




 本文提出了一种基于策略梯度的图像描述训练方法——自我批评序列训练(SCST),该方法通过强化学习优化CIDEr度量,有效解决了传统模型在训练与测试阶段的不一致问题,实验证明其在MSCOCO数据集上取得了显著效果。
本文提出了一种基于策略梯度的图像描述训练方法——自我批评序列训练(SCST),该方法通过强化学习优化CIDEr度量,有效解决了传统模型在训练与测试阶段的不一致问题,实验证明其在MSCOCO数据集上取得了显著效果。
Self-critical Sequence Training for Image Captioning
时间:2017
Intro
近年来策略梯度(policy-gradient)在训练深度端到端系统上展现了它的能力,它可以以不可导的度量作为目标函数,本文考虑的问题就是使用强化学习来训练image captioning模型,称为self-critical sequence training(SCST),它是一种REINFORCE算法,但它不使用baseline来正规化rewards以减小方差,而是使用新的test-time inference算法来正规化reward,我们发现在测试时使用贪婪解码直接优化CIDEr的效率十分高,最终模型将CIDEr从104.9提升到了114.7
传统的nlg模型往往以最大化似然函数作为目标,但这使得训练和测试之间出现了断层,因为测试是的时候模型使用的是之前预测的词来预测下一个词,这个exposure bais使用错误在测试的时候不断累积。模型在训练时的交叉熵损失和测试时使用的BLEU,ROUGE,METEOR,CIDEr等度量也存在不一致性
Caption Models
FC Models,图片编码器使用一个CNN,然后用线性映射
W
I
W_I
WI映射到词向量空间中,以这个向量作为第一个输入的词:
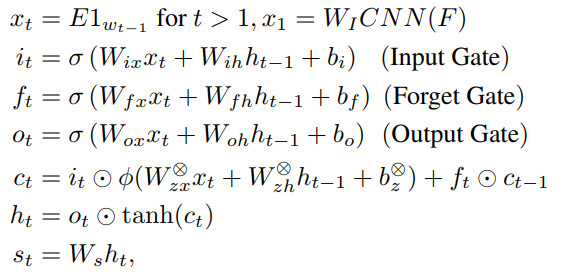
其中
ϕ
\phi
ϕ是2单元的maxout函数,
○
×
○×
○×代表单元,
σ
\sigma
σ戴氏sigmoid函数,模型输出
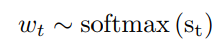
记
θ
\theta
θ为模型的参数,通常模型是在交叉熵(XE)上优化
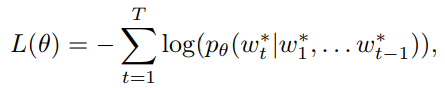
Attention Model(Att2in),attention特征仅输入到cell node中
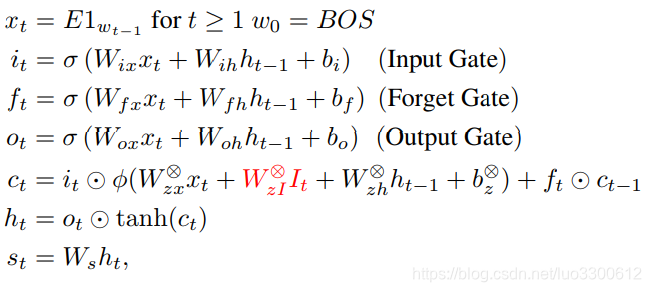
其中
I
t
I_t
It是attention feature,对于N个不同位置的特征,它计算为
I
t
=
∑
i
=
1
N
α
t
i
I
i
I_t = \sum_{i=1}^{N}\alpha^i_tI_i
It=i=1∑NαtiIi
α t = softmax ( a t + b α ) \alpha_t=\text{softmax}(a_t+b_\alpha) αt=softmax(at+bα)
a t i = W t a n h ( W a I I i + W a h h t − 1 + b a ) a^i_t = Wtanh(W_{aI}I_i+W_{ah}h_{t-1}+b_a) ati=Wtanh(WaIIi+Wahht−1+ba)
Reinforcement Learning
形式化,用RL的术语描述整个任务
- agent:LSTM
- environment:words和image features
- policy:模型参数 θ \theta θ决定policy p θ p_\theta pθ
- reward:生成句子的CIDEr
训练的目标是最小化负期望回报
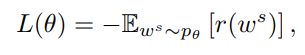
REINFORCE策略梯度算法,REINFORCE策略梯度为
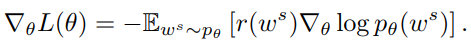
实践中通常使用一个Monte-Carlo采样来估计均值
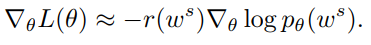
REINFORCE with a Baseline,为了减少方差,REINFORCE可以引入Baseline
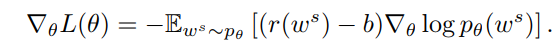
同样使用单个采样来估计
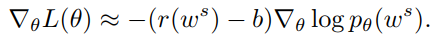
Final Gradient Expression,最终的梯度为
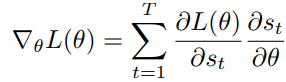
其中
s
t
s_t
st是softmax函数的输入,
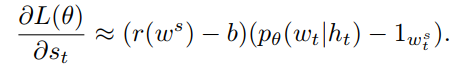
Self-critical sequence training(SCST)
SCST的核心思想是用当前模型在inference时的reward来baseline REINFORCE算法,
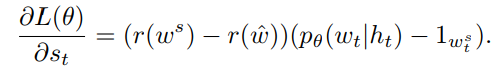
其中
r
(
w
^
)
r(\hat{w})
r(w^)是当前模型在测试时得到的reward
Experiments
使用XE训练的模型作为预训练模型,结果如表所示
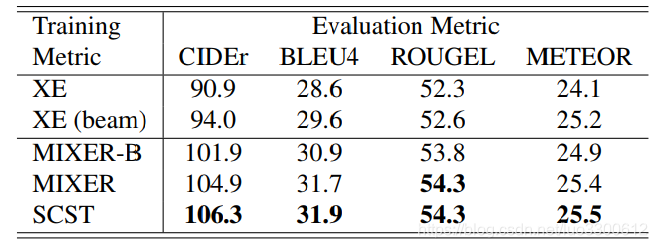
在不同的度量上训练
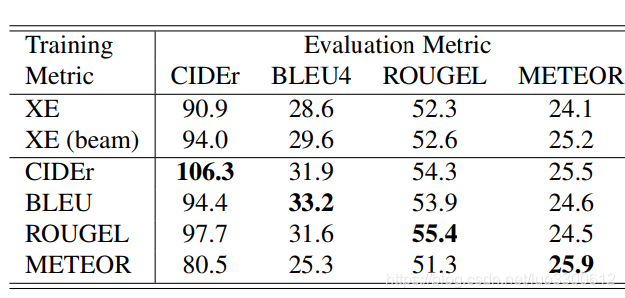
可见在CIDEr上训练的效果最好
结论
本文给出了一个基于策略梯度的image captioning训练方法,在MSCOCO上达到了SoTA的效果

















 1997
1997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









