 Spark缓存机制详解
Spark缓存机制详解





 本文详细介绍了如何在Spark中使用缓存机制来提高数据处理效率。通过实例演示了从启动spark-shell,读取HDFS上的文件,将数据集缓存到内存,并触发action操作的全过程。同时,对比了缓存前后job的执行时长,展示了缓存机制在大数据处理中的应用与优势。
本文详细介绍了如何在Spark中使用缓存机制来提高数据处理效率。通过实例演示了从启动spark-shell,读取HDFS上的文件,将数据集缓存到内存,并触发action操作的全过程。同时,对比了缓存前后job的执行时长,展示了缓存机制在大数据处理中的应用与优势。
1、启动spark-shell
./spark-shell --master spark://hdp-1:7077 --executor-memory 500m --total-executor-cores 1
2、读文件
var lines = sc.textFile("hdfs://hdp-1:9000/aaa.txt")
3、将读到的文件放入缓存
var cached = lines.cache
4、出发action
cached.count
lines.count
5、观察spark的job执行时长
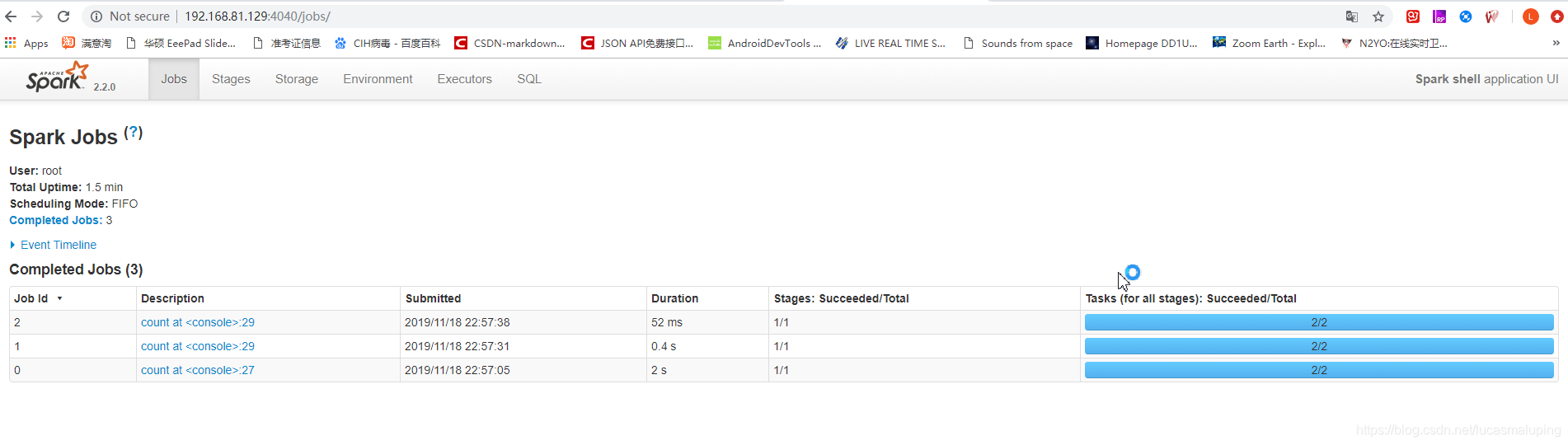
6、缓存应用扩展
cached.filter(_.contains("lucas")).count

















 2794
2794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









