







 本文详细介绍了Hive、MySQL和Java之间的基本数据类型对应关系,包括TINYINT、SMALINT、INT、BIGINT、BOOLEAN、FLOAT、DOUBLE和STRING等,并探讨了Hive的复杂数据类型如STRUCT、MAP和ARRAY。此外,还阐述了Hive中的类型转换规则,包括隐式转换和使用CAST的显式转换。
本文详细介绍了Hive、MySQL和Java之间的基本数据类型对应关系,包括TINYINT、SMALINT、INT、BIGINT、BOOLEAN、FLOAT、DOUBLE和STRING等,并探讨了Hive的复杂数据类型如STRUCT、MAP和ARRAY。此外,还阐述了Hive中的类型转换规则,包括隐式转换和使用CAST的显式转换。
1,基本数据类型
| HIVE | MySQL | JAVA | 长度 | 例子 |
| TINYINT | TINYINT | byte | 1byte有符号整数 | 2 |
| SMALINT | SMALINT | short | 2byte有符号整数 | 20 |
| INT | INT | int | 4byte有符号整数 | 20 |
| BIGINT | BIGINT | long | 8byte有符号整数 | 20 |
| BOOLEAN | 无 | boolean | 布尔类型,true或者false | TRUE FALSE |
| FLOAT | FLOAT | float | 单精度浮点数 | 3.14159 |
| DOUBLE | DOUBLE | double | 双精度浮点数 | 3.14159 |
| STRING | VARCHAR | string | 字符系列。可以指定字符集。可以使用单引号或者双引号。 | ‘now is the time’ “for all good men” |
| TIMESTAMP | TIMESTAMP |
| 时间类型 |
|
| BINARY | BINARY |
| 字节数组 |
|
对于hive的String类型,相当于数据库中的varchar类型,是一个可变字符串类型,不过它不用声明最多能存储几个字符,理论上可以存储2GB的字符数。
2,集合数据类型
| 数据类型 | 描述 | 语法示例 |
| STRUCT | 和c语言中的struct类似,都可以通过“点”符号访问元素内容。例如,如果某个列的数据类型是STRUCT{first STRING, last STRING},那么第1个元素可以通过字段.first来引用。2 | struct() 例如 struct<street:string, city:string> |
| MAP | MAP是一组键-值对元组集合,使用数组表示法可以访问数据。例如,如果某个列的数据类型是MAP,其中键->值对是’first’->’John’和’last’->’Doe’,那么可以通过字段名[‘last’]获取最后一个元素 | map() 例如map<string, int> |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。例如,数组值为[‘John’, ‘Doe’],那么第2个元素可以通过数组名[1]进行引用。 | Array() 例如array<string> |
Hive中的STRUCT复杂数据类型与C语言中的Struct类似,它封装了一个命名字段集合。三个复杂数据类型允许任意层次的嵌套。
3,类型转换
Hive的原子数据类型是可以进行隐式转换的,类似于Java的类型转换,例如某表达式使用INT类型,TINYINT会自动转换为INT类型,但是Hive不会进行反向转化,例如,某表达式使用TINYINT类型,INT不会自动转换为TINYINT类型,它会返回错误,除非使用CAST操作。
-----------------------------------------------------------------------------------------------------------------------------------------------
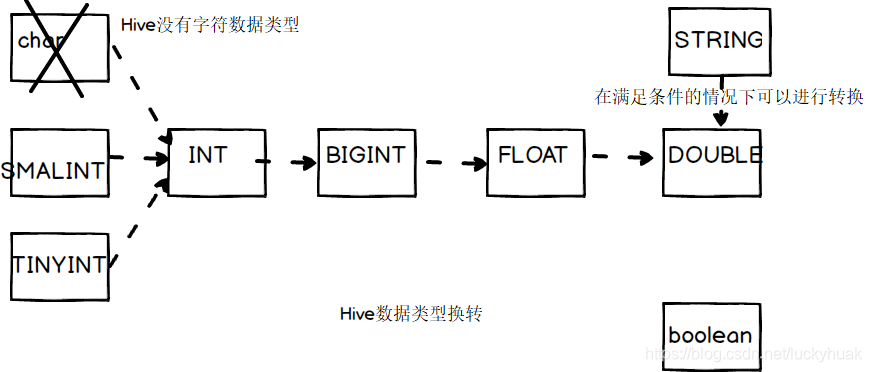
隐式类型转换规则如下
(1)任何整数类型都可以隐式地转换为一个范围更广的类型,如TINYINT可以转换成INT,INT可以转换成BIGINT。
(2)所有整数类型、FLOAT和STRING类型都可以隐式地转换成DOUBLE。
(3)TINYINT、SMALLINT、INT都可以转换为FLOAT。
(4)BOOLEAN类型可以转换为任何其他的类型。
可以使用CAST操作显示进行数据类型转换
例如CAST('1' AS INT)将把字符串'1' 转换成整数1;如果强制类型转换失败,如执行CAST('X' AS INT),表达式返回空值 NULL。
0: jdbc:hive2://hadoop102:10000> select '1'+2, cast('1'as int) + 2;
+------+------+--+
| _c0 | _c1 |
+------+------+--+
| 3.0 | 3 |
+------+------+--+

















 1622
1622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









