




 本文详细分析了ProxySQL的源码,重点探讨了MySQL_Thread::run方法中的data_stream和session处理流程,揭示了这两个关键步骤在整体流程中的核心作用。
本文详细分析了ProxySQL的源码,重点探讨了MySQL_Thread::run方法中的data_stream和session处理流程,揭示了这两个关键步骤在整体流程中的核心作用。
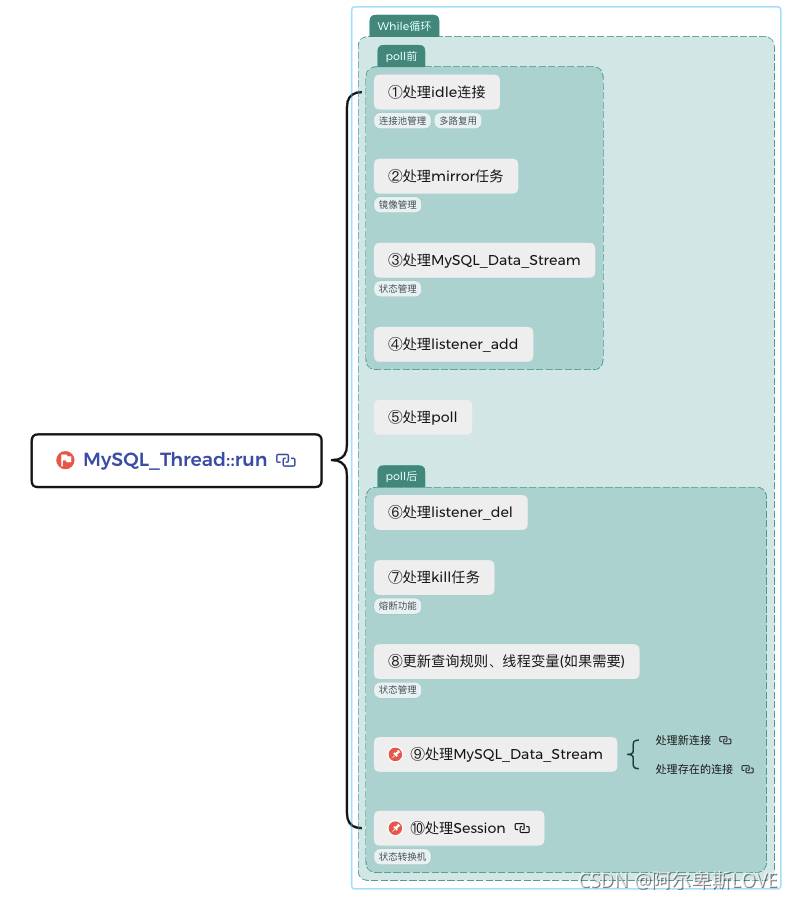
整体的流程图如上,其中最重要的就是最后2步,分别处理data_stream和session
void MySQL_Thread::run() {
// 死循环
while (shutdown == 0) {
// processing_idles初始化是false,上次检查时间大于ping的周期
if (processing_idles == false &&
(last_processing_idles < curtime - mysql_thread___ping_interval_server_msec * 1000)) {
// 管理idle的连接池,step1(连接池管理)
// 如果机器不是online的,这个机器上的连接直接回收
// 如果服务器上的连接大于最大连接,回收
// 如果服务器上的连接超过了一定水位,回收
// 如果连接超时了connection_max_age,回收
// 管理idle的连接池,step2(多路复用)
// 检查这些连接与后端的ping的状态,如果正常ping通,并且连接满足复用的条件则保留,否则就是回收连接并返回-1
run___get_multiple_idle_connections(num_idles);
}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









