




一.引入基本模块
from requests-html import HTMLSession
from urllib.parse import urlparse, parse_qs
import pandas as pd
#使用代码更加美观
import pprint
二.翻页
翻页,其实就是url不同而已,但是url不同在哪我们就要对url进行拆解才能知道
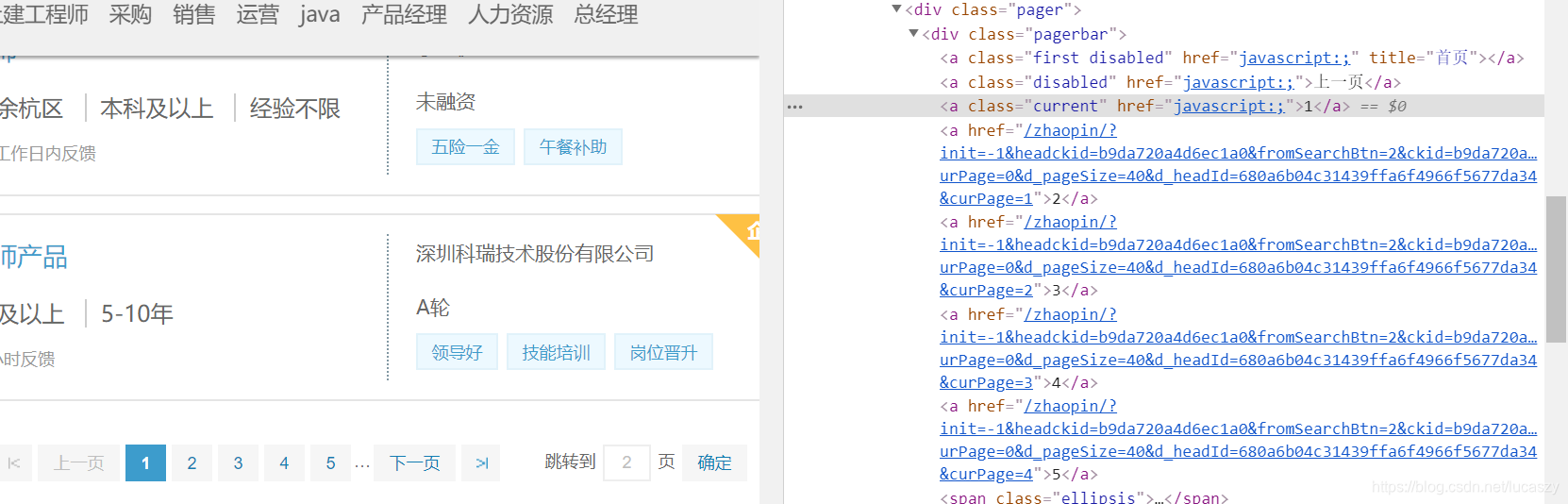
 接下来就是利用xpath把url抓取下来
接下来就是利用xpath把url抓取下来
#建立连接
url = "https://www.liepin.com/zhaopin/"
session = HTMLSession()
r = session.get( url )
#starts-with可以指定url连接开头部分,这样子可以避免抓取到无用的url,因为猎聘网有几个链接是javascript,我们要排除掉
xpath_翻页a = '//div[@class="pagerbar"]/a[starts-with(@href,"/zhaopin")]'
href_列表 = [x.xpath('//@href')[0] for x in r.html.xpath(xpath_翻页a)]
pprint.pprint(href_列表)
#使用字典存储url
#x.xpath('//@href')[0]是因为for循环输出的是一个列表,[0]才能把链接取出来
"""
href_字典={}
for x in r.html.xpath():
href_字典[x.text]=x.xpath('//@href')[0]
"""
以上等式等于以下推导式
href_字典 = {x.text:x.xpath('//@href')[0] for x in r.html.xpath(xpath_翻页a)}
pprint.pprint (href_字典)
这样就把链接抓取下来

三.建构参数模板:找到关键参数及参数结构(重点来了!!!)
- 使用 pd.DataFrame进行 nunique()相异值计量比对
- Pandas nunique() 用于获取唯一值的统计次数。
# urlparse 解析后丢入数据框,前面引入了相关模块
df = pd.DataFrame([ urlparse(x) for x in href_字典.values()])
#对url进行相异值检查
df.nunique()

pandas转换数据类型astype(int)报错问题
- 字符串转为整型数据字符串中的小数点会被认为是特殊字符而报错;
- 解决办法:先转成浮点数据,astype(int)会把数据当做数字来进行转换。
#在上面已经知道翻页url的变化其实只在query值中因此对query进一步的拆解
#字典推导式中parse_qs会把query值解析成字典,字典的值是一个列表,因此要v[0]把值取出来
df_qs = pd.DataFrame([{k:v[0] for k,v in parse_qs(x).items()} for x in df['query'] ])
#再一次对链接进行相异值检查
df_qs.nunique()
# 使curPage变成整数
#curPage_int为新一列的列名,等号左边是列名
df_qs = df_qs.assign (curPage_int=df_qs.curPage.astype(int))
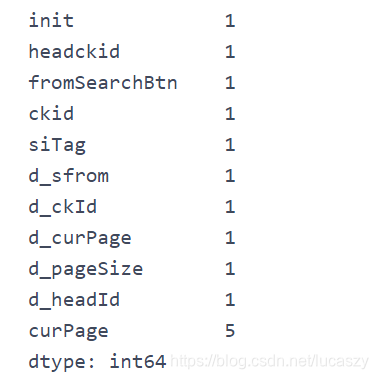
这样就会发现其实翻页的变化就是参数curPage不同而已
#这个函数就是把上面对url的拆解进行整合而已
def parse_url_qs_for_curPage (url):
six_parts = urlparse(url) #把url拆成6部分
out = parse_qs(six_parts.query)#取出query值并输出为字典out
return (out) #返回字典out
# 取一例做模板
参数模板 = parse_url_qs_for_curPage(href_列表[0])#调用该函数并取出列表'href_列表'的第一个元素作为函数的实际参数
pprint.pprint(参数模板)
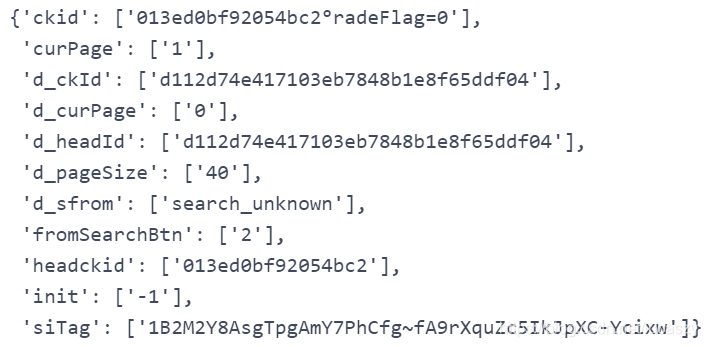
#这个函数的目的是根据想要爬取的关键词调整参数
def 参数模板生成(keyword, curPage):
参数 = 参数模板.copy()
参数['curPage'] = curPage #传进来的值替换掉原来的curPage值
参数['keyword'] = keyword #传进来的值替换掉原来的keyword值
return (参数)
#生成参数翻页字典
参数_keyword_curPage = {
i:参数模板生成(curPage = [i],
keyword = ['用户体验']) #可在此修改爬取关键词
for i in range(0,df_qs.curPage_int.max()+1)
}
print(href_字典.keys())
抓取职位信息页xpath代码如下:
#对于抓取职位信息的代码我就直接放这了,后面函数调用即可
def requests_liepin( url, params):
r = session.get( url , params = payload)
# 先取特定元素, 精准打击其子后辈
主要元素 = r.html.xpath( '//ul[@class="sojob-list"]/li')
# 作为xpath字典,键为我要抓的牛肉名称,值为xpath
dict_xpaths={
'text': {
'edu': '//div[contains(@class,"job-info")]/p/span[@class="edu"]',
'经验': '//div[contains(@class,"job-info")]/p/span[@class="edu"]/following-sibling::span',
'薪水': '//div[contains(@class,"job-info")]/p/span[@class="text-warning"]',
'时间': '//div[contains(@class,"job-info")]/p/time/@title',
'职称': '//div[contains(@class,"job-info")]/h3/a',
'公司地点': '//div[contains(@class,"job-info")]/p/a',
'公司名称': '//div[contains(@class,"sojob-item-main")]//p[@class="company-name"]/a',
},
'text_content': {
},
'href': {
'链结': '//div[contains(@class,"job-info")]/h3/a',
'公司URL': '//div[contains(@class,"sojob-item-main")]//p[@class="company-name"]/a',
}
}
def get_e_text_content(_xpath_):
# 高级列表推导
暂存结果 = [e.xpath(_xpath_)[0].lxml.text_content() for e in 主要元素]
return(暂存结果)
def get_e_text(_xpath_):
# 高级列表推导
暂存结果 = ["".join([x.strip() if type(x) is str else x.text.strip() for x in e.xpath(_xpath_)]) for e in 主要元素]
return(暂存结果)
def get_e_href(_xpath_):
# 高级列表推导
暂存结果 = [list(e.xpath(_xpath_, first=True).absolute_links)[0] \
if len(e.xpath(_xpath_, first=True).absolute_links) >= 1 \
else "" for e in 主要元素]
return(暂存结果)
# 只对主要元素下进行.xpath取值
数据字典 = dict()
数据字典 = {k:get_e_text_content(v) for k,v in dict_xpaths['text_content'].items()}
数据字典.update({k:get_e_text(v) for k,v in dict_xpaths['text'].items()})
数据字典.update({k:get_e_href(v) for k,v in dict_xpaths['href'].items()})
数据 = pd.DataFrame(数据字典)
#数据.to_excel("20春_Web数据挖掘_week03_liepin.xlsx", sheet_name="搜查结果")
return (数据)
抓取代码如下:
import time
from random import random
url = "https://www.liepin.com/zhaopin/"
list_df = list()
for k,v in 参数_keyword_curPage.items():
payload = v
df = requests_liepin( url, params = payload) #取出的值作为参数传进去
time.sleep(3+4*random()) #放慢脚步 3-7秒, 平均约5秒
df = df.assign (curPage = k) # 新开一列,等号左边是新列名字
list_df.append(df) #把所有数据添加到新列表
df_all = pd.concat(list_df).reset_index() #重塑列表并重设索引
df_all.index.name = '序' #修改索引的名
# 输出
df_all.to_excel("xxxx.xlsx",\
sheet_name="用户体验")
最后就抓到某一个关键词下的职位信息了,如有不明白欢迎在下方留言。

















 1725
1725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









