



 本文详述了在CentOS 6.5上如何搭建基于Hadoop的Spark环境,包括下载源码、编译、解压、配置修改等步骤,并通过《青春》一文进行词频统计来验证环境搭建成功。
本文详述了在CentOS 6.5上如何搭建基于Hadoop的Spark环境,包括下载源码、编译、解压、配置修改等步骤,并通过《青春》一文进行词频统计来验证环境搭建成功。
概述:本文主要介绍CentOS 6.5下基于Hadoop的Spark环境搭建过程,并实现塞缪尔·厄尔曼《青春》的词频统计,Spark的具体搭建过程如下:
1、下载并解压Spark源码
https://archive.apache.org/dist/spark/spark-2.4.3/spark-2.4.3.tgz2、编译Spark
如果需要获取适配Hadoop的spark版本,可在Linux中对spark源码进行编译,详细信息参考官网或慕课网手记
(1)编译
假设安装的Hadoop版本为3.1,支持Hive操作,则编译命令如下
./build/mvn -Pyarn -Phadoop-hadoop-3.1 -Phive -Phive-thriftserver -Dhadoop.version=hadoop-3.1 -DskipTests clean package
#或在解压后的spark根路径下执行下述命令
./dev/make-distribution.sh --name 3.1-cdh5.7.0 --tgz -Pyarn -Phadoop-3.1 -Phive -Phive-thriftserver 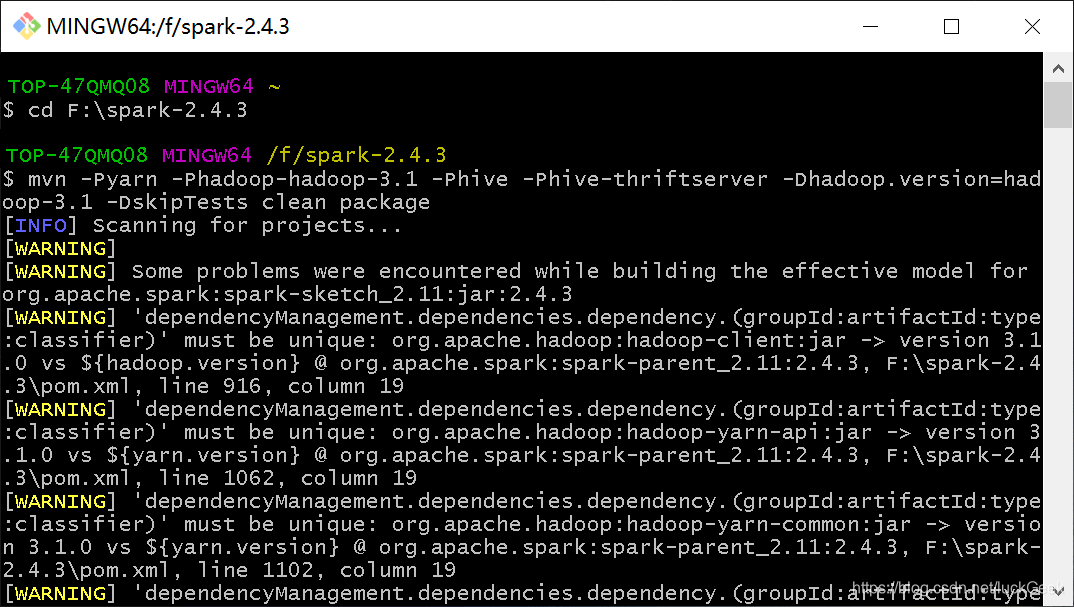
说明:Windows下编译Spark,可在Git Bash中进行,耗时较长,最终生成的压缩包为:
spark-2.4.3-bin-3.1-cdh5.7.0.tgz
(2)免编译
直接下载与hadoop对应的spark版本,如spark-2.4.2,Hadoop版本2.6 https://archive.apache.org/dist/spark/spark-2.4.2/spark-2.4.2-bin-hadoop2.6.tgz
3、解压编译后的Spark
tar -zxvf software/spark-2.4.2-bin-hadoop2.6.tgz -C app/
#新增环境变量
vi .bash_profile
#内容为
export SPARK_HOME=/root/app/spark-2.4.2-bin-hadoop2.6
export PATH=$SPARK_HOME:PATH
#使环境变量生效
source .bash_profile4、修改配置
将下载好的免编译Spark压缩包直接解压,然后修改相应配置文件
#在spark conf路径下
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
#添加如下内容(Standalone模式)
export JAVA_HOME=/root/app/jdk1.8.0_201
export HADOOP_HOME=/root/app/hadoop-2.6.0-cdh5.7.0
SPARK_MASTER_HOST=hadoop
SPARK_WORKER_CORES=2
SPARK_WORKER_MEMORY=2g
SPARK_WORKER_INSTANCES=2
#sbin下启动
./start-all.sh
#查看日志
cat /root/app/spark-2.4.2-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.master.Master-1-hadoop.out如果没有报错,日志类似如下:
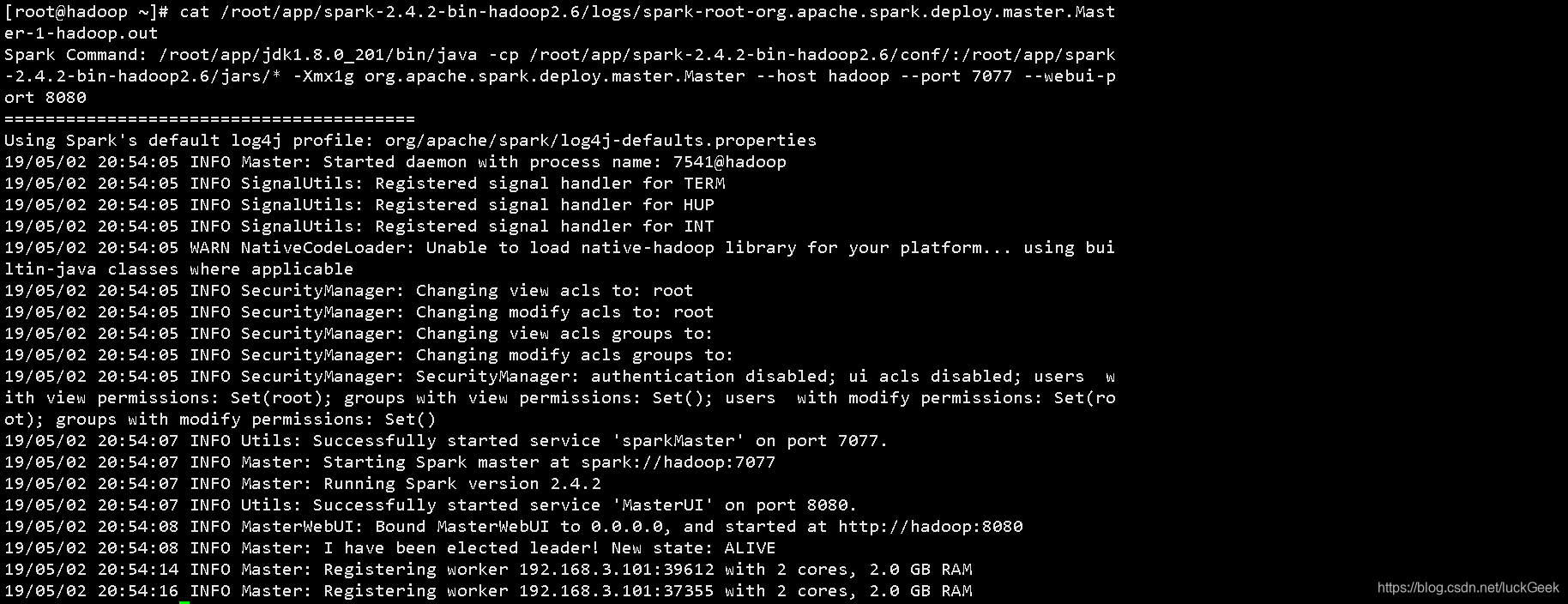
5、Spark词频统计
val file=sc.textFile("file:///root/app/hadoop-2.6.0-cdh5.7.0/bin/Youth.txt")
val wordCounts = file.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)
wordCounts.collect()
wordCounts.foreach(println)
#或使用以下两种方式读取文件
#读取本地文件
sc.textFile("file:///root/app/hadoop-2.6.0-cdh5.7.0/bin/Youth.txt").flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_).collect().foreach(println)
#读取HDFS文件
sc.textFile("hdfs://hadoop:8020/input/wc/Youth.txt").flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_).collect().foreach(println)结果如下:
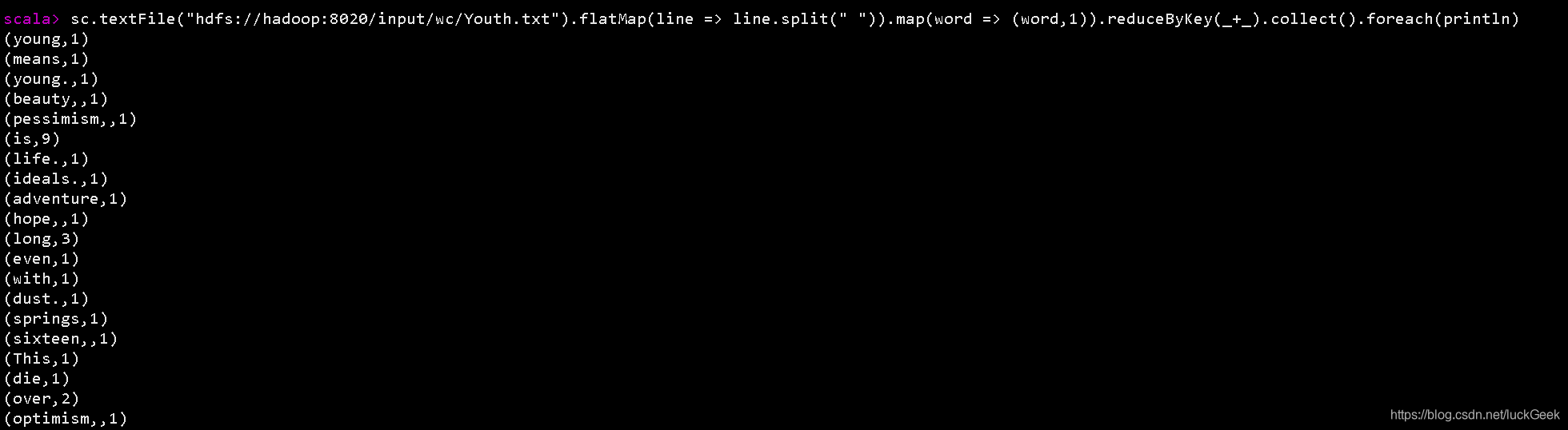

















 1391
1391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









