







微信公众号:大数据开发运维架构
关注可了解更多大数据相关的资讯。问题或建议,请公众号留言;
如果您觉得“大数据开发运维架构”对你有帮助,欢迎转发朋友圈
从微信公众号拷贝过来,格式有些错乱,建议直接去公众号阅读
kafka中的数据通常是键值对的,所以我们这里自定义反序列化类从kafka中消费键值对的消息,为方便大家学习,这里我实现了Java/Scala两个版本,由于比较简单这里直接上代码:
一、Scala代码:
1.自定义反序列化类:
package comhadoop.ljs.flink010.kafka
import org.apache.flink.api.common.typeinfo.{TypeHint, TypeInformation}
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema
import org.apache.kafka.clients.consumer.ConsumerRecord
/**
* @author: Created By lujisen
* @company ChinaUnicom Software JiNan
* @date: 2020-04-25 18:31
* @version: v1.0
* @description: comhadoop.ljs.flink010.kafka
*/
class MyKafkaDeserializationSchema extends KafkaDeserializationSchema[ConsumerRecord[String, String]]{
/*是否流结束,比如读到一个key为end的字符串结束,这里不再判断,直接返回false 不结束*/
override def isEndOfStream(t: ConsumerRecord[String, String]): Boolean ={
false
}
override def deserialize(record: ConsumerRecord[Array[Byte], Array[Byte]]): ConsumerRecord[String, String] = {
new ConsumerRecord(record.topic(),record.partition(),record.offset(),new String(record.key(),"UTF-8"),new String(record.value(),"UTF-8"))
}
/*用于获取反序列化对象的类型*/
override def getProducedType: TypeInformation[ConsumerRecord[String, String]] = {
TypeInformation.of(new TypeHint[ConsumerRecord[String, String]] {})
}
}2.主函数类:
package comhadoop.ljs.flink010.kafka
import java.util.Properties
import org.apache.flink.api.common.functions.MapFunction
import org.apache.flink.streaming.api.datastream.DataStream
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.flink.streaming.connectors.kafka.internals.KafkaTopicPartition
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
/**
* @author: Created By lujisen
* @company ChinaUnicom Software JiNan
* @date: 2020-04-25 16:32
* @version: v1.0
* @description: comhadoop.ljs.flink010.kafka
*/
object KafkaDeserializerSchemaTest {
def main(args: Array[String]): Unit = {
/*环境初始化*/
val senv:StreamExecutionEnvironment =StreamExecutionEnvironment.getExecutionEnvironment()
/*启用checkpoint,这里我没有对消息体的key value进行判断,即使为空启动了checkpoint,遇到错误也会无限次重启*/
senv.enableCheckpointing(2000)
/*topic2不存在话会自动在kafka创建,一个分区 分区名称0*/
val myConsumer=new FlinkKafkaConsumer[ConsumerRecord[String, String]]("topic3",new MyKafkaDeserializationSchema(),getKafkaConfig())
/*指定消费位点*/
val specificStartOffsets = new java.util.HashMap[KafkaTopicPartition, java.lang.Long]()
/*这里从topic3 的0分区的第一条开始消费*/
specificStartOffsets.put(new KafkaTopicPartition("topic3", 0), 0L)
myConsumer.setStartFromSpecificOffsets(specificStartOffsets)
/*指定source数据源*/
val source:DataStream[ConsumerRecord[String, String]]=senv.addSource(myConsumer)
val keyValue=source.map(new MapFunction[ConsumerRecord[String, String],String] {
override def map(message: ConsumerRecord[String, String]): String = {
"key" + message.key + " value:" + message.value
}
})
/*打印接收的数据*/
keyValue.print()
/*启动执行*/
senv.execute()
}
def getKafkaConfig():Properties={
val props:Properties=new Properties()
props.setProperty("bootstrap.servers","worker1.hadoop.ljs:6667,worker2.hadoop.ljs:6667")
props.setProperty("group.id","topic_1")
props.setProperty("key.deserializer",classOf[StringDeserializer].getName)
props.setProperty("value.deserializer",classOf[StringDeserializer].getName)
props.setProperty("auto.offset.reset","latest")
props
}
}二、Java代码:
1.自定义反序列化类:
package com.hadoop.ljs.flink110.kafka;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
import org.apache.kafka.clients.consumer.ConsumerRecord;
/**
* @author: Created By lujisen
* @company ChinaUnicom Software JiNan
* @date: 2020-04-25 18:45
* @version: v1.0
* @description: com.hadoop.ljs.flink110.kafka
*/
public class MyKafkaDeserializationSchema implements KafkaDeserializationSchema<ConsumerRecord<String, String>> {
private static String encoding = "UTF8";
@Override
public boolean isEndOfStream(ConsumerRecord<String, String> nextElement) {
return false;
}
@Override
public ConsumerRecord<String, String> deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception {
/* System.out.println("Record--partition::"+record.partition());
System.out.println("Record--offset::"+record.offset());
System.out.println("Record--timestamp::"+record.timestamp());
System.out.println("Record--timestampType::"+record.timestampType());
System.out.println("Record--checksum::"+record.checksum());
System.out.println("Record--key::"+record.key());
System.out.println("Record--value::"+record.value());*/
return new ConsumerRecord(record.topic(),
record.partition(),
record.offset(),
record.timestamp(),
record.timestampType(),
record.checksum(),
record.serializedKeySize(),
record.serializedValueSize(),
/*这里我没有进行空值判断,生产一定记得处理*/
new String(record.key(), encoding),
new String(record.value(), encoding));
}
@Override
public TypeInformation<ConsumerRecord<String, String>> getProducedType() {
return TypeInformation.of(new TypeHint<ConsumerRecord<String, String>>(){});
}
}
2.主函数类:
package com.hadoop.ljs.flink110.kafka;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.internals.KafkaTopicPartition;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
/**
* @author: Created By lujisen
* @company ChinaUnicom Software JiNan
* @date: 2020-04-25 18:41
* @version: v1.0
* @description: com.hadoop.ljs.flink110.kafka
*/
public class KafkaDeserializerSchemaTest {
public static void main(String[] args) throws Exception {
/*环境初始化*/
StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
/*启用checkpoint,这里我没有对消息体的key value进行判断,即使为空启动了checkpoint,遇到错误也会无限次重启*/
senv.enableCheckpointing(2000);
/*topic2不存在话会自动在kafka创建,一个分区 分区名称0*/
FlinkKafkaConsumer<ConsumerRecord<String, String>> myConsumer=new FlinkKafkaConsumer<ConsumerRecord<String, String>>("topic3",new MyKafkaDeserializationSchema(),getKafkaConfig());
/*指定消费位点*/
Map<KafkaTopicPartition, Long> specificStartOffsets = new HashMap<>();
/*这里从topic3 的0分区的第一条开始消费*/
specificStartOffsets.put(new KafkaTopicPartition("topic3", 0), 0L);
myConsumer.setStartFromSpecificOffsets(specificStartOffsets);
DataStream<ConsumerRecord<String, String>> source = senv.addSource(myConsumer);
DataStream<String> keyValue = source.map(new MapFunction<ConsumerRecord<String, String>, String>() {
@Override
public String map(ConsumerRecord<String, String> message) throws Exception {
return "key"+message.key()+" value:"+message.value();
}
});
/*打印结果*/
keyValue.print();
/*启动执行*/
senv.execute();
}
public static Properties getKafkaConfig(){
Properties props=new Properties();
props.setProperty("bootstrap.servers","worker1.hadoop.ljs:6667,worker2.hadoop.ljs:6667");
props.setProperty("group.id","topic_group2");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("auto.offset.reset","latest");
return props;
}
}三、函数测试
1.KafkaProducer发送测试数据类<key,value>:
package com.hadoop.ljs.kafka220;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Date;
import java.util.Properties;
public class KafkaPartitionProducer extends Thread{
private static long count =10;
private static String topic="topic3";
private static String brokerList="worker1.hadoop.ljs:6667,worker2.hadoop.ljs:6667";
public static void main(String[] args) {
KafkaPartitionProducer jproducer = new KafkaPartitionProducer();
jproducer.start();
}
@Override
public void run() {
producer();
}
private void producer() {
Properties props = config();
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record=null;
System.out.println("kafka生产数据条数:"+count);
for (int i = 1; i <= count; i++) {
String json = "{\"id\":" + i + ",\"ip\":\"192.168.0." + i + "\",\"date\":" + new Date().toString() + "}";
String key ="key"+i;
record = new ProducerRecord<String, String>(topic, key, json);
producer.send(record, (metadata, e) -> {
// 使用回调函数
if (null != e) {
e.printStackTrace();
}
if (null != metadata) {
System.out.println(String.format("offset: %s, partition:%s, topic:%s timestamp:%s", metadata.offset(), metadata.partition(), metadata.topic(), metadata.timestamp()));
}
});
}
producer.close();
}
private Properties config() {
Properties props = new Properties();
props.put("bootstrap.servers",brokerList);
props.put("acks", "1");
props.put("retries", 3);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
/*自定义分区,两种形式*/
/*props.put("partitioner.class", PartitionUtil.class.getName());*/
return props;
}
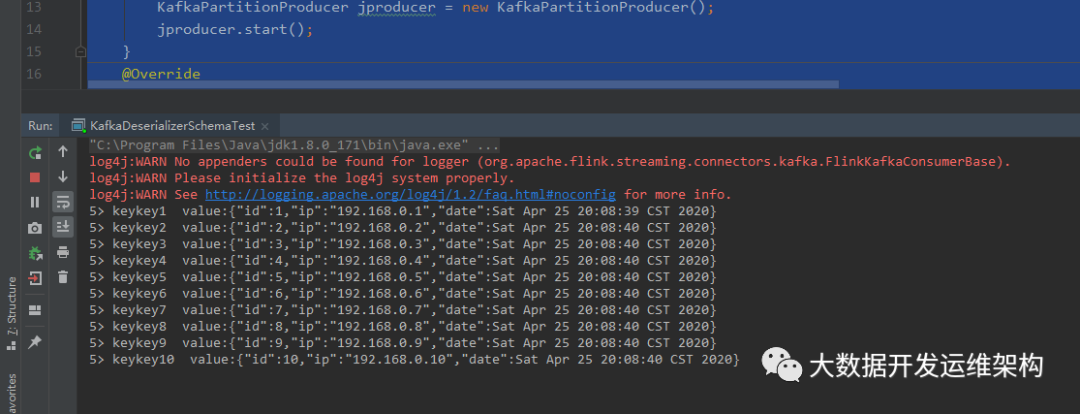
}2.测试结果
如果觉得我的文章能帮到您,请关注微信公众号“大数据开发运维架构”,并转发朋友圈,谢谢支持!!!



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











