







第四十八周学习笔记
论文阅读概述
- Attention is All You Need:This article introduce a novel language model Transformer feeding word embedding with position embedding to multi-layer encoders and decoders to get contextual feature based only on attention mechanism, which can process sequence parallelly and address (super) long-term dependency in sequence.
- BERT:Pre-training of Deep Bidrectional Transformers for Language Understanding: This article introduce a novel pre-trained language model BERT which is composed of bidirectional Transformer and exploit text dataset to pre-train on two tasks unsupervisely——cloze and next sentence prediction to make model able to capture word-level and sentence-level understanding of nature language. Authors then fine-tune model on specific NLP tasks and achieve SoTA on 11 tasks.
- XLNet:Generalized Autoregressive Pretraining for Language Understanding: This article introduce a novel pre-trained language model XLNet which use auto regressive architecture with permutation and two-stream self-attention to make use of advantages of BERT and eliminate the [MASK] problem. Achieve SoTA on 18 tasks and beat BERT on 20 tasks.
- Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning: This article introduce a novel image captioning model named Adaptive Attention. It proposes a visual sentinel to tell model when to refer to visual information and when not.
- Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering: This article introduce a novel image captioning feature known as Top-Down feature by using the region proposal feature of faster rcnn. It combines Top-down and bottom-up attention to achieve SoTA performance on both image captioning and Visual question answering.
- SPICE:Sementic Propositional Image Caption Evaluation:This article introduce a new auto metric SPICE by measuring the similarity of scene graph of candidate and reference to reveal the semantic consistence which shows high correlation with human judgement
- Learning to Evaluate Image Captioning: This article introduce a learned metric for image captioning by using discriminator to judge like GAN and perform better than traditional metric
- Regularizing RNNs for Caption Generation by Reconstructing The Past with The present: This article introduce a reconstruction layer in image captioning model to target at making current hidden state able to reconstruct last one with a single full-connected layer to force hidden state embed more information of past, Achieving a little improvement
- Discriminability objective for training descriptive captions: This article introduce a novel loss to measure the discriminability between captions of different image. It trains a captioner with the guide of this loss by using REINFORCE to generate diverse and discriminative captions. Reduce the “play it safe” problem of captioner to some extent.
- Convolutional Image Captioning: This article introduce a CNN-based image captioning decoder to address the drawbacks of lstm-based one like sequencial property and unablility of (super) long-term dependencies, achieving comparable results with lstm-based model.
- StyleNet:Generating Attractive Visual Captions with Styles: This article introduce a novel image captioning model StyleNet to simultaneously generate multi-style caption by one model and train on paired factual data and unpaired style data by factored LSTM, generating more attractive caption according to human judgement
Intuition building
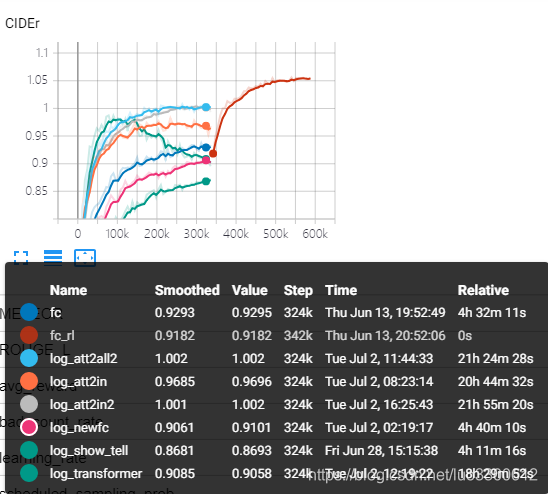
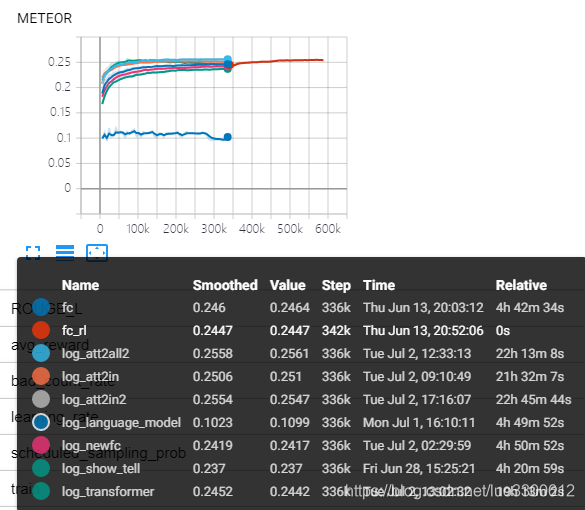
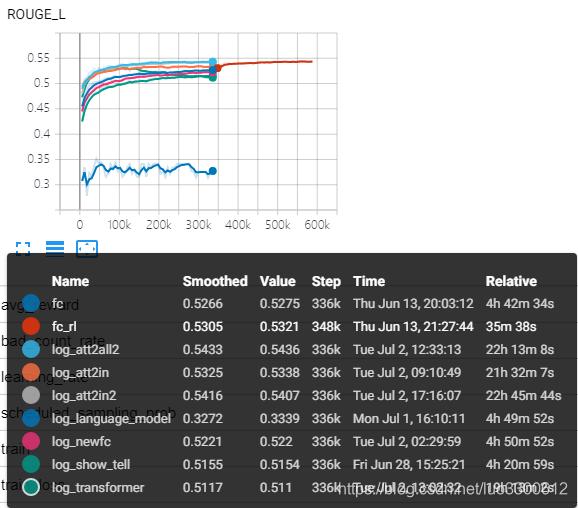
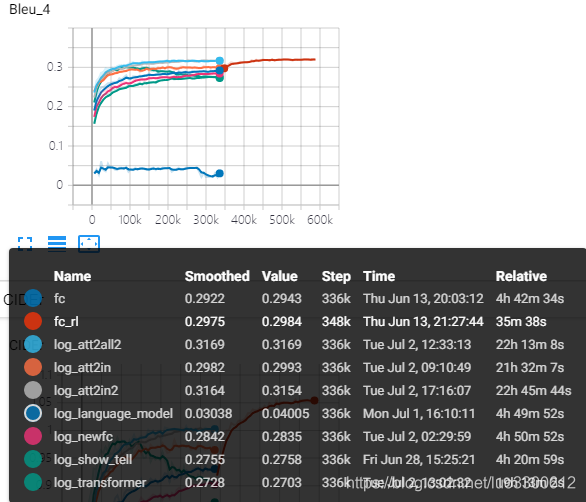
对常见的部分image captioning model的运行结果如下
下周目标
- 读完17-19年image captioning的CVPR论文
- 整理近年来的SoTA image captioning model
- 整理先前阅读的所有论文
- 整理论文的书写方法
- 记录重要的引用文献
- 研究CIDEr optimization和top-down model的细节
- 所有模型跑一个CIDEr optimization的版本
- 跑基于top-down feature的模型

















 1331
1331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









