




🐬 目录:
一、字符识别任务
OCR (Optical Character Recognition, 光学字符识别):一种将印刷体或手写文字转换为可编辑文本的技术,即将图像中的文字进行识别,并以文本的形式返回。

OCR识别技术主要依赖于图像处理和模式识别算法,通过捕捉文档中的字符特征,如笔画、形状、大小、间距等,与预设的字符库进行比对,从而识别相应的文字信息。
二、技术细节
2025年10月20日,DeepSeek正式开源DeepSeek-OCR模型,并同步发布相关运行脚本、测试代码、DeepEncoder源码以及技术报告等全套资料。在技术实践层面,它是目前开源社区少数具备端到端文档解析、语义理解与结构化生成能力 的轻量级多模态模型,参数仅约 3B,却能在A100单卡上实现高达 2500 tokens/s 的推理速度,极大降低了企业和研究者在多模态RAG系统中的部署门槛。 DeepSeek-OCR的框架图如下图所示:
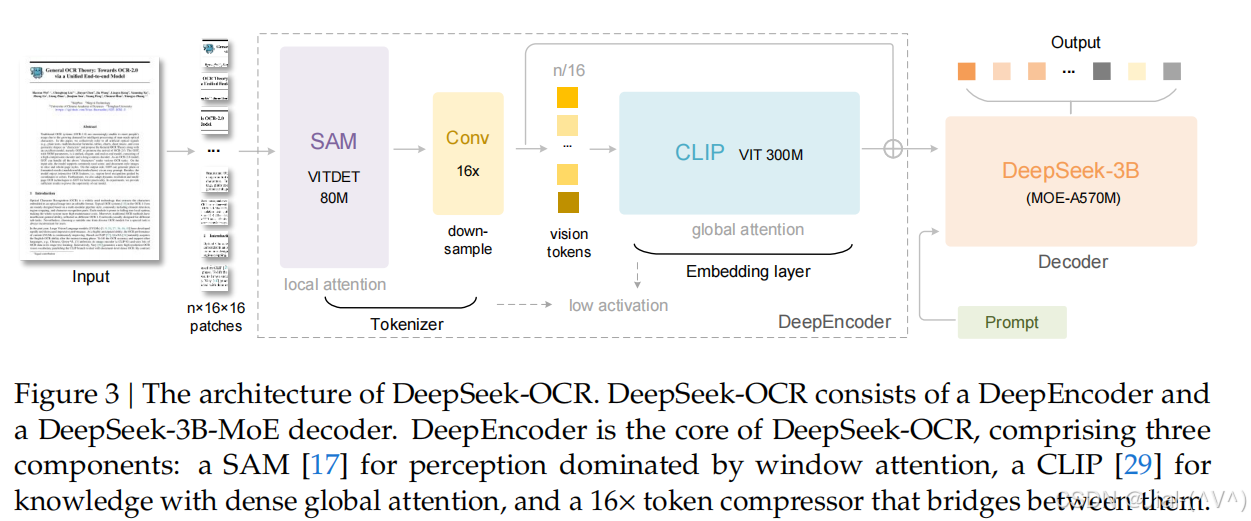
DeepSeek-OCR采用统一的端到端视觉语言模型(VLM)架构,由编码器和解码器组成。编码器(DeepEncoder)负责提取图像特征、进行分词处理以及压缩视觉表示。解码器则基于图像分词结果和提示词生成所需输出。DeepEncoder参数规模约 3.8 亿,主要由8000万参数的SAM-base与3亿参参数的CLIP-large串联组成。解码器采用3B MOE架构,拥有5.7亿激活参数。具体而言,DeepSeek-OCR模型可实现以下几大核心功能:
1️⃣ OCR 纯文字提取: 支持对任意图像进行自由式文字识别,加速提取图片中的全部文本信息。
2️⃣ 保留版面格式的OCR提取:模型可自动识别并重建文档中的排版结构,包括段落、标题、页眉页脚、列表与多栏布局,实现“结构化文字输出”。
3️⃣ 图表&表格解析:DeepSeek-OCR不仅识别文本,还能解析图像中的结构化信息,如表格、流程图、建筑平面图等,自动识别单元格边界、字段对齐关系及数据对应结构,支持生成可机读的表格或文本描述。
4️⃣图片信息描述:借助其多模态理解能力,模型能够对整张图片进行语义级分析与详细描述,生成自然语言总结。
5️⃣ 指定元素位置锁定: 支持通过“视觉定位”功能,在图像中准确定位特定目标元素。例如,输入"Locate signature in the image",模型即可返回签名区域的坐标,实现基于语义的图像检索与目标检测。
6️⃣ Markdown文档转化:可将完整的文档图像直接转换为结构化Markdown文本,自动识别标题层级、段落结构、表格与列表格式,可实现文档数字化、知识库构建和多模态RAG场景的重要基础模块。
三、字符识别实战
在NVIDIA GPU上使用Huggingface的Transformers库进行推理。使用本地部署后进行推理,亲测使用虚拟环境为:Python 3.12.9 + CUDA 11.8
torch == 2.6.0
transformers == 4.46.3
tokenizers == 0.20.3
einops (张量操作工具)
addict (字典操作模块)
easydict (简化字典操作)
pip install flash-attn==2.7.3 --no-build-isolation (flash-attn是一个高性能的GPU注意力加速库,常用于加速大模型中的Transformer注意力计算)(–no-build-isolation 创建一个临时的隔离虚拟环境)
模型下载
from huggingface_hub import snapshot_download
import os
os.environ['HTTP_PROXY'] = 'http://127.0.0.1:7890' #使用代理。(只有在本地确实有代理程序,如clash等)在运行时才能生效
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'
snapshot_download(
repo_id="deepseek-ai/DeepSeek-OCR",
local_dir="../../Pretrained-LLM/models/DeepSeek-OCR", #指定下载路径
local_dir_use_symlinks=False,
resume_download=True,
revision="main"
)

推理代码:
from transformers import AutoModel, AutoTokenizer
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_path = '../../Pretrained-LLM/models/DeepSeek-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True, use_safetensors=True)
model = model.eval().cuda().to(torch.bfloat16)
# prompt = "<image>\nFree OCR. "
prompt = "<image>\n<|grounding|>Convert the document to markdown. "
image_file = 'news.png'
output_path = './ouput'
# infer(self, tokenizer, prompt='', image_file='', output_path = ' ', base_size = 1024, image_size = 640, crop_mode = True, test_compress = False, save_results = False):
# Tiny: base_size = 512, image_size = 512, crop_mode = False
# Small: base_size = 640, image_size = 640, crop_mode = False
# Base: base_size = 1024, image_size = 1024, crop_mode = False
# Large: base_size = 1280, image_size = 1280, crop_mode = False
# Gundam: base_size = 1024, image_size = 640, crop_mode = True
res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)
运行代码后,终端会打印下面的信息:
=====================
BASE: torch.Size([1, 256, 1280])
PATCHES: torch.Size([6, 100, 1280])
=====================
The attention layers in this model are transitioning from computing the RoPE embeddings internally through `position_ids` (2D tensor with the indexes of the tokens), to using externally computed `position_embeddings` (Tuple of tensors, containing cos and sin). In v4.46 `
position_ids` will be removed and `position_embeddings` will be mandatory.
<|ref|>sub_title<|/ref|><|det|>[[5, 12, 152, 60]]<|/det|>
## 观点·深度》》
<|ref|>image<|/ref|><|det|>[[5, 95, 528, 560]]<|/det|>
<|ref|>sub_title<|/ref|><|det|>[[5, 608, 352, 656]]<|/det|>
## 用精品标注时代文艺创作的高度
<|ref|>text<|/ref|><|det|>[[5, 707, 525, 920]]<|/det|>
近日揭晓的第十八届文华奖,作为文化和旅游部设立的专业舞台艺术领域政府最高奖项,通过优化奖项设置、放宽首演时间、扩大申报渠道等改革,进一步完善评奖机制,强化“十年磨一戏”的精品意识,捧出了舞台艺术繁荣发展的累累硕果。
<|ref|>sub_title<|/ref|><|det|>[[570, 99, 812, 140]]<|/det|>
## 年轻干部不妨多些“自找苦吃”
<|ref|>text<|/ref|><|det|>[[570, 162, 952, 247]]<|/det|>
干部成长成熟成才的路上,从没有坦途捷径可走,只能是一步一个脚印爬坡过坎。
<|ref|>sub_title<|/ref|><|det|>[[570, 303, 965, 344]]<|/det|>
## 财评:“两新”精准,彰显宏观调控前瞻性有效性
<|ref|>text<|/ref|><|det|>[[570, 366, 947, 450]]<|/det|>
当前,“两新”政策的实施正在推动经济发展质量、结构、效益同步提升。
<|ref|>sub_title<|/ref|><|det|>[[570, 506, 789, 547]]<|/det|>
## 银行网点增减应以便民为本
<|ref|>text<|/ref|><|det|>[[570, 569, 965, 650]]<|/det|>
网点增减是银行出于经营管理考量的自主选择,但其底层逻辑应遵循便民惠民、降本增效。
<|ref|>sub_title<|/ref|><|det|>[[570, 708, 789, 748]]<|/det|>
## 算好“过紧日子”的两本账
<|ref|>text<|/ref|><|det|>[[570, 770, 946, 855]]<|/det|>
“过紧日子”不是捂紧钱包不花钱,而是该省的省、该花的花。
<|ref|>text<|/ref|><|det|>[[592, 920, 720, 954]]<|/det|>
查看更多深度评论
==================================================
image size: (902, 565)
valid image tokens: 760
output texts tokens (valid): 471
compression ratio: 0.62
==================================================
===============save results:===============
image: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 22429.43it/s]
other: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:00<00:00, 310689.19it/s]
同时会生成output文件,里面包含文档中的images图像,识别后的markdown文本文件,以及如下的目标检测图像result_with_boxes.jpg图像。



















 1477
1477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









