanbda 参数列表: 表达式
注意:
- lambda表达式的参数可有可无,函数的参数在lambda表达式中完全使用
- lambda表达式能接受任何数量的参数当只能返回一个表达式的值
快速入门:
def fn1():
print(123)
print(fn1) # 直接打印变量名,打印的是该变量的内存地址
fn1()
# 使用lambda表达式
fn2 = lambda: print(123) # lambda是一个匿名函数
print(fn2)
fn2()
运行结果:

26.1 计算a + b
代码实现:
# 传统方法加上a+b
def sum_number(a, b):
return a + b
print(sum_number(1, 2))
# 使用lambda计算a+b
sum_number2 = lambda a, b: a + b
print(sum_number2(1, 2))
运行结果:

26.2 lambda的参数形式
# 1.无参数
fn1 = lambda: 100
print(fn1())
# 2.一个参数
fn2 = lambda a: a
print(fn2(100))
# 3.默认参数
fn3 = lambda a, b, c=100: a + b + c
print(fn3(100, 200))
# 4.可变参数: *args
fn4 = lambda *args: args
print(fn4("Tom", 18))
# 5.可变参数: **kwargs
fn5 = lambda **args: args
print(fn5(name="Tom", age=20))
运行结果:
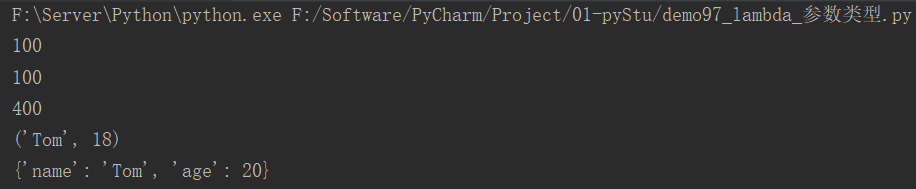
26.3 带判断的lambda
快速体验:
fn1 = lambda a, b: a if a > b else b
print(fn1(10, 20))
运行结果:

26.4 列表数据按字典的key值进行排列
students = [{"id": id, "name": "张三"+str(id)} for id in range(1, 10)]
print(students)
# 按照id进行升序
students.sort(key=lambda x: x["id"])
print(students)
# 按照id进行降序
students.sort(key=lambda x: x["id"], reverse=True)
print(students)
运行结果:

27.高阶函数
把函数作为参数传入,这样的函数称为高阶函数,稿件函数是函数式编程的体现。函数式编程就是 指这中高度抽象的编程范式
27.1 体验高阶函数
abs():求数字的绝对值
round():数字的四舍五入
# 传统方法
def fn1(a, b):
return abs(a) + abs(b)
def fn2(a, b):
return round(a) + round(b)
print(fn1(1, -1))
print(fn2(1.5, 2))
# 使用高阶函数
def fn3(a, b, fn):
return fn(a) + fn(b)
print(fn3(1, -1, abs))
print(fn3(1.5, 2, round))
运行结果:

注意:两种方法对比后发现,高阶函数的代码会更灵活代码简洁。
函数式编程大量使用函数,减少了代码的重复,因此程序比较短,开发速度快
27.2 高阶内置函数
27.2.1 map()
**map(func,lst)**将传入的函数func作用到lst变量每一个元素中。并将结果组成新的列表返回
list1 = [i for i in range(1, 10)]
def func(x):
return x**2
list2 = map(func, list1)
print(list2)
print(list(list2))
运行结果:

27.2.2 reduce()
**reduce(func, lst)**其中func必须有两个参数。每次func计算的结果继续和序列的下一个元素做累积计算
注意:reduce()传入的参数func必须有2个参数
需求:计算序列中各个数字的累加计算
import functools # 导入reduce需要的包
# 需求:计算序列中各个数字的累加计算
list1 = [i for i in range(20)] # 定义列表序列
def func(a, b): # 定义用来做累积计算的函数,将每次的结果与序列中下一个数传入函数进行计算
return a + b
result = functools.reduce(func, list1)
print(result)
运行结果:

filter()
filter(func, lst)函数用于过滤序列,过滤掉不符合条件的元素,返回一个filter对象,可转换成需要的对象。
快速体验:
# 需求:去除列表中所有奇数
list1 = [i for i in range(10)]
def func(x): # 用于过滤的函数,经序列中的数据传入函数中,复合条件返回True,否则返回False
return x % 2 == 0
new_list = list(filter(func, list1))
print(new_list)
运行结果:

23.文件操作
23.1 文件的基本操作
- 打开文件
- 读写等操作
- 关闭文件
注意:可以只打开和关闭文件不进行任何操作
23.1.1 打开文件
在python中,使用函数open函数,可以打开一个已经存在的文件,或者新建一个文件
语法:
open(name, mode)
name:要打开的目标文件名的字符串(可以包含文件所在路径)
mode:设置文件的打开方式(访问模式):只读,写入,追加等
快速体验:
# 1.使用open()函数打开文件
file = open("test.txt", "w") # 如果文件不存在,则创建新的文件
# 2.读写操作write(), read()
file.write("hello python")
# 3.使用close()函数关闭文件
file.close()
运行结果:
23.1.2 访问模式
| 模式 | 描述 |
|---|---|
| r | 以只读的方式打开文件。文件的指针放在文件开头。这是默认模式 |
| rb | 以二进制格式打开一个文件用于只读。文件指针放在文件开头。这是默认模式 |
| r+ | 打开一个文件用于读。文件指针放在文件开头 |
| rb+ | 以二进制格式打开一个文件用于读。文件指针放在文件开头 |
| w | 打开一个文件只用于写入。如果该文件已经存在则打开文件,并从开头开始编辑。即原有内容会被删除。如果文件不存在,则会创建新文件 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已经存在则打开文件,并从开头开始编辑。即原有内容会被删除。如果文件不存在,则会创建新文件 |
| w+ | 打开一个文件只用于读写。如果该文件已经存在则打开文件,并从开头开始编辑。即原有内容会被删除。如果文件不存在,则会创建新文件 |
| wb+ | 以二进制格式打开一个文件只用于读写。如果该文件已经存在则打开文件,并从开头开始编辑。即原有内容会被删除。如果文件不存在,则会创建新文件 |
| a | 打开一个文件用于追加。如果该文件已经存在,文件指针将会放在文件的结尾。也就是说新的内容会被写入到已有内容之后。如果文件不存在,则会创建新文件进行写入。 |
23.1.3 读
- read()
文件对象.read(num)
num表示要从文件中读取数据的长度(单位是字节),如果没有传入num,就表示读取所有数据
快速体验:
file = open("test.txt", "r")
s = file.read(15) # 读取15个字节,空格不占字节,换行占一个字节
print(s)
运行结果:

-
readlines()
readlines()可以按照行的方式把整个文件中的的内容进行一次性读取,返回的是一个列表,其中每一行的数据为一个元素
file = open("test.txt", "r") # 只读的访问模式打开文件 content = file.readlines() print(content) # 换行会以\n保存在文件中,占一个字符 file.close() # 关闭文件运行结果:

-
readline()
readine()每次读取一行,读完后指针放在下一行的开头
file = open("test.txt") # 默认访问模式r
line1 = file.readline()
line2 = file.readline()
print(f"line1: {line1}")
print(f"line2: {line2}")
运行结果:

23.1.4 seek()
作用:用来移动指针
语法如下:
文件对象.seek(偏移量, 起始位置)
其实位置:
- 0:文件开头
- 1:当前位置
- 2:文件结尾
file = open("test.txt", "rb")
print(file.read().decode("utf-8")) # 将二进制编码,解码成utf-8
file.seek(6, 0) # 偏移量6个字符,指针在文件开头
str1 = file.read(1).decode("utf-8")
file.seek(2, 1) # 偏移量2个字符,指针在当前位置,必须使用rb模式,使用r则报错 io.UnsupportedOperation: can't do nonzero cur-relative seeks
str2 = file.read(1).decode("utf-8")
file.seek(0, 2) # 偏移量0个字符,指针在文件结尾
str3 = file.read(1).decode("utf-8") # 指针在结尾,无法读取
print(str1)
print(str2)
print(str3)
file.close()
运行结果:

23.2 文件备份
需求:用户输入当前目录下的任意文件名,程序完成对该文件的备份功能(备份文件名为xx[备份]后缀)
代码实现:
file_name = input("请输入文件名:") # 获取文件名
file = open(file_name, "r") # 打开被复制文件
info = file.read() # 读取被复制文件内容
file.close() # 关闭被复制文件
# 源文件可能形式:1.mp3.txt => suffix:txt prefix:1.mp3
suffix = file_name.split(".")[(len(file_name.split(".")) - 1)] # 获得源文件后缀
prefix = file_name[0:len(file_name)-len(suffix)-1] # 获得源文件前缀
new_file_name = prefix + "[备份]." + suffix
print(new_file_name)
new_file = open(new_file_name, "w") # 以读写的方式创建文件
new_file.write(info) # 将原文件内容写入备份文件
print("备份文件生成成功", new_file_name)
new_file.close() # 关闭备份文件
运行结果:

23.2.1 文件备份优化
# 获取用户输入的文件名
file_name = input("请输入要复制的文件名:")
if file_name.count(".") > 0:
index = file_name.rfind(".") # 查找最后一个点的位置,即文件名和后缀之间的点
# 判断用户输入的文件名是否正确
if index > 0 and (index < (len(file_name) - 1)): # 文件的最后一个点不在第一位和最后一位即不能为 .txt 或 a.这些形式的文件名
# 前缀
prefix = file_name[:index]
# 后缀
suffix = file_name[index:]
# 新文件名称
new_file_name = prefix + "[备份]" + suffix
# 以二进制打开源文件
file = open(file_name, "rb") # 使用二进制,可复制任何格式的文件
# 以二进制格式打开新文件,即创建新文件
new_file = open(new_file_name, "wb")
# 读取源文件,写入新的文件
while True:
con = file.read(1024) # 每次读取1024个字节,防止占用内存过大
if len(con) == 0:
break
new_file.write(con)
print(f"文件备份成功{file_name} --> {new_file_name}")
# 关闭文件
file.close()
new_file.close()
运行结果:

23.3 文件和文件夹
在python中文件和文件夹的操作需要导入os模块,具体步骤如下
-
导入os模块
import os -
使用os模块相关内容
os.函数名()23.3.1文件重命名
os.rename(目标文件名, 新文件名)快速体验:
import os os.rename("test[备份].txt", "123.txt")23.3.2 删除文件
os.remove(目标文件名)快速体验:
import os os.remove("test.txt")23.3.3 创建文件夹
os.mkdir(文件夹名)快速体验
import os os. mkdir("test") # 文件夹重名会报错 FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。23.3.4 删除文件夹
os.rmdir(文件夹名)快速体验:
import os os.rmdir("test") # 如果找不到目标文件夹会报错 FileNotFoundError: [WinError 2] 系统找不到指定的文件。: 'test'23.3.4 获取当前文件夹路径
os.getcwd()快速体验:
import os print(os.getcwd())运行结果:

23.3.5 改变文件夹默认路径
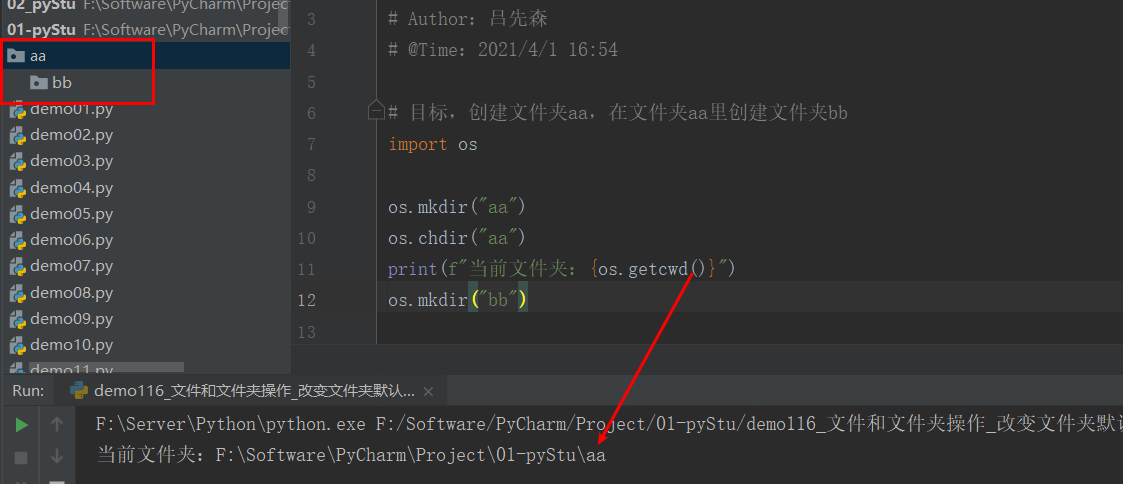
os.chdir(目录)快速体验:
# 目标,创建文件夹aa,在文件夹aa里创建文件夹bb import os os.mkdir("aa") os.chdir("aa") print(f"当前文件夹:{os.getcwd()}") os.mkdir("bb")运行结果:
23.3.5 获取目录列表
os.listdir()快速体验:
import os lst = os.listdir("aa") # 获取目标文件夹下的所有文件名 lst2 = os.listdir() # 获取当前文件夹的所有文件名 print(lst) print(lst2)运行结果:

23.3.4 重命名文件夹
os.rename(源文件名, 新文件名)
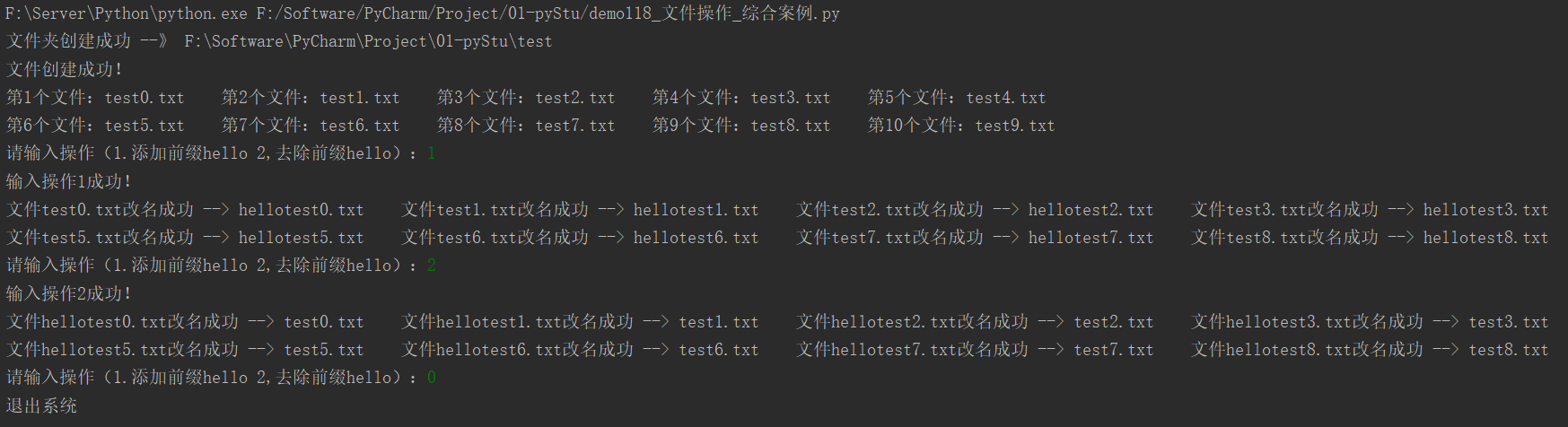
23.4综合案例
"""
创建一个文件夹,里面随机生成10个文件,根据用户输入修改文件名
"""
import os
# 创建文件夹
os.mkdir("test")
# 进入创建的文件
os.chdir("test")
# 得到文件夹路径
dir_path = os.getcwd()
print(f"文件夹创建成功 --》 {dir_path}")
for i in range(10):
# 创建的文件名
file_name = "test" + str(i) + ".txt"
# 打开文件(创建文件)
new_file = open(file_name, "wb")
# 创建成功,关闭文件
new_file.close()
file_list = os.listdir()
print(f"文件创建成功!")
for index, item in enumerate(file_list):
print(f"第{index+1}个文件:{item}", end="\t")
# 每输出5个换行
if (index + 1) % 5 == 0:
print()
# 接收用户输入的文件操作指令
num = 0
public_name = "hello"
while True:
num = input("请输入操作(1.添加前缀hello 2,去除前缀hello):")
if num == "1":
print("输入操作1成功!")
# 变量文件列表
for index,item in enumerate(file_list):
# 拼接新的名字
new_name = public_name+item
# 修改名字
os.rename(item, new_name)
print(f"文件{item}改名成功 --> {new_name}", end="\t")
if (index + 1) % 5 == 0:
print()
file_list = os.listdir()
elif num == "2":
print("输入操作2成功!")
for index, item in enumerate(file_list):
# 获得前缀长度
public_name_len = len(public_name)
# 去除指定前缀
new_name = item[public_name_len:]
os.rename(item, new_name)
print(f"文件{item}改名成功 --> {new_name}", end="\t")
if (index + 1) % 5 == 0:
print()
file_list = os.listdir()
elif num == "0":
print("退出系统")
break
else:
print("输入的操作有误,请重新输入!")
运行结果:

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









