







TCP采用的下面的方式来实现可靠性
-
确认应答机制(ACK)
-
超时重传机制
-
校验和
-
序列号
-
连接管理(三次握手四次挥手)
-
流量控制
-
拥堵控制
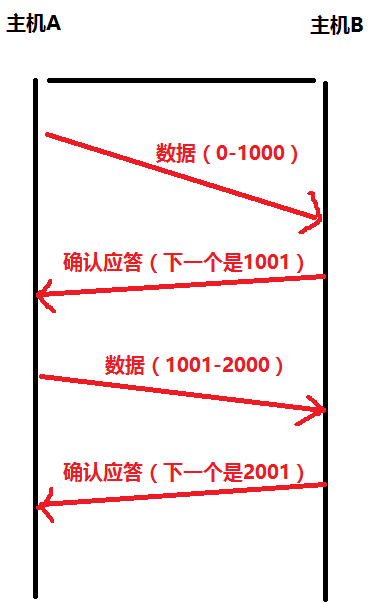
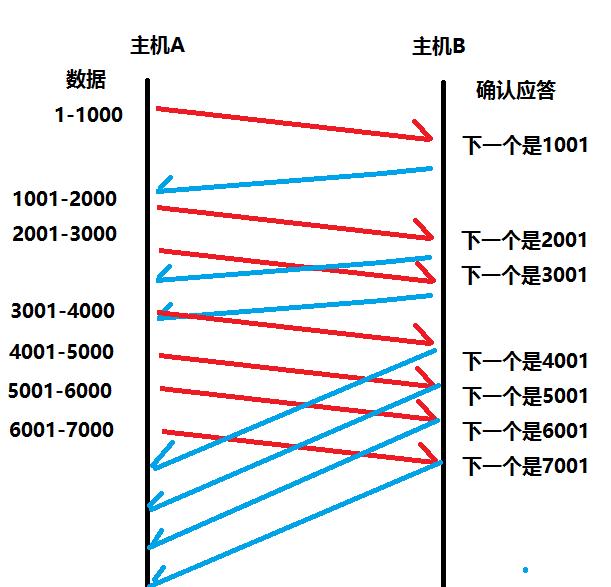
确认应答(ACK)机制
-
连接成功之后,发送的每条数据都可能丢失,因此就需要确认应答。
-
TCP将每个字节的数据都进行了编号,即为序列号
-
每一个ACK都带有对应的确认序列号,意思是告诉之前发送这个数据的发送者,我已经收到了哪些数据,下一次你从哪里开始发
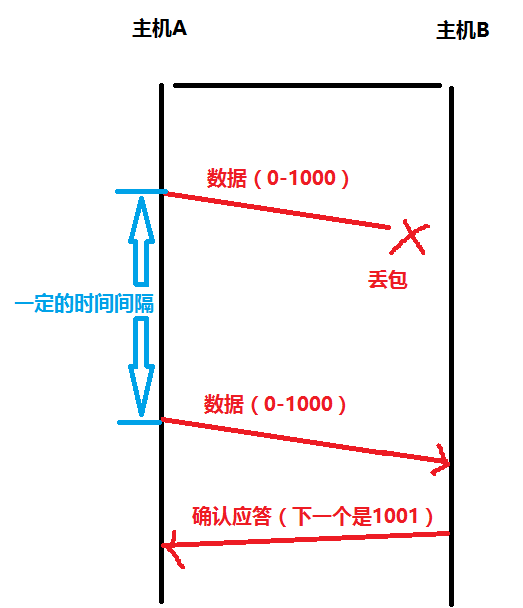
超时重传机制
-
主机A发送数据给数据B的时候,可能因为网络拥堵等原因,数据无法送到主机B
-
如果主机A在一个特定时间间隔内没有收到B发来的确认应答,就认为超时了,进行重发
但另一个情况也可能是主机B发给主机A的确认应答丢了,导致A没有收到确认应答
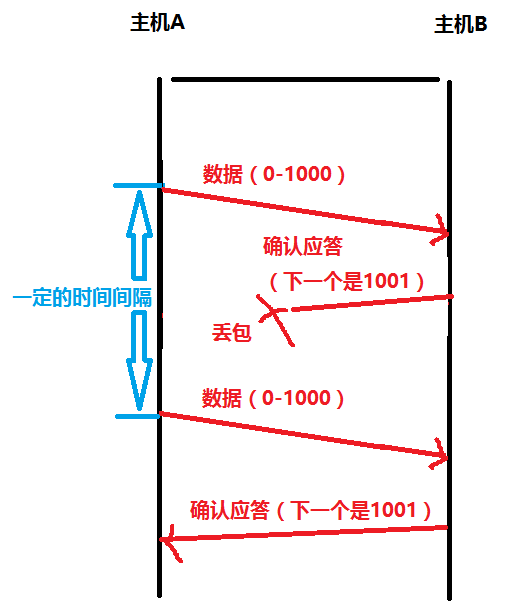
可想而知,这样主机B就会收到多个重复的数据,那么TCP协议需要能够识别出哪些包是重复的包,并且把重复的丢掉,这个时候利用前面的序列号,TCP发现这次发来的序列号之前已经收到过了,就将本次收到的序列号丢弃,可以很好的达到去重的效果
超时时长如何确定?
-
最理想的情况下,找到一个最小的时间,保证确认应答一定能在这个时间内返回
-
但是这个时间的长短,随着网络环境的不同,是有差异的
-
如果超时时间设的太长,会影响传输效率
-
如果超时时间设的太短,可能应答信息还在路上还没有送到就重发了,导致频繁的发重复的包
TCP为了保证无论在任何环境下都能比较高性能的通信,因此会动态的计算最大超时时间(指数增长)
-
Linux中,超时以500ms为一个单位进行控制,每次判定的超时重发的时间都是500ms的整数倍
-
如果重发一次,仍然得不到应答,等待2*500ms之后再进行重传
-
以此类推,下一次是等待4*500ms
-
累计一定的重传次数后,TCP认为网路或者对端主机出现异常,强制关闭连接(主动发送RST报文)
流量控制
接收端处理数据的速度是有限的。如果发送太快,导致接收端的缓冲区被打满,这个时候如果继续发送,就会造成丢包,继而引起丢包重传等等一系列连锁反应。
因此TCP根据接收端的处理能力,来决定发送端的发送速度,这就是流量控制
-
接收端将自己可以接收的缓冲区大小放到TCP首部中的窗口大小字段,通过ACK通知发送端还能接收多少
-
窗口大小字段越大,说明网络的吞吐量越大
-
接收端一旦发现自己的缓冲区快满了,就会将窗口大小设置成一个更小的值通知发送给发送端
-
发送端接收到这个窗口之后,就会减慢自己的发送速度
-
如果接收端缓冲区满了,就会将窗口大小设置为0,这时发送方不再发送数据,但是需要定期发送一个窗口探测数据段,使接收端把窗口大小告诉发送端
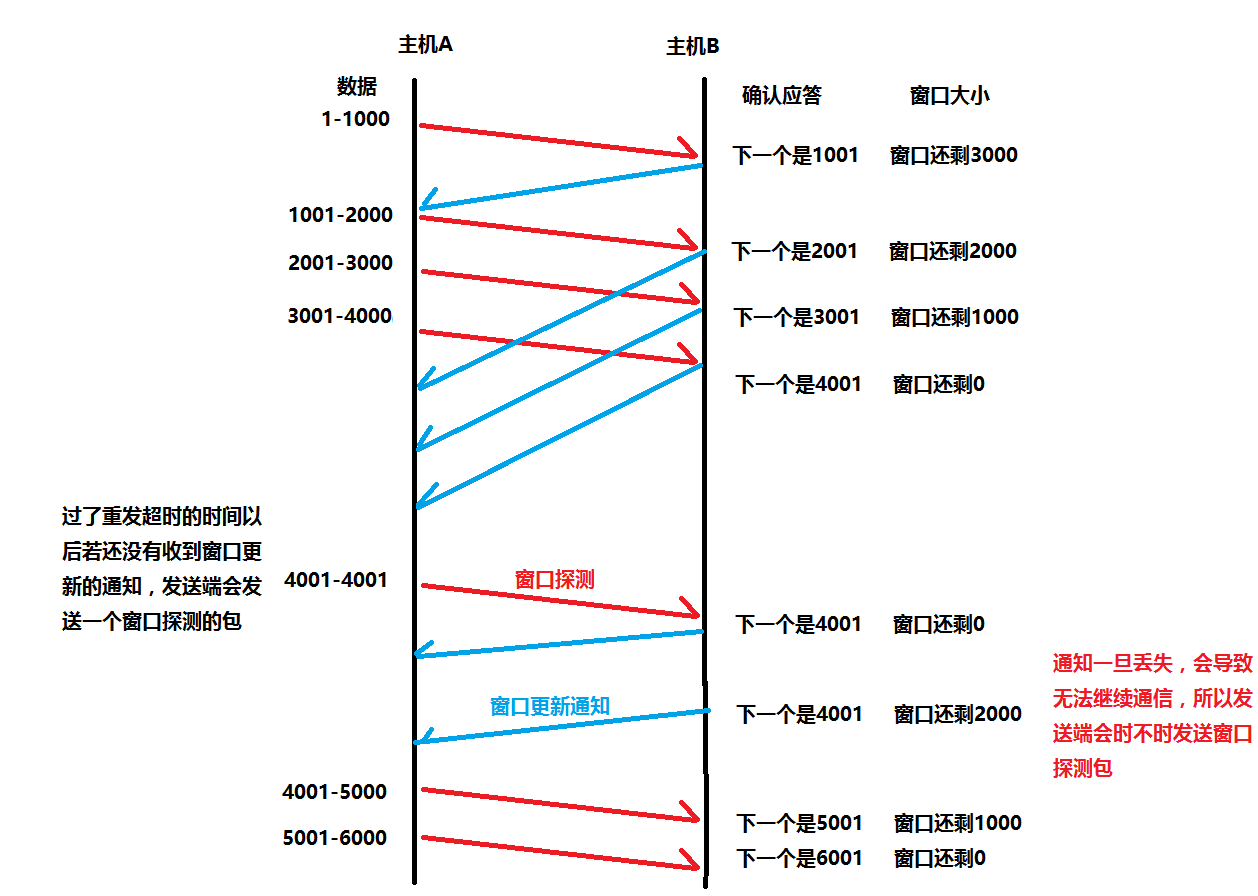
对于窗口的实际大小,其实并不是就是窗口大小直接设置的值,在选项字段中还有一个窗口扩大因子M,窗口的实际大小是窗口字段的值左移M位。
拥塞控制
如果在刚开始的阶段,就发送大量的数据,仍然会有拥塞的问题。因为网络上可能有大量的计算机,可能当前的网络状态就比较拥堵,在不清楚网络的状况下,立马发送大量数据是可能会造成拥塞状况的。
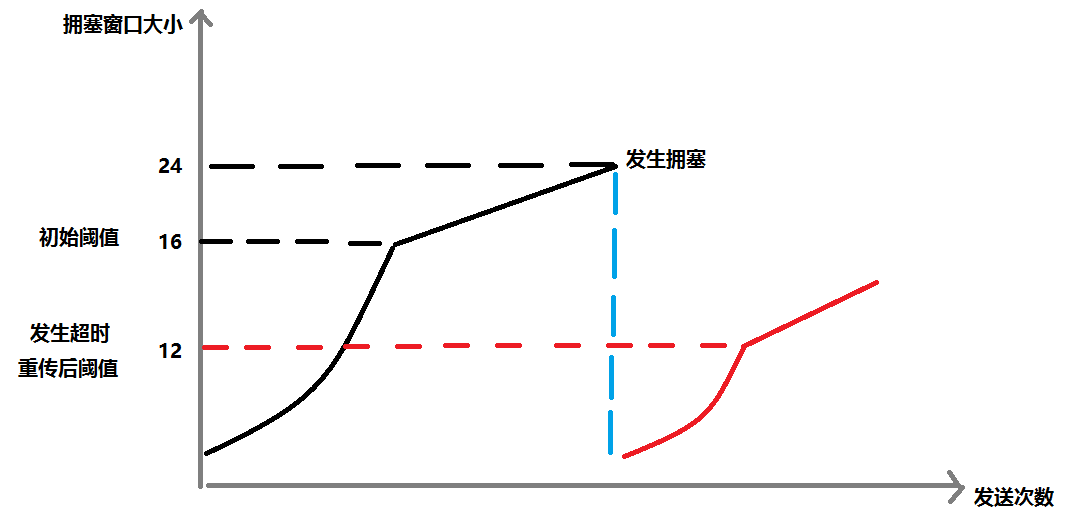
针对这个问题,TCP引入了慢启动机制,先发少量的数据探路,摸清楚当前的网络拥堵状态,再决定按照多大的速率传播。
-
引入了一个拥塞窗口的概念
-
开始发送数据时,定义拥塞窗口大小为1
-
每次收到一个ACK应答,拥塞窗口+1
-
每次发送数据包的时候,将拥塞窗口和接收端主机反馈的窗口大小做比较,取较小的值作为一次发送的值
如上的增长速度是指数级别的。注意:慢启动只是开始时慢,增长速度是很快的
-
为了不增长那么快,因此不能单纯的加倍
-
此处引入一个慢启动的阈值
-
当拥塞窗口超过这个阈值的时候,不再按照指数方式增长,而是按照线性方式增长
-
当TCP开始启动时,慢启动阈值等于窗口最大值
-
在每次发生拥塞的时候,慢启动阈值变为原来的一半,同时拥塞窗口置为1
发送端判断拥塞发生的依据有两个
-
传输超时,或者说是重传定时器溢出
-
收到重复的确认报文段
第一种情况,仍然使用慢启动和拥塞避免,如上图,只是将阈值减少
第二种情况,则采用快速重传(当收到三个连续的重复的确认报文段时,认为拥塞发生),此时发送端会重新发送重复的确认报文段要求的下一段数据。快速重传的具体机制请看下一篇博客TCP提高性能的机制
少量的丢包,仅仅造成超时重传;大量的丢包,就被认为是网络拥堵
拥塞堵塞,归根结底是TCP为了尽可能快的把数据传给对方,同时又要避免给网路造成太大压力的折中方案


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









