




 本文提出了一种基于三流LSTM的密集关系字幕生成方法,通过捕捉图像中每对物体之间的关系,实现了更丰富的场景描述。模型利用区域提议网络生成物体候选,结合几何信息和POS辅助,有效提升了caption生成的准确性和连贯性。
本文提出了一种基于三流LSTM的密集关系字幕生成方法,通过捕捉图像中每对物体之间的关系,实现了更丰富的场景描述。模型利用区域提议网络生成物体候选,结合几何信息和POS辅助,有效提升了caption生成的准确性和连贯性。
Dense Relational Captioning:Triple-Stream Networks for Relationship-Based Captioning
时间:2019 CVPR
Intro
本文要解决的问题是dense caption,通过寻找每对object之间的关系来进行caption生成
Approach
给一张图片,RPN生成object proposals,然后结合层接受一对输入(subject,object),同时接受它们的并集区域作为输入,这个三元组(subject,object,union)然后输入到triple-stream LSTM中,生成caption和每个词的POS,整个模型如图所示
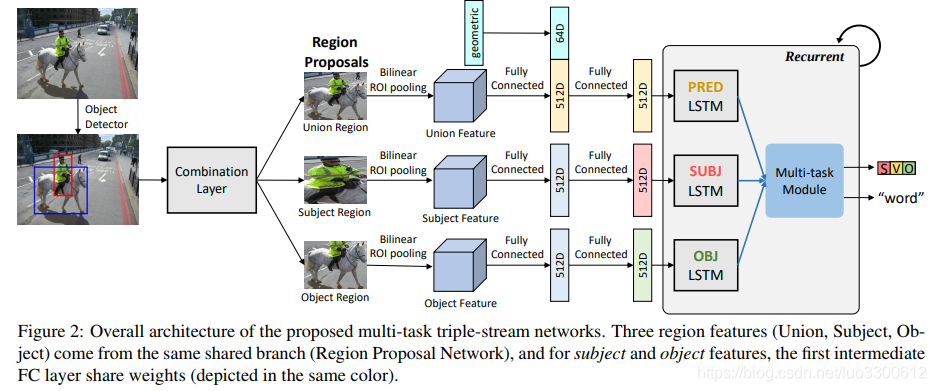
Region Proposal Networks
为了得到subject,object,只需要将所有proposal组成二元组即可,总共B(B-1)个二元组,除此以外,上图中的geometric提供了两个subject和object在union中的相对位置
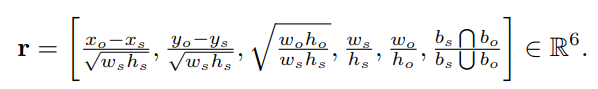
Relational Captioning Networks
模型结构如图所示
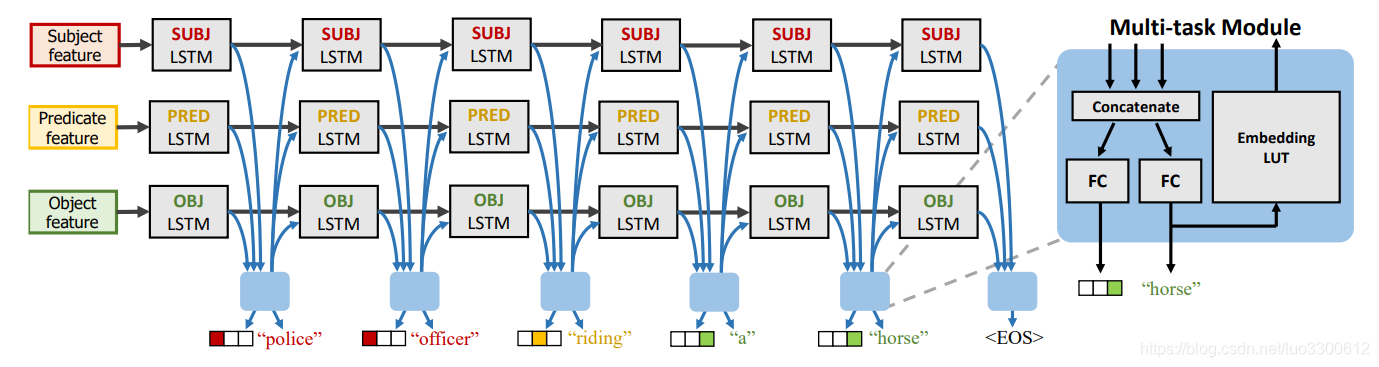
Triple-Stream LSTMs
三部分输入分别进入一个LSTM来预测,得到的结果融合起来生成下一个词
Multi-task with POS Classification
通常的relation captioning的生成词的词性总是按照subj-pred-obj的顺序,我们在生成词的时候同时预测POS,鼓励生成的caption遵循这个规则,来做一个multi-task学习
损失函数
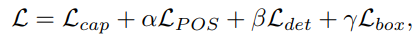
由caption loss,POS 分类loss,detection loss和bounding box regression loss组成
结果
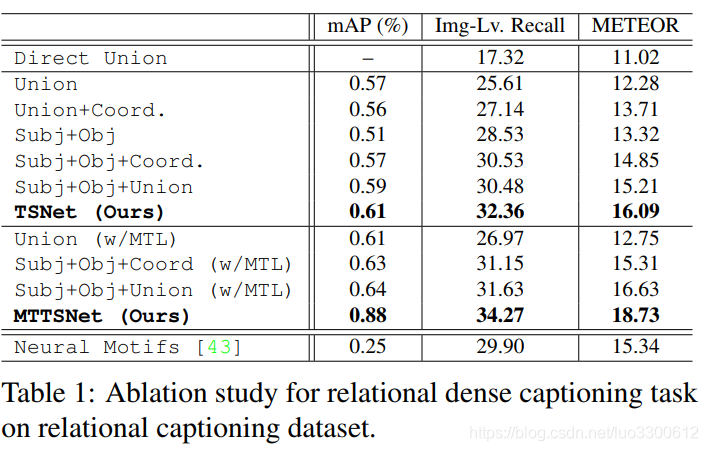

结论
本文提出了multi task triple stream Net,针对图中每对proposal利用了POS辅助image captioning,得到了较好的结果

















 3401
3401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









