 离散变量处理在机器学习中的策略
离散变量处理在机器学习中的策略





 本文探讨了在机器学习中如何处理离散变量,包括OneHotEncoder、DictVectorizer、Dummy、LabelEncoder和OrdinalEncoder等方法。重点介绍了各种方法的适用场景,例如OneHotEncoder适用于取值较少的离散变量,而LabelEncoder和OrdinalEncoder对于取值较多的离散变量更为合适。此外,还提供了实际操作的代码示例。
本文探讨了在机器学习中如何处理离散变量,包括OneHotEncoder、DictVectorizer、Dummy、LabelEncoder和OrdinalEncoder等方法。重点介绍了各种方法的适用场景,例如OneHotEncoder适用于取值较少的离散变量,而LabelEncoder和OrdinalEncoder对于取值较多的离散变量更为合适。此外,还提供了实际操作的代码示例。
背景
离散型变量在某些机器学习任务中经常出现,有时离散型变量是否能够充分使用直接关系到我们训练的模型性能。
虽然现在很多常用的机器学习方法都对离散型变量有了很好的支持,比如catboost、lightGBM等,但有时为了方便比较和尝试更多的模型方案,离散型变量的处理仍然是我们需要解决的问题。
本文的重点在于对现有的常用离散变量处理方法进行梳理,并提供相应的方法函数供读者参考。由于能力有限其中难免有所梳理,欢迎大家多多指教,共同学习、共同进步!
P.S. 由于精力有限,关于是什么和为什么的问题就不在此浪费时间讨论了,我们直接从怎么做入手开始我们今天的探讨。
概述
今天主要介绍以下几种方法,方法都是将离散变量(值为整数或者字符串)转换成大多数模型所支持的数值型变量。不仅提供了测试代码,还提供了工程上可实操的代码。至于其他的一些特殊的离散列编码方式如FC,目标列编码等,由于篇幅原因我们将新开一篇博客讨论。
| 方法一 OneHotEnCoder | 方法四 LableEncoder |
| 方法二 get_dummies | 方法五 OrdinalEncoder |
| 方法三 DictVectorizer | 方法六 dict直接映射 |
方法一二三主要是升维的方法,实际过程中尽量谨慎使用。
方法四五六则不需要升维,在离散变量取值较多时推荐使用。
数据
本文数据为比较典型的城市数据,维度(4942, 2),城市共有439个取值,我们看看这样的数据经过转换后会变成什么样子。
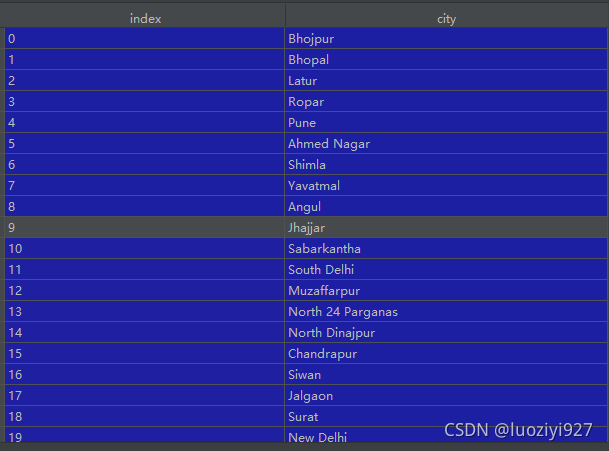
正文开始
方法一:OneHotEncoder
from sklearn.preprocessing import OneHotEncoder
oe = OneHotEncoder(sparse=False)
oe_res = oe.fit_transform(df[['city']])
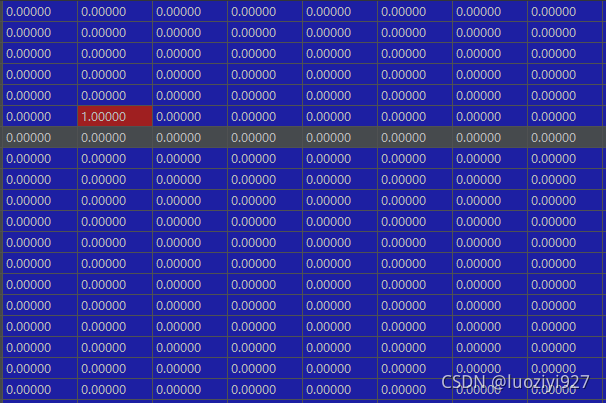
oe_res = pd.DataFrame(oe_res)df[['city']].shape
Out[39]: (4942, 1)
oe_res.shape
Out[40]: (4942, 440)可以看到当前的city变量被展开成了440列,每一列代表一个city的取值,高维稀疏。
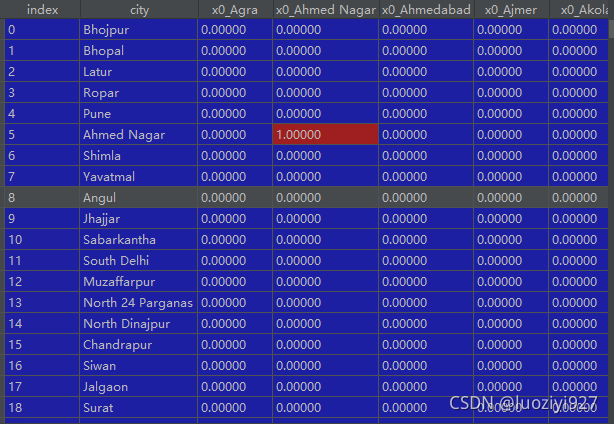
工程实操
工程上分两步:1.命名列名,2.拼接dataframe
from sklearn.preprocessing import OneHotEncoder
oe = OneHotEncoder(sparse=False)
oe_res = oe.fit_transform(df[['city']])
oe_res = pd.DataFrame(oe_res, columns=oe.get_feature_names())
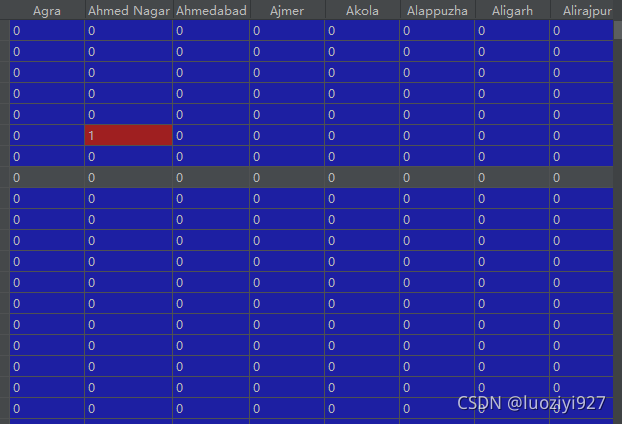
df = pd.merge(df, oe_res, left_index=True, right_index=True)最后效果是这样子的:会在原始数据集上多出很多列。可见这种方法在离散变量取值非常多的情况并不适用。
推荐在离散变量取值小于10时使用该方法。代码如下
def categorical2numerical(dfx, cat_cols, method=None):
if method == 'onehot':
oe_cols, err_cols = [], []
for col in cat_cols:
if dfx[col].nunique() < 10:
oe_cols.append(col)
else:
print('取值超过10不适合使用one hot')
err_cols.append(col) # 后续继续处理
oe = OneHotEncoder(sparse=False)
oe_res = oe.fit_transform(dfx[oe_cols])
oe_res = pd.DataFrame(oe_res, columns=oe.get_feature_names())
dfx = pd.merge(dfx.reset_index(), oe_res.reset_index(), left_index=True, right_index=True)
return dfx方法二:DictVectorizer
比较简单,话不多说直接应用
from sklearn.feature_extraction import DictVectorizer
dv = DictVectorizer(sparse=False)
dv_res = dv.fit_transform(df[['city']].to_dict(orient='record'))
de_res = pd.DataFrame(dv_res, columns=dv.feature_names_)
df = pd.merge(df, de_res, left_index=True, right_index=True)效果如下,可以看到最终效果和onehot没什么区别一样的440列。应用上应该也区别不大。
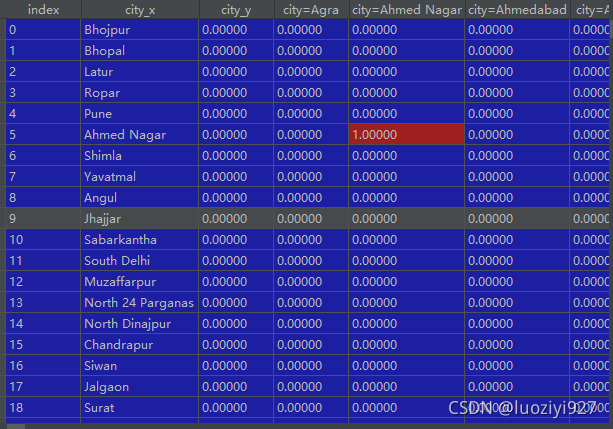
方法三:Dummy
很简单只需要一行代码
dm = pd.get_dummies(df['city'], columns=df['city'].nunique())效果和上面两个是一样的。
方法四\五 LabelEncoder\OrdinalEncoder
代码如下,转换结果也一致,推荐直接使用OrdinalEncoder
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le_res = pd.DataFrame(le.fit_transform(df[['city']]))
le_res = le_res.T
from sklearn.preprocessing import OrdinalEncoder
oe = OrdinalEncoder()
oe_res = pd.DataFrame(oe.fit_transform(df[['city']].fillna('nan')))
res = pd.merge(le_res, oe_res, left_index=True, right_index=True)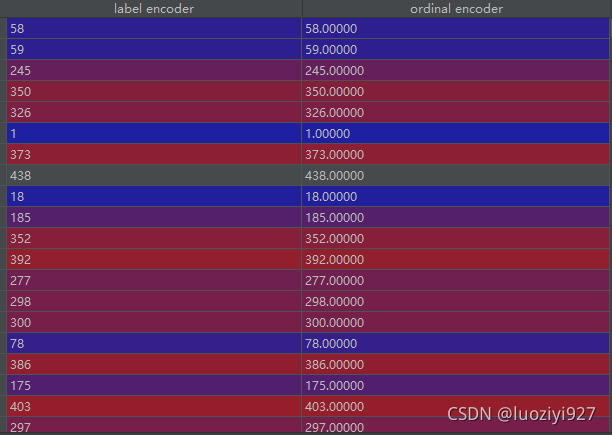
方法六:Dict替换
比较简单,举个栗子吧。
resdf['user_stat'] = resdf['user_stat'].replace({'active': 1.0, 'inactive': 0.0})

















 530
530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









