







 本文详细介绍了JVM的运行参数,包括标准参数、非标准参数和XX参数的使用,如-Xms、-Xmx、-XX:NewRatio等,并讲解了JVM的堆内存模式,包括JDK1.7和1.8的区别。此外,还探讨了线程状态、VisualVM工具的使用和垃圾回收算法,如引用计数法、标记清除法、标记压缩算法等,并提及了各种垃圾收集器的工作原理和应用场景。
本文详细介绍了JVM的运行参数,包括标准参数、非标准参数和XX参数的使用,如-Xms、-Xmx、-XX:NewRatio等,并讲解了JVM的堆内存模式,包括JDK1.7和1.8的区别。此外,还探讨了线程状态、VisualVM工具的使用和垃圾回收算法,如引用计数法、标记清除法、标记压缩算法等,并提及了各种垃圾收集器的工作原理和应用场景。
JVM虚拟机优化
1. JVM的运行参数
jvm中有很多参数可以设置,这样可以使jvm在各种环境中都能够高效的运行。绝大部分的参数保持默认即可。
-
JVM的三种参数类型
- 标准参数:顾名思义,标准参数中包括功能和输出的参数都是很稳定的,很可能在将来的 JVM 版本中不会改变。你可以用 java 命令(或者是用 java -help)检索出所有标准参数。
- -help:
- -version:
- -X参数(非标准参数):非标准化的参数在将来的版本中可能会改变。所有的这类参数都以 - X 开始,并且可以用 java -X 来检索。注意,不能保证所有参数都可以被检索出来,其中就没有 - Xcomp。例如:
- -Xint
- -Xcomp
- -XX参数(使用率高, 非标准参数):它们同样不是标准的,甚至很长一段时间内不被列出来(最近,这种情况有改变 ,我们将在本系列的第三部分中讨论它们)。然而,在实际情况中 X 参数和 XX 参数并没有什么不同。X 参数的功能是十分稳定的,然而很多 XX 参数仍在实验当中(主要是 JVM 的开发者用于 debugging 和调优 JVM 自身的实现)。 例如:
- -XX:newSize
- -XX:+UserSerialGC
- 标准参数:顾名思义,标准参数中包括功能和输出的参数都是很稳定的,很可能在将来的 JVM 版本中不会改变。你可以用 java 命令(或者是用 java -help)检索出所有标准参数。
-
标准参数:
-
java -help
-
-server 和 -client参数
可以通过-server或-client设置jvm的运行参数。
- 他们的区别是Server VM的初始堆内存会大一点,默认使用的是并行垃圾回收器,启动慢运行快
- Client VM相对来讲会更加保守,初始堆内存会小一点,使用串行垃圾回收器,启动快运行慢。
- JVM启动的时候会根据硬件和操作系统自动选择Server还是Client的JVM
- 32位操作系统
- 如果是Windows系统,不论硬件配置如何,都默认使用Client类型的VM
- 如果是其他操作系统,机器配置有2GB以上的内存同时有2个以上的CPU默认使用Server模式,否则Client模式。
- 64位操作系统
- 只支持Server模式,使用-client会不生效。
- 32位操作系统
[root@node test]java -client -showversion TestJVM java version "1.8.0_141"
-
-
-X参数:
[root@node test] java -X -Xmixed 混合模式执行 (默认) -Xint 仅解释模式执行 -Xbootclasspath:<用 ; 分隔的目录和 zip/jar 文件> 设置搜索路径以引导类和资源 -Xbootclasspath/a:<用 ; 分隔的目录和 zip/jar 文件> 附加在引导类路径末尾 -Xbootclasspath/p:<用 ; 分隔的目录和 zip/jar 文件> 置于引导类路径之前 -Xdiag 显示附加诊断消息 -Xnoclassgc 禁用类垃圾收集 -Xincgc 启用增量垃圾收集 -Xloggc:<file> 将 GC 状态记录在文件中 (带时间戳) -Xbatch 禁用后台编译 -Xms<size> 设置初始 Java 堆大小 -Xmx<size> 设置最大 Java 堆大小 -Xss<size> 设置 Java 线程堆栈大小 -Xprof 输出 cpu 配置文件数据 -Xfuture 启用最严格的检查, 预期将来的默认值 -Xrs 减少 Java/VM 对操作系统信号的使用 (请参阅文档) -Xcheck:jni 对 JNI 函数执行其他检查 -Xshare:off 不尝试使用共享类数据 -Xshare:auto 在可能的情况下使用共享类数据 (默认) -Xshare:on 要求使用共享类数据, 否则将失败。 -XshowSettings 显示所有设置并继续 -XshowSettings:all 显示所有设置并继续 -XshowSettings:vm 显示所有与 vm 相关的设置并继续 -XshowSettings:properties 显示所有属性设置并继续 -XshowSettings:locale 显示所有与区域设置相关的设置并继续 -X 选项是非标准选项, 如有更改, 恕不另行通知。-
-Xint,-Xcomp,-Xmixed
- 在解释模式(interpreted mode)下,-Xint会强制JVM执行所有的字节码,这当然会降低运行速度,通常低10倍或更多。
- -Xcomp参数与-Xint刚好相反,JVM会在第一次使用时候把所有字节码编译成本地代码,从而带来最大程度的优化。
- 然而,很多应用在使用-Xcomp也会有一些性能损失,当然比使用-Xint损失的少,原因是-Xcomp没有让JVM启用IT编译器的全部功能。JIT编译器可以对是否需要编译做判断,如果所以在代码都进行编译的话,对于一些只执行一次的代码就没有意义了。
- -Xmixed是混合模式,将解释模式与编译模式进行混合使用,由JVM自己决定,这是jvm的默认模式,也是推荐使用的模式。
- 混合使用解释器+热点代码编译
- 起始阶段采用解释执行
- 热点代码检测
# 强制设置为解释模式 java -showversion -Xint TestJVM # 强制设置为编译模式 java -showversion -Xcomp TestJVM #注意,编译模式下,第一次执行会比解释模式下执行慢一些,注意观察
-
-
-XX参数
- -XX参数也是非标准参数,主要用于JVM的调优和debug操作。
- -XX参数的使用有两种方式,一种是boolean类型,一种是非boolean类型:
- boolean类型:
- 格式:-XX:[±]表示启用或禁用属性
- 如:-XX:+DisableExplicitGC表示禁止手动调用gc操作,也就是说调用System.gc()无效
- 非boolean类型
- 格式:-XX:=表示属性的值为
- 如:-XX:NewRation=1表示新生代和老年代的比值
- boolean类型:
-
-Xms和-Xmx参数
-Xms与-Xmx分别是设置jvm的堆内存的初始大小和最大大小。
-Xmx2048m:等价于-XX:MaxHeapSize,设置JVM最大堆内存为2048M。
-Xms512m:等价于-XX:InitialHeapSize,设置JVM初始堆内存为512M。
java -Xms512m -Xmx2048m TestJVM -
查看JVM的运行参数
有时候我们需要查看jvm的运行参数,这个需求可能会存在2中情况:
第一:运行java命令式打印出运行参数;
第二:查看正在运行的java进程的参数;
- 运行java命令式打印参数:-XX:+PrintFlagFinal参数即可。打印结果中参数有boolean类型和数字类型,值的操作符是=或:=,分别代表默认值和被修改的值。
- 查看正在运行的jvm参数:jinfo命令查看。
2. JVM的堆内存模式
- JDK1.7的堆内存模型

-
Yong年轻代
Young区被划分成三部分,Eden区和两个大小严格相同的Survivor区,其中,Survivor区间中,某一时刻只有其中一个是被使用的,另外一个留作垃圾收集时复制对象用,在Eden区间变满的时候,GC就会将存活的对象移到空闲的Survivor区间中,根据JVM的策略,再进过几次垃圾收集后,仍然存活于Survivor的对象将被移动到Tenured区间。
-
Tenured年老区(代)
Tenured区主要保存生命周期长的对象,一般是一些老的对象,当一些对象在Young复制转移一定的次数以后,对象就会被移到Tenured区,一般如果系统中用了application级别的缓存,缓存中的对象往往会被转移到这一区间。
-
Perm永久区
Perm区主要保存class,method,filed对象,这部分的空间一般不会溢出,除非一次性加载了很多的类,不过在涉及到热部署的应用服务器的时候,有时候会遇到java.lang.OutOfMemoryError:PermGen space 的错误,造成这个错误的很大原因就可能是每次都重新部署,但是重新部署后,类的class没有被卸载掉,这样就造成了大量的class对象保存在perm中,这种情况下,一般重新启动应用服务器可以解决问题。
-
Virtual区
最大内存和初始内存的差值,就是Virtual区。
-
JDK1.8的堆内存模型

由上图可以看出,jdk1.8的内存模型是由两个部分组成,年轻代+老年代。
年轻代:Eden+2*Survivor
年老代:OldGen
在jdk1.8中最大的变化就是Perm区,被Metaspace(元数据空间)替代了
需要特别说明的是:Metaspace所占用的内存空间不是在虚拟机内部,而是在本地内存空间中,这也是与1.7永久代最大的差异
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nL6pX8JI-1623774592125)(D:\My_Life\Java\学习笔记\Snipaste_2021-06-13_15-34-58.png)]](https://i-blog.csdnimg.cn/blog_migrate/df3e1a64d8f3007fb364be3dc195899b.png)
为什么要废除永久区?
在现实使用中,由于永久代内存经常不够用或发生内存泄漏,爆出异常java.lang.OutOfMemoryError:PermGen。基于此,将永久区废弃,而改用元空间,改为了使用本地内存空间。这也是为了融合Hot Spot JVM与JRockit VM而做出的努力,因为JRockit没有永久代,因此不需要配置永久代。
-
通过jstat命令进行查看堆内存使用情况
jstat命令可以查看堆内存各部分的使用量,以及加载类的数量,命令格式如下:
jstat [-命令选项] [vmid] [间隔时间/毫秒] [查询次数]
-
查看class加载统计
# jps 7080 jps 6219 Bootstrap # jstat -class 6219 Loaded Bytes Unloaded Bytes Time 3273 7122.3 0 0.0 3.98说明:
- Loaded:加载class的数量了
- Bytes:所占用空间的大小
- Unloaded:未加载数量
- Bytes:未加载占用空间
- Time:时间
-
查看编译统计:jstat -compiler
# jstat -compiler 6219 compiled Failed Invalid Time FailedType FailedMethod 2379 1 0 8.04 1 org/apache/tomcat/util/IntrospectionUtilssetProperty- Compiled:编译数量
- Failed:失败数量
- Invalid:不可用数量
- Time:时间
- FailedType:失败类型
- FailedMethod:失败的方法
-
垃圾回收统计
# jstat -gc 6219 S0C S1C S1U S1U EC EU 0C 0U MC MU CCSC CCSU YGC YGCT FGC FGCT GCT- SOC: 第一个Survivor区的大小
- S1C : 第二个Surivior区的大小
- S0U:第一个Surivior区的使用大小
- S1U:第二个Suriviro区的使用大小
- EC:Eden区的大小(KB)
- EU:Eden区的使用大小(KB)
- OC:Old区大小(KB)
- OU:Old使用大小(KB)
- MC:方法区大小(KB)
- MU:方法区使用大小(KB)
-
jmp的使用以及内存溢出分析
前面通过jstat可以对jvm堆的内存进行统计分析,而jmap可以获取到更加详细的内容,如:内存使用情况的汇总,对内存溢出的定位与分析
C:\Users\jjs>jmap -heap 5932 Attaching to process ID 5932, please wait... Debugger attached successfully. Server compiler detected. JVM version is 25.91-b15 using thread-local object allocation. Parallel GC with 4 thread(s) Heap Configuration: MinHeapFreeRatio = 0 MaxHeapFreeRatio = 100 MaxHeapSize = 1073741824 (1024.0MB) NewSize = 42991616 (41.0MB) MaxNewSize = 357564416 (341.0MB) OldSize = 87031808 (83.0MB) NewRatio = 2 SurvivorRatio = 8 MetaspaceSize = 21807104 (20.796875MB) CompressedClassSpaceSize = 1073741824 (1024.0MB) MaxMetaspaceSize = 17592186044415 MB G1HeapRegionSize = 0 (0.0MB) Heap Usage: PS Young Generation Eden Space: capacity = 60293120 (57.5MB) used = 44166744 (42.120689392089844MB) free = 16126376 (15.379310607910156MB) 73.25337285580842% used From Space: capacity = 5242880 (5.0MB) used = 0 (0.0MB) free = 5242880 (5.0MB) 0.0% used To Space: capacity = 14680064 (14.0MB) used = 0 (0.0MB) free = 14680064 (14.0MB) 0.0% used PS Old Generation capacity = 120061952 (114.5MB) used = 19805592 (18.888084411621094MB) free = 100256360 (95.6119155883789MB) 16.496143590935453% used 20342 interned Strings occupying 1863208 bytes. -
查看内存中对象数量和大小:jmap -histo | more
查看活跃对象:jmap -histo | more
- B byte
- C char
- D double
- F float
- I int
- J long
- Z boolean
- [ 数组,如[I表示int[] ] ]
- [L+类名 其他对象]
-
将内存使用情况dump到文件中
有些时候我们需要将jvm当前内存中的情况dump到文件中,然后对他进行分析,jmap也是支持dump到文件中的
jmap -dump:format=b,file=dumpFileName <pid>我们将jvm的内存dump到文件中,这个文件是一个二进制的文件,不方便查看,我们可以借助jhat工具查看
jhat -port 9999 /tmp/dump.dat打开浏览器本地9999端口进行查看
或者我们也可以使用MAT工具进行查看
-
3. 线程
-
线程状态
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rSyz6Umg-1623774592127)(D:\My_Life\Java\学习笔记\Snipaste_2021-06-13_16-17-22.png)]](https://i-blog.csdnimg.cn/blog_migrate/c089e84a2d850d3a700e98071146fd5c.png)
在java中线程的状态一般分为6种:
- 初始态(NEW)
- 创建一个Thread对象,但还未调用start()启动线程时,线程处于初始态
- 运行态(RUNNABLE),在Java中,运行态包括就绪态和运行态
- 就绪态:
- 该状态下线程已经获得执行所需要的所有资源,只要CPU分配执行权就能运行
- 所有就绪态的线程存放在就绪队列中
- 运行态
- 获得CPU执行权,正在执行的线程
- 由于一个CPU同一时刻只能执行一条线程,因此每个CPU每个时刻只有一条运行态的线程
- 就绪态:
- 阻塞态(BLOCKED)
- 当一条正在执行的线程请求某一资源失败的时候,就会进入阻塞状态
- 在Java中,阻塞态专指请求锁失败时候进入的状态
- 有一个阻塞队列存放所有阻塞态的线程
- 处于阻塞态的线程会不断请求资源,一旦请求成功,就会进入到就绪状态,等待执行
- 等待态(WAITING)
- 当前线程中调用wait,join函数时,当前线程就会进入等待态
- 也有一等待队列存放所有的等待态线程
- 线程处于等待态表示他需要等待其他线程的指示才能继续运行
- 进入等待状态的线程会释放CPU执行权,并释放资源(如:锁)
- 超时等待态(TIMED_WAITING)
- 当运行中的线程调用sleep(time)、wait、join、parkNanos、parkUntil时候,就会进入该状态
- 它和等待态一样,并不是因为请求不到资源,而是主动进入,并且进入后需要其他线程唤醒
- 进入该状态后释放CPU执行权和占有的资源
- 与等待态的区别:到了超时时间后自动进入阻塞队列,开始竞争锁
- 终止态(TERMINATED)
- 线程执行结束后的状态
- 初始态(NEW)
4. VisualVM工具的使用
Visual VM能够监控线程,内存情况,查看方法的CPU时间和内存中的对象,已被GC的对象,反向查看分配的堆栈(如100个string对象分别由哪几个对象分配出来的)
-
监控本地tomcat
-
监控远程tomcat:借住JMX技术实现
- JMX是一个为应用程序,设备,系统等植入管理功能的框架。JMX可以跨越一系列异构操作系统平台,系统体系结构和网络传输协议,灵活的开发无缝集成的系统,网络,和服务管理应用。
-
想要监控远程tomcat,就需要在远程的tomcat中进行对JMX的配置:
在 tomcat 的 catalina.bat 中添 加如下参数: set JAVA_OPTS=-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port="9004" -Dcom.sun.management.jmxremote.authenticate="false" -Dcom.sun.management.jmxremote.ssl="false" 其中-Dcom.sun.management.jmxremote:允许启用JMX远程管理 其中-Dcom.sun.management.jmxremote.port=9004 指定了 JMX 启动的代理端口;这个端口就是 Visual VM 要连接的端口 其中-Dcom.sun.management.jmxremote.authenticate ="false" JMX 是否启用身份认证 其中-Dcom.sun.management.jmxremote.ssl ="false" 指定了 JMX 是否启用ssl保存退出,使用VisualVM工具进行远程连接。
5. 垃圾回收
在C/C++语言中,没有自动垃圾回收机制,是通过new关键字申请内存资源,通过delete关键字释放内存资源。如果,程序员在某些位置没有写delete进行释放,那么申请的对象一直占用内存资源,最终可能会导致内存溢出。
为了让程序员更专注于代码的实现,而不用过多的考虑内存释放的问题,所以,在java语言中,有了自动的垃圾回收机制,也就是我们熟悉的GC。有了垃圾回收机制后,程席员只零要关心内存的由请即可,内存的释放电系统自动识别完成。换句话说,自动的垃圾回收的算法就会变得非常重要了,如果因为算法的不合理,导致内存资源一直没有释放,同样也可能会导致内存溢出的。
当然,除了Java语言,C#、Python等语言也都有自动的垃圾回收机制。
-
垃圾回收的常见算法
自动化的管理内存资源,垃圾回收机制必须要有一套算法来进行计算,哪些是有效的对象,哪些是无效的对象,对于无效的对象就要进行回收处理。
常见的垃圾回收算法有:引用计数法、标记清除法、标记压缩法、复制算法、分代算法等。
5.1 引用计数法
- 原理:假设有一个对象A,任何一个对象对A的引用,那么对象A的引用计数器+1,当引用失败时,对象A的引用计数器就-1,如果对象A的计数器的值为0,就说明对象A没有引用了,可以被回收。
- 优缺点
- 优点:
- 实时性较高,无需等到内存不够的时候,才开始回收,运行时根据对象的计数器是否为0,就可以直接回收。
- 在垃圾回收过程中,应用无需挂起。如果申请内存时,内存不足,则立刻报outofmember 错误。
- 区域性:更新对象的计数器时,只是影响到该对象,不会扫描全部对象。
- 缺点:
- 每次对象被引用时,都需要去更新计数器,有一点时间开销。
- 浪费CPU资源,及时内存够用,仍然在运行时进行计数器的统计。
- 无法解决循环引用的问题(两个对象相互引用彼此,则两个对象的计数器始终不为零,即使两者都为零也无法被清除)
- 优点:
5.2 标记清除法
标记清除算法,是将垃圾回收分为2个阶段,分别是标记和清除。
- 标记:从根节点开始标记引用的对象。
- 清除:未被标记引用的对象就是垃圾对象,可以被清除。
原理:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J0jnBzKW-1623774592128)(D:\My_Life\Java\学习笔记\Snipaste_2021-06-14_22-27-01.png)]](https://i-blog.csdnimg.cn/blog_migrate/73b3286c9e9a36ce18f2624733b1554b.png)
这张图代表的是程序运行期间所有对象的状态,他们的标记位全是0(即未标记)。假设这会儿有效内存空间耗尽了,JVM会停止应用程序的运行,并开启GC线程,然后开始进行标记工作,根据跟随搜索算法,标记完后,对象状态如下图。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tfffAkWB-1623774592128)(D:\My_Life\Java\学习笔记\Snipaste_2021-06-14_22-29-50.png)]](https://i-blog.csdnimg.cn/blog_migrate/45a66611e10ba21da6269cb8742b3f47.png)
可以看到,根据跟搜索算法,所有从root可达的对象就会被标记为存活的对象,此时已经完成了第一阶段标记。接下来,就要执行第二阶段清除了,清除结束后,剩下的对象以及对象的状态如下图。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EPPqOvJI-1623774592129)(C:\Users\MitsuiYe\AppData\Roaming\Typora\typora-user-images\image-20210614223413262.png)]](https://i-blog.csdnimg.cn/blog_migrate/a0664a620bdf3445105bfcf181f6f7c5.png)
可以看到,没有被标记的对象将会被回收清除掉,而被标记的对象将会留下,而且会将标记位归零。唤醒停止的线程继续运行。
优点:解决了循环引用的问题。
缺点:
- 效率较低,标记和清除两个动作都需要遍历所有对象,并且在GC时,需要停止应用程序。
- 通过标记清除算法清理出来的内存,碎片化非常严重,因为被回收的对象可能存在于内存的每个角落,所以导致清理出来的内存不连贯。
5.3 标记压缩算法
标记压缩算法是在标记清除算法的基础之上,做了优化改进的算法。和标记清除算法一样,也是从根节点开始,对对象的引用进行标记,在清理阶段,并不是简单的清理未标记的对象,而是将存活的对象压缩到内存的一端,然后清理边界以外的垃圾,从而解决了碎片化的问题。
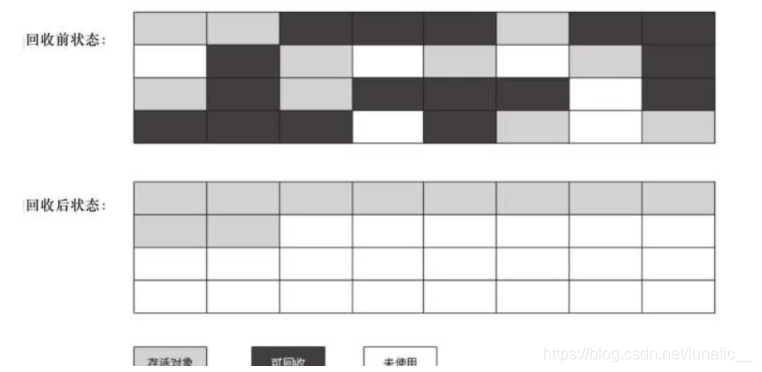
优点:解决了标记清除算法的碎片化问题。
缺点:增加了对象移动内存位置的步骤,其效率也有一定的影响。
5.34 复制算法
复制算法的核心就是,将原有的内存空间一分为二,每次只用其中的一块,在垃圾回收时,将正在使用的对象复制到未被使用内存空间中,然后将在使用的内存空间清空,交换两个内存的角色,完成垃圾的回收。
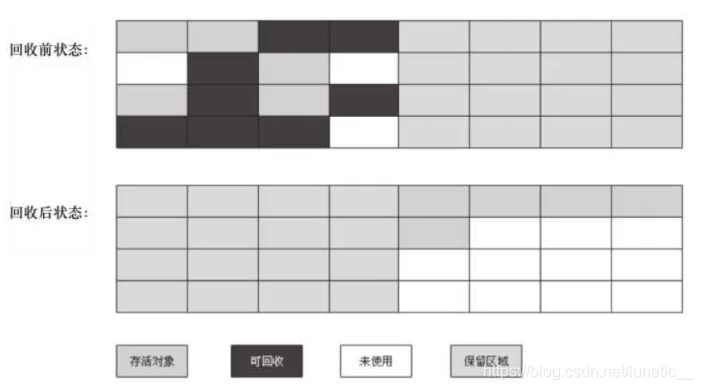
如果内存中的垃圾对象较多,需要复制的对象就较少,这种情况下适合使用该方法,否则不适用。
- JVM中年轻代内存空间
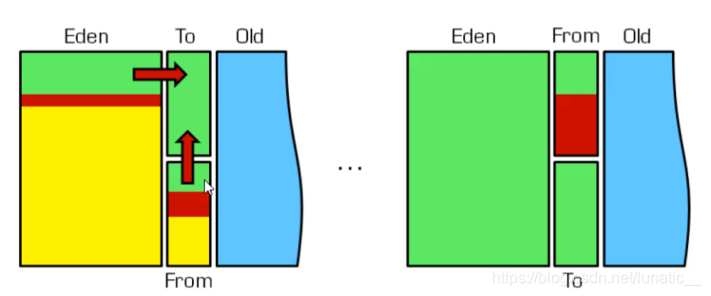
-
在GC开始的时候,对象只会存在于Eden区和名为“From”的Survivor区,Survivor区“To”是空的。
-
紧接着进行GC,Eden区中所有存活的对象都会被复制到“To”,而在“From”区中,仍存活的对象会根据他们的年龄值来决定去向。年龄达到一定值(年龄阈值,可以通过-XX:MaxTenuringThreshold来设置)的对象会被移动到年老代中,没有达到阈值的对象会被复制到“To”区域。
-
经过这次GC后,Eden区和From区已经被清空。这个时候,"From”和“To”会交换他们的角色,也就是新
的“To”就是上次GC前的"From”新的“From”就是上次GC前的"To”。不管怎样,都会保证名为To的Survivor区域是空的。 -
GC会一直重复这样的过程,直到“T”区被填满,"To”区被填满之后,会将所有对象移动到年老代中
-
优缺点
- 优点:
- 在垃圾对象多的时候,效率较高
- 清理后,不会存在内存碎片
- 缺点
- 在垃圾对象少的时候,不适用,例如:老年代内存
- 分配两块内存空间,在同一时刻只能使用一个,内存使用率较低
- 优点:
5.5 分代算法
根据回收对象的特别进行选择,例如:年轻代中使用复制算法,老年代中使用标记算法或标记压缩算法。
5.6 垃圾收集器和内存分配
-
分类
- 串行垃圾收集器
- 并行垃圾收集器
- CMS(并发)垃圾收集器
- G1垃圾收集器
-
串行垃圾收集器
串行垃圾收集器,是指使用单线程进行垃圾回收,垃圾回收时,只有一个线程在工作,并且java应用中的所有线程都要暂停,等待垃圾回收的完成。这种现象称之为STW(Stop-The-World)。
对交互性较强的应用而言这种垃圾收集器是不能够接受的,一般在avaweb应用中是不会采用该收集器的。-
设置垃圾回收器为串行收集器,需要在程序运行参数中添加两个参数
-XX:+UseSerialGC:指定年轻代和老年代都是用串行收集器 -XX:+PrintGCDetails:打印垃圾回收的详细信息 -
GC日志信息解读
年轻代的内存GC前后的大小: -
DefNew:表示使用的是串行垃圾收集器
-
4416K->512K(4928K):表示,年轻代GC前,占有4416K内存,GC后,占有512K内存,总大小4928K
-
0.0046102secs:表示,GC所用的时间,单位为毫秒
-
4416K->1973K(15872K):表示,GC前,堆内存占有4416K,GC后,占有1973K,总大小为15872K
-
Full GC:表示,内存空间全部进行GC
-
-
并行垃圾收集器
并行垃圾收集器在串行垃圾收集器的基础之上做了改进,将单线程改为了多线程进行垃圾回收,这样可以缩短垃圾回收的时间。(这里是指,并行能力较强的机器)
当然了,并行垃圾收集器在收集的过程中也会暂停应用程序,这个和串行垃圾回收器是一样的,只是并行执行,速度更快些,暂停的时间更短一些。-
ParNew垃圾收集器
ParNew垃圾收集器是工作在年轻代上的,只是将串行的垃圾收集器改为了并行。
通过-xX:+UseParNewGC参数设置年轻代使用ParNew回收器,老年代使用的依然是串行收集器。
-
ParallelGC垃圾收集器
- ParallelGC收集器工作机制和ParNewGC收集器样,只是在此基础之上,新增了两个和系统吞吐量相关的参数,使得其使用起来更加的灵活和高效。
- 相关参数如下:
- -XX:+UseParallelGC:年轻代使用ParallelGC垃圾回收器,老年代使用串行回收器。
- -XX:+UseParallelOldGC:年轻代使用ParallelGC垃圾回收器,老年代使用ParallelOldGC垃圾回收器。
- -XX:MaxGCPauseMillis:设置最大的垃圾收集时的停顿时间,单位为毫秒
需要注意的时,ParallelGC为了达到设置的停顿时间,可能会调整堆大小或其他的参数,如果堆的大小设置的较小,就会导致GC工作变得很频繁,反而可能会影响到性能。该参数使用需谨慎。
-
-
GMS垃圾收集器
CMS是一款并发的,使用标记清除算法的垃圾回收器,该回收期是针对老年代垃圾回收的,通过参数-XX:+UseConcMarkSweepGC进行设置。它的执行过程如下图所示:
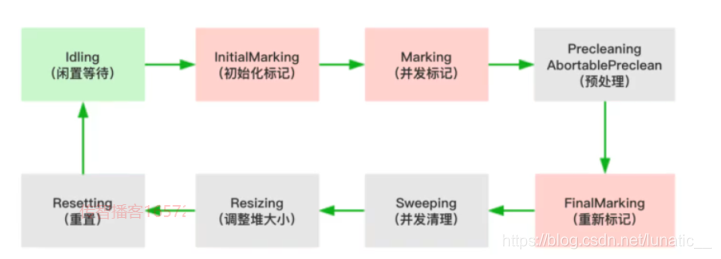
- 初始化标记(CMS-initial-mark)标记root,会导致stw;
- 并发标记(CMS-concurrent-mark),与用户线程同时运行:
- 预清理(CMS-concurrent-preclean),与用户线程同时运行;重新标记(CMS-remark),会导致stw;
- 并发清除(CMS-concurrent-sweep),与用户线程同时运行;
- 调整堆大小,设置设置CMS在清理之后进行内存压缩,目的是清理内存中的碎片;
- 并发重置状态等待下次CMS的触发(CMS-concurrent-reset),与用户线程同时运行;
#设置启动参数
-xx:+UseConcMarkSweepGC-xx:+PrintGCDetails -Xms16m -Xmx16m3
4 #运行日志
5
[Gc(A1location Failure) [ParNew: 4926K->512K(4928K),0.0041843 secs] 9424K->6736K(15872K),0.0042168 secs] [Times: user=0.00 sys=0.00, rea1=0.00 secs]6
#第一步,初始标记
8
[Gc(CMs Initia1 Mark) [1CMs-initial-mark: 6224K(10944K)]6824K(15872K),0.0004209 secs] [Times: user=0.00 sys=0.00, rea1=0.00 secs]
9 #第一步,并发标记
10
[CMS-concurrent-mark-start]11
[CMS-concurrent-mark:0.002/0.002 secs! [Times: user=0.00 sys=0.00, rea1=0.00 secs]12 #第三步,预处理
13
[CMS-concurrent-preclean-start]14
[CMS-concurrent-preclean:0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
15 #第四步,重新标记
16
[GC(CMS Final Remark)[YG occupancy: 1657 K(4928 K)][Rescan (para1le1) ,0.0005811 secs][weak refs processing0.0000136 secs][c1ass unloading,0.0003671 secs][scrub symbo1 table,0.0006813 secs][scrub string table, 0.0001216 secs][1 CMS-remark:6224K(10944K)]7881K(15872K)0.0018324 secs] [Times: user=0.00 sys=0.00, real=0.00
secs]
17 #第五步,并发清理
18 [CMS-concurrent-sweep-start
19
[CMS-concurrent-sweep:0.004/0.004 secs] [Times: user=0.00 sys=0.00, rea1=0.00 secs]#第六步,重罟
20
21
[CMS-concurrent-reset-start]22
[CMS-concurrent-reset:0.000/0.000 secs] [Times: user=0.00 sys=0.00, rea1=0.00 secs]23
由以上日志信息,可以看出CMS执行的过程
-
G1垃圾回收器
G1垃圾收集器是在jdk1.7中正式使用的全新的垃圾收集器,orace官方计划在jdk9中将G1变成默认的垃圾收集器,以替代CMS。
G1的设计原则就是简化JVM性能调优,开发人员只需要简单的三步即可完成调优:-
开启G1垃圾收集器
-
设置堆的最大内存
-
设置最大的停顿时间
G1中提供了三种模式垃圾回收模式,Young GC、Mixed GC 和 Full GC,在不同的条件下被触发。
-
原理
G1垃圾收集器相对比其他收集器而言,最大的区别在于它取消了年轻代、老年代的物理划分,取而代之的是将堆划分为若干个区域(Region),这些区域中包含了有逻辑上的年轻代、老年代区域。
这样做的好处就是,我们再也不用单独的空间对每个代进行设置了,不用担心每个代内存是否足够。
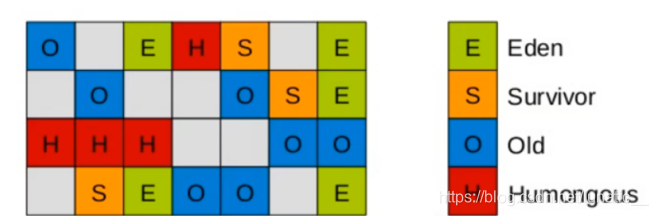
在G1划分的区域中,年轻代的垃圾收集依然采用暂停所有应用线程的方式,将存活对象拷贝到老年代或者 Survivor空间,G1收集器通过将对象从一个区域复制到另外一个区域,完成了清理工作。 这就意味着,在正常的处理过程中,G1完成了堆的压缩(至少是部分堆的压缩),这样也就不会有cms内存碎片问题的存在了。 在G1中,有一种特殊的区域,叫Humongous区域。如果一个对象占用的空间超过了分区容量50%以上,G1收集器就认为这是一个巨型对象,这些巨型对象,默认直接会被分配在老年代,但是如果它是一个短期存在的巨型对象,就会对垃圾收集器造成负面影响。
为了解决这个问题,G1划分了一个Humongous区,它用来专门存放巨型对象。如果一个H区装不下一个巨型对象,那么G1会寻找连续的H分区来存储。为了能找到连续的H区,有时候不得不启动Full GC。-
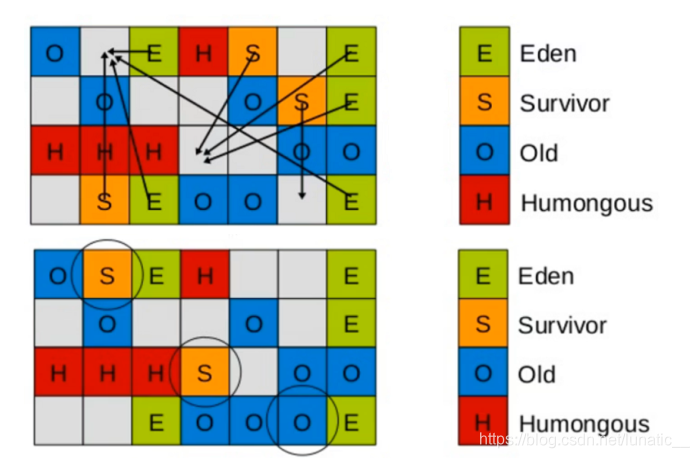
Young GC
YoungGC主要是对Eden区进行GC,它在Eden空间耗尽时会被触发。- Eden空间的数据移动到Survivor空间中,如果Survivor空间不够,Eden空间的部分数据会直接晋升到年老代空间。
- Survivor区的数据移动到新的Survivor区中,也有部分数据晋升到老年代空间中。
- 最终Eden空间的数据为空GC停止工作,应用线程继续执行。
-
Remembered Set(已记忆集合)
在GC年轻代的对象时,我们如何找到年轻代中对象的根对象呢?
根对象可能是在年轻代中也可以在老年代中,那么老年代中的所有对象都是根么?
如果全量扫描老年代,那么这样扫描下来会耗费大量的时间。
于是,G1引进了RSet的概念。它的全称是RememberedSet,其作用是跟踪指向某个堆内的对象引用。
-
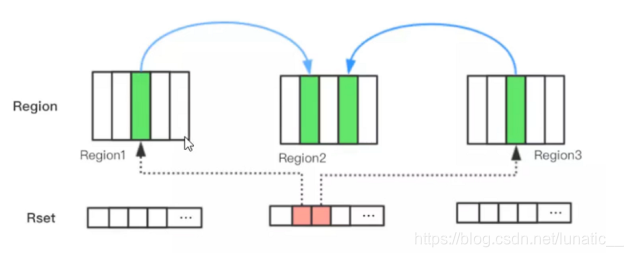
每个Region初始化时,会初始化一个RSet,该集合用来记录并跟踪其它Region指向该Region中对象的引用,每个 Region默认按照512Kb划分成多个Card,所以RSet需要记录的东西应该是xx Region的 xx Card。
-
Mixed GC
当越来越多的对象晋升到老年代oldregion时,为了避免堆内存被耗尽,虚拟机会触发一个混合的垃圾收集器,即 MixedGC,该算法并不是一个OldGC,除了回收整个YoungRegion,还会回收一部分的OldRegion,这里需要注意:是一部分老年代,而不是全部老年代,可以选择哪些oldregion进行收集,从而可以对垃圾回收的耗时时间进行控制。也要注意的是MixedGC并不是Full GC。
MixedGC什么时候触发?由参数**-XX:InitiatingHeapOccupancyPercent=n**决定。默认:45%,该参数的意思是:当老年代大小占整个堆大小百分比达到该阀值时触发。
它的GC步骤分2步-
全局并发标记(global concurrent marking)
全局并发标记,执行过程分为五个步骤:
- 初始标记( initial mark , STW )
- 标记从根节点直接可达的对象,这个阶段会执行一次年轻代GC,会产生全局停顿。
- 根区域扫描(root region scan)
- G1GC在初始标记的存活区扫描对老年代的引用,并标记被引用的对象。
- 该阶段与应用程序(非STW)同时运行,并且只有完成该阶段后,才能开始下一次STW年轻代垃圾回收。
- 并发标记(Concurrent Marking)
- G1GC在整个堆中查找可访问的(存活的)对象。该阶段与应用程序同时运行,可以被STW年轻代垃圾回收中断。
- 重新标记(Remark,STW)
- 该阶段是STW回收,因为程序在运行,针对上一次的标记进行修正。
- 清除垃圾(Cleanup,STW)
- 清点和重置标记状态,该阶段会STW,这个阶段并不会实际上去做垃圾的收集,等待evacuation阶段来回收
- 初始标记( initial mark , STW )
-
拷贝存活对象(evacuation)
Evacuation阶段是全暂停的。该阶段把一部分Region里的活对象拷贝到另一部分Region中,从而实现垃圾的回收清理。
-
-
G1收集器相关参数
-XX:+UseG1GCI #使用 G1垃圾收集器 -XX:MaxGCPauseMillis #设置期望达到的最大GC停顿时间指标(JVM会尽力实现,但不保证达到),默认值是200毫秒。 -XX:G1HeapRegionSize=n #设置的G1区域的大小。值是2的幂,范围是1MB到32MB之间。目标是根据最小的Java堆大小划分出约2048个区域。默认是堆内存的1/2000 -XX:ParallelGCThreads=n #设置STW工作线程数的值。将n的值设置为逻辑处理器的数量。n的值与逻辑处理器的数量相同,最多为8. -XX:ConcGCThreads=n #设置并行标记的线程数。将n设置为并行垃圾回收线程数(ParalleGCThreads)的1/4左右。 -XX:InitiatingHeapOccupancyPercent=n #设置触发标记周期的Java堆占用率阈值。默认占用率是整个Java堆的45%。 -
关于G1垃圾收集器的优化建议
- 年轻代大小
- 避免使用-Xmn选项或XX:NewRatio等其他相关选项显式设置年轻代大小。
- 固定年轻代的大小会覆盖暂停时间目标。
- 暂停时间目标不要太过严苛
- G1GC的吞吐量目标是90%的应用程序时间和10%的垃圾回收时间
- 评估G1GC的吞吐量时,暂停时间目标不要太严苛。目标太过严苛表示您愿意承受更多的垃圾回收开销,而这会直接影响到吞吐量。
- 年轻代大小
-
可视化GC日志分析工具
- 日志输出参数
前面通过**-XX:+PrintGCDetails**可以对GC日志进行打印,我们就可以在控制台查看,这样虽然可以查看GC的信息,但是并不直观可以借助第三方方的GC日志分析工具GCEasy进行查看。
在日志打印输出涉及到的参数如下
-XX:+PrintGC #输出GC日志 -Xx:+PrintGCDetai1s #输出GC的详细日志 -xx:+PrintGCTimeStamps #输出GC的时间戳(以基准时间的形式)3 -xx:+PrintGCDateStamps #输出GC的时间戳(以日期的形式,如2013-05-04T21:53:59.234+0800) -Xx:+PrintHeapAtGC #在进行GC的前后打印出堆的信息 -x1oggc:../logs/gc.1og #日志文件的输出路径测试:
-Xx:+UseG1GC -XX:MaxGCPauseMi11is=100 -Xmx256m -XX:+PrintGCDetails -xx:+PrintGCTimeStamps -xx:+PrintGCDateStamps -XX:+PrintHeapAtGC -xloggc:F://test//gc.1og运行后就可以在E盘下生成gc.log文件。将文件上传gceasy网站即可进行分析。
- 日志输出参数
-
日志输出参数
前面通过**-XX:+PrintGCDetails**可以对GC日志进行打印,我们就可以在控制台查看,这样虽然可以查看GC的信息,但是并不直观可以借助第三方方的GC日志分析工具GCEasy进行查看。在日志打印输出涉及到的参数如下
-XX:+PrintGC #输出GC日志 -Xx:+PrintGCDetai1s #输出GC的详细日志 -xx:+PrintGCTimeStamps #输出GC的时间戳(以基准时间的形式)3 -xx:+PrintGCDateStamps #输出GC的时间戳(以日期的形式,如2013-05-04T21:53:59.234+0800) -Xx:+PrintHeapAtGC #在进行GC的前后打印出堆的信息 -x1oggc:../logs/gc.1og #日志文件的输出路径测试:
-Xx:+UseG1GC -XX:MaxGCPauseMi11is=100 -Xmx256m -XX:+PrintGCDetails -xx:+PrintGCTimeStamps -xx:+PrintGCDateStamps -XX:+PrintHeapAtGC -xloggc:F://test//gc.1og运行后就可以在E盘下生成gc.log文件。将文件上传gceasy网站即可进行分析。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









