



 本文详细介绍了如何将本地Spark工程打包并在YARN上运行,包括设置HADOOP_CONF_DIR,启动YARN,执行自带实例,以及工程打包、上传、配置并行度和查看输出结果的步骤。
本文详细介绍了如何将本地Spark工程打包并在YARN上运行,包括设置HADOOP_CONF_DIR,启动YARN,执行自带实例,以及工程打包、上传、配置并行度和查看输出结果的步骤。
概述:本文主要讲述如何将本地Spark工程打包放到YARN中运行。
1、基本案例
(1)spark-shell位置
cd /root/app/spark-2.4.2-bin-hadoop2.6/bin
(2)设置HADOOP_CONF_DIR位置
export HADOOP_CONF_DIR=/root/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
#或写入spark-env.sh
vi /root/app/spark-2.4.2-bin-hadoop2.6/conf/spark-env.sh
#内容为
HADOOP_CONF_DIR=/root/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
(3)启动yarn
./app/hadoop-2.6.0-cdh5.7.0/sbin/start-all.sh
(4)执行spark自带实例
#命令参考http://spark.apache.org/docs/latest/submitting-applications.html
./app/spark-2.4.2-bin-hadoop2.6/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--executor-memory 1G \
--total-executor-cores 1 \
/root/app/spark-2.4.2-bin-hadoop2.6/examples/jars/spark-examples_2.12-2.4.2.jar \
10
pi的计算结果
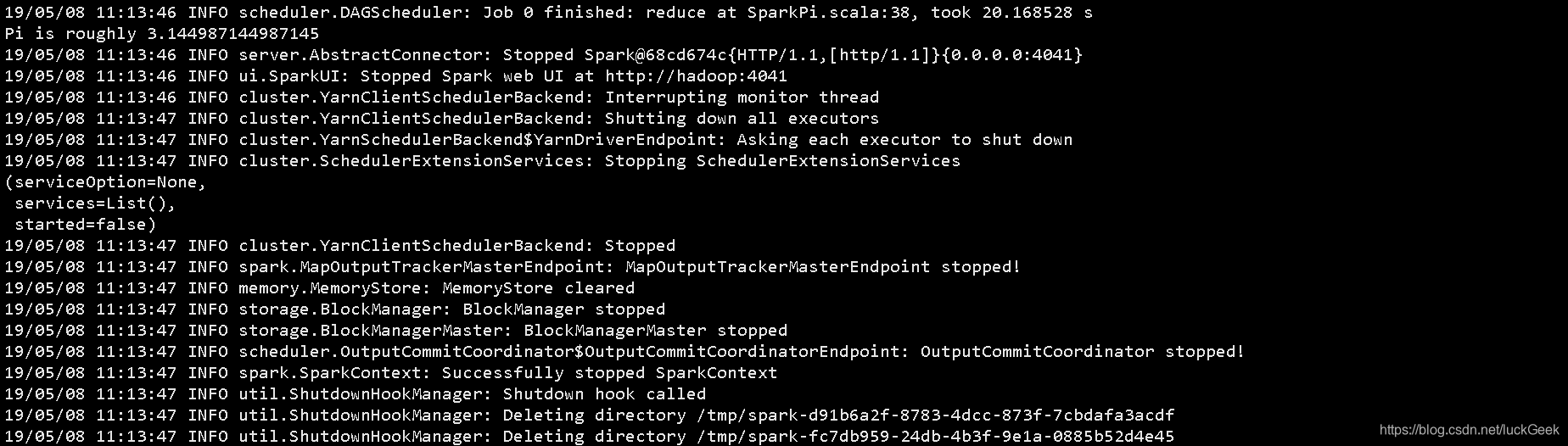
2、Spark工程打包与部署
(1)pom.xml中添加插件
防止依赖丢失,spark工程打包时需要在pom.xml中添加plugin,同时需要将服务器上已提供的jar包排除掉
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<scope>provided</scope>
</dependency>
...
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
(2)使用assembly实现自定义打包
mvn clean
mvn assembly:assembly
(3)上传jar包到服务器
scp access.log root@hadoop:~/app/hadoop-2.6.0-cdh5.7.0/lib
scp sql-1.0-SNAPSHOT-jar-with-dependencies.jar root@hadoop:~/app/hadoop-2.6.0-cdh5.7.0/lib
#city无数据或未知,需要将ip数据库文件一并上传
scp ipDatabase.csv root@hadoop:~/app/hadoop-2.6.0-cdh5.7.0/lib
scp ipRegion.xlsx root@hadoop:~/app/hadoop-2.6.0-cdh5.7.0/lib
hadoop fs -mkdir -p /imooc/input
#提交待统计数据到hdfs中
hadoop fs -put ~/app/hadoop-2.6.0-cdh5.7.0/lib/access.log /imooc/input
(4)执行作业
spark.sql.shuffle.partitions=100表示调整并行度为100
./bin/spark-submit \
--class com.inspur.log.SparkStatCleanJobOnYarn \
--name SparkStatCleanJobOnYarn \
--master yarn \
--files /root/app/hadoop-2.6.0-cdh5.7.0/lib/ipDatabase.csv,/root/app/hadoop-2.6.0-cdh5.7.0/lib/ipRegion.xlsx \
--executor-memory 1G \
--conf spark.sql.shuffle.partitions=100 \
--total-executor-cores 1 \
/root/app/hadoop-2.6.0-cdh5.7.0/lib/sql-1.0-SNAPSHOT-jar-with-dependencies.jar \
hdfs://hadoop:8020/imooc/input/* hdfs://hadoop:8020/imooc/output/stat
(5)查看输出结果
./app/spark-2.4.2-bin-hadoop2.6/bin/spark-shell --master local[2] --jars /root/software/mysql-connector-java-5.1.47-bin.jar
#parquet文件在hdfs://hadoop:8020/imooc/output/stat目录下
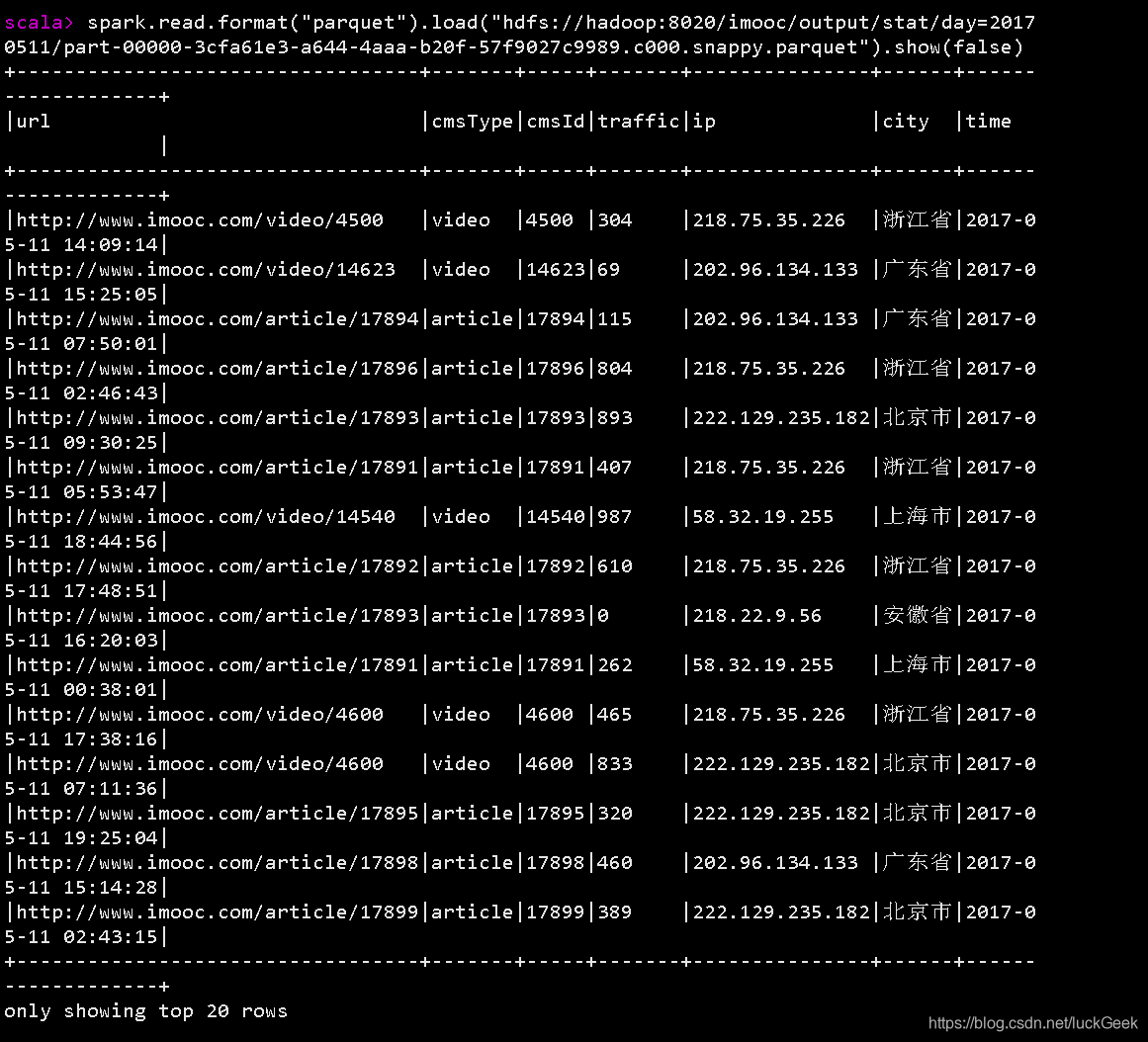
spark.read.format("parquet").load("hdfs://hadoop:8020/imooc/output/stat/day=20170511/*").show(false)
执行结果

















 801
801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









