



1 获取更多数据
这是解决过拟合最有效的方法,只要给足够多的数据,让模型“看见”尽可能多的“例外情况”,它就会不断修正自己,从而得到更好的结果。
如何获取更多的数据:
(1)从数据源头获取更多数据
(2)根据当前数据集估计数据分布参数,使用该分布产生更多数据(这个一般不用,因为估计分布参数的过程也会代入抽样误差)
(3)数据增强(data augmentation):通过一定规则扩充数据。如在物体分类问题里,物体在图像中的位置、姿态、尺度,整体图片明暗度等都不会影响分类结果。我们就可以通过图像平移、翻转、缩放、切割等手段将数据库成倍扩充。
2 选择合适的模型
过拟合主要是有两个原因造成的:数据太少+模型太复杂。所以,我们可以通过使用合适复杂度的模型来防止过拟合问题。
对于神经网络而言,我们可以从一下四个方面来限制网络能力:
2.1 网络结构 Architecture
减少网络的层数、神经元个数等均可以限制网络的拟合能力。例如 drop out
2.2 训练时间 Early stopping
对于每个神经元而言,其激活函数在不同区间的性能是不同的:
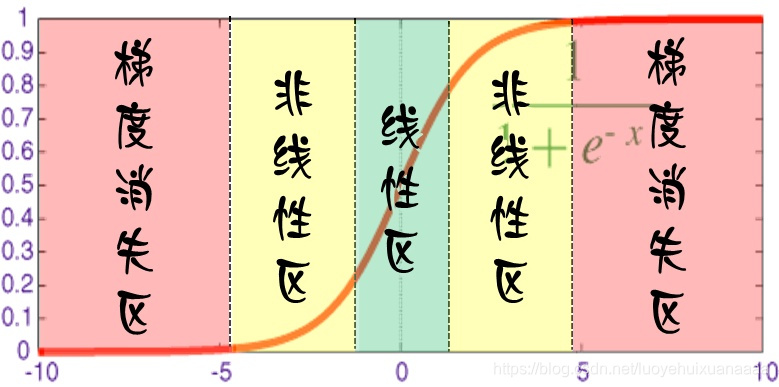
当网络权值较小时,神经元的激活函数工作在线性区,此时神经元的拟合能力较弱(类似线性神经元)。
我们就可以解释为什么限制训练时间有用:因为我们在初始化网络的时候,一般都是初始为较小的权值。训练时间越长,部分网络权值可能越大。如果我们在合适时间停止训练,就可以将网络的能力限制在一定范围内。
2.3 限制权值 weight-decay,也叫正则化(regularization)
原理同上,但是这类方法直接将权值的大小加入到Cost里,在训练的时候限制权值变大。
2.4 增加噪声
(1)在输入加入噪声
(2)在权值上加噪声
(3)对网络的相应加噪声
3 结合多种模型
简而言之,训练多个模型,以每个模型的平均输出作为结果。
3.1 Bagging
简单理解,就是分段函数的概念:用不同的模型拟合不同部分的训练集。以随机森林为例,就是训练了一堆互不关联的决策树。
3.2 boosting
既然训练复杂神经网络比较慢,那我们就可以只使用简单的神经网络(层数、神经元限制等)。通过训练一系列简单的神经网络,加权平均其输出。
3.3 Dropout
4 贝叶斯方法


















 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









