



 本文介绍了ApacheHadoop项目,包括其作为可靠、开源的分布式软件,重点讲解了HDFS分布式文件系统、YARN资源管理和作业调度,以及MapReduce分布式计算框架。通过WordCount示例展示了如何使用Mapper和Reducer进行数据处理。
本文介绍了ApacheHadoop项目,包括其作为可靠、开源的分布式软件,重点讲解了HDFS分布式文件系统、YARN资源管理和作业调度,以及MapReduce分布式计算框架。通过WordCount示例展示了如何使用Mapper和Reducer进行数据处理。
官方网址:Apache Hadoop
1、hadoop是什么?
hadoop是Apache顶级项目
hadoop是一个可靠的、可扩展的、开源的、分布式软件
2、初识hadoop理解图
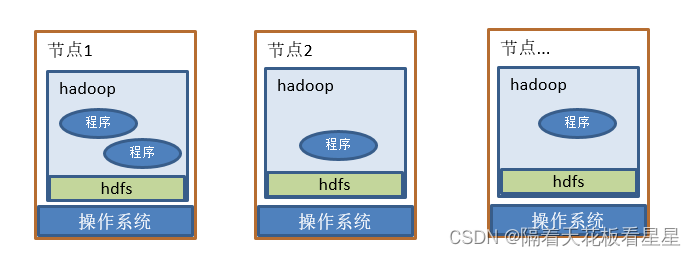
将hadoop按照官方文档部署好后,你只需要编写简单的代码就可以在多台机器上实现分布式计算
hdfs(Hadoop Distributed File System):
是hadoop分布式文件系统,意思就是可以将你要放的文件分散到多个节点上
yarn:
资源管理和作业调度/监视,可以将你写的程序移动到需要计算的数据节点进行计算,并进行状态的监控
MapReduce:
分布式计算框架,按照框架继承Mapper、Reducer,并在main方法中进行提交即可实现分布式计算了
3、示例程序WordCount
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}

















 2748
2748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









