







图算法的总结和实现
1.0 图的表示
- 图通常用两种数据结构表示:邻接矩阵->稠密图、邻接链表->稀疏图
- 对于图 G = (V, E) ,V是点集,E是边集,|V| |E|分别表示点、边的数目
- 稀疏图:边数很少的图
- 稠密图:边数接近|V|^2的图(一个图边数最多是点数的平方,只考虑单边图)
邻接矩阵
- 维护一个n*n的数组,n是图的点数|V|
- 根据图的性质,数组对角线都为0,上下半角都对称
- 矩阵存储的特点,不论边数|E|多大,永远都开|V|*|V|大小的数组
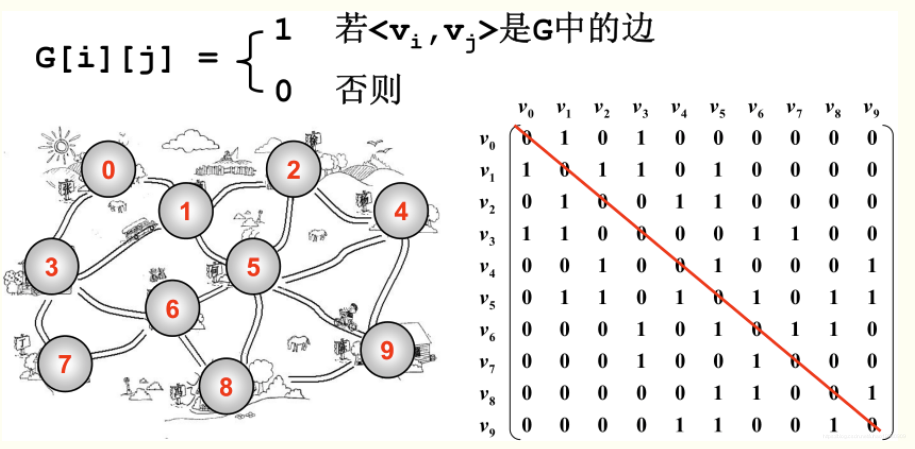
因为矩阵的大小取决于|V|,所以当边数足够多的时候,采用邻接矩阵表示对空间的利用率最高
邻接链表
- 每个节点维护一个链表,储存所有与它邻接的点
- 所有链表的头部储存在一个数组中
- 数组空间O(|V|),链表空间是O(|E|)、最坏空间是O(|V|^2)
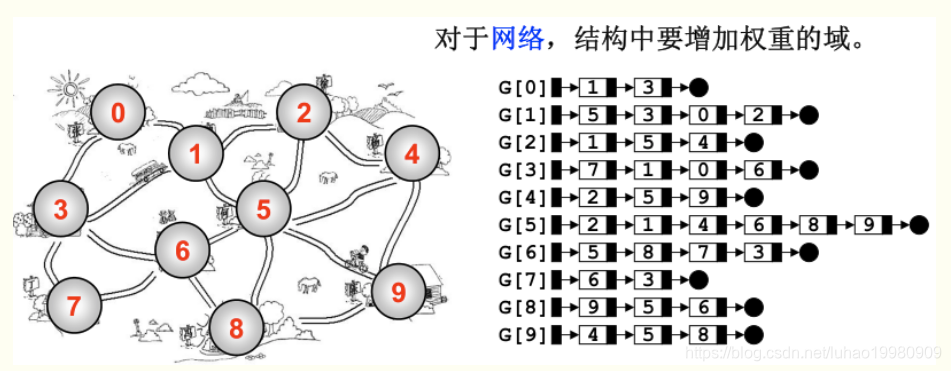
因为链表大小取决于|E|,所以当边数足够小时,采用邻接链表表示
python代码如下:
class Graph():
'''
无向图,点下标从0开始
G[x][y] = 1 存在边xy ; G[x][y] = 0 不存在边xy '''
def __init__(self,n):
# 声明一个有n个点的图G
self.n = n # |V|点数
self.node = [i for i in range(n)] # 所有点
self.G = [[0]*n for i in range(n)] # 邻接矩阵
self.d = [0]*n # 记录宽搜中每个点到起点的距离
self.order = [] # 记录深搜的顺序
def add(self,x,y,w=0):
# 添加一条(x,y)的无向边
# 不输入边权重的情况默认为1
self.G[x][y] = 1 if not w else w
self.G[y][x] = 1 if not w else w
def remove(self,x,y):
# 删除一条(x,y)的无向边
self.G[x][y] = 0
self.G[y][x] = 0
def neighbour(self,x):
# 返回与x邻接的点
# rtype: 列表
ans = []
for i in range(self.n):
if self.G[x][i]:
ans.append(i)
return ans
def isEdge(self,x,y):
# 判断点x,y是否邻接
return self.G[x][y]
1.1 图的宽搜和深搜
- BFS:广度优先搜索
- 采用优先队列,先将起点x入队列
- 不断从队列中取出元素,访问其所有的邻点,再将其中未访问过的邻点加入队列
- 当队列空时搜索结束
- DFS:深度优先搜索
- 深搜的顺序不是唯一的;从任一节点开始都可以
- 对某一节点,只要找到一个邻点,就对邻点继续搜索邻点的邻点
- 理论上的深搜,是对所有节点执行一次上一步骤,这样保证了所有节点都能被搜索完,实际操作中可以维护一个set来记录已经访问过的节点
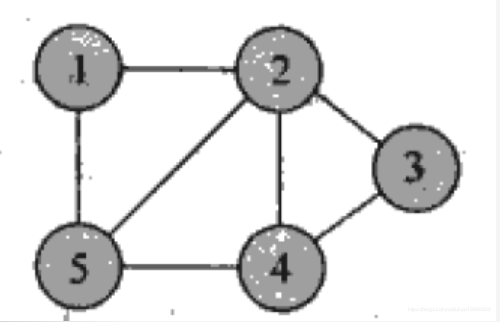
以1为起点的BFS路径: 1 2 5 3 4
以1为起点的DFS路径: 1 2 3 4 5
python代码如下:
# 广度优先搜索
def BFS(self,x):
# 从点x开始宽搜
vis = [0]*self.n # 记录节点是否搜索过
Q = [x]
while Q:
v = Q.pop(0)
vis[v] = 1
for i in self.neighbour(v): # neighbour表示v的邻点的集合
if not vis[i]:
Q.append(i)
self.d[i] = self.d[v] + 1
vis[i] = 1
# 深度优先搜索
def DFS(self,x):
# 从点x开始深搜
vis = [0]*self.n # 记录节点是否搜索过
def dfs(node):
vis[node] = 1
self.order.append(node)
for i in self.neighbour(node):
if not vis[i]:
dfs(i)
dfs(x)
for i in self.node:
if not vis[i]:
dfs(i)
1.2 图的最短路径算法
- 单源最短路径问题:求出某一节点到其他所有节点的最短距离
- Dijkstra算法
- Bellman-Ford算法
- 所有节点对最短路径问题:求出每个节点到其他所有节点的最短距离
- Floyd算法
- Floyd算法
Dijkstra算法
- 给定某一起点x,计算它到所有节点的最短距离
- dist[v] 记录起点到点v的最短距离,即最终返回结果
- S 一个集合,存放已经处理过的节点
- 初始状态:令起点的dist为0,它的邻点的dist就是两点距离,其他节点的dist赋为无穷大
- 循环过程:不断取当前dist最小的节点v出来,对它的邻点i做松弛操作,当前最小节点视为已处理节点,放入集合S
- 松弛:
if dist[i] > dist[v] + G[i][v] { dist[i] = dist [v] + G[i][v] }
- 松弛:
- 终止状态:所有节点都已放入S,即都处理完毕
# dijkstra算法的python实现
def dijkstra(self,x):
# dijkstra算法求x到所有节点的最短路径,采用贪心策略
dist = [99999]*self.n
S = set([x]) # 记录已经找到最短路径的节点
for i in self.neighbour(x):
dist[i] = self.G[x][i]
dist[x] = 0
while len(S) != self.n:
# 找到当前距离最小的点,这里用到最下优先队列
MIN = 99999
MIN_i = 0
for i in range(self.n):
if dist[i] < MIN and i not in S:
MIN = dist[i]
MIN_i = i
# 松弛relax操作
S.add(MIN_i)
for i in self.neighbour(MIN_i):
if dist[i] > dist[MIN_i] + self.G[i][MIN_i]:
dist[i] = dist[MIN_i] + self.G[i][MIN_i]
return dist


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









