 R语言随机数生成与数据模拟
R语言随机数生成与数据模拟







 本文详述了R语言中随机数生成的方法及数据模拟技巧,涵盖set.seed()确保随机数可重复,runif()生成指定范围内的随机数,以及通过c(), seq(), rep(), gl(), factor(), paste(), sample()等函数创建复杂数据结构。同时介绍了如何利用正则表达式处理字符串,并演示了概率函数如rnorm(), rexp()等生成符合特定分布的随机数,适用于测试数据生成和统计模拟。
本文详述了R语言中随机数生成的方法及数据模拟技巧,涵盖set.seed()确保随机数可重复,runif()生成指定范围内的随机数,以及通过c(), seq(), rep(), gl(), factor(), paste(), sample()等函数创建复杂数据结构。同时介绍了如何利用正则表达式处理字符串,并演示了概率函数如rnorm(), rexp()等生成符合特定分布的随机数,适用于测试数据生成和统计模拟。
前言
随机数用途多样,笔者常用于:生成测试数据,生成有规律的数列。
set.seed()
c()
seq()
rep()
gl()和factor()
paste()
sample()
strsplit()
R语言正则化表达式
分布函数(norm等)
概率分段函数
1 提前认识“set.seed(n)”
set.seed(n)主要是为了重复生成相同的随机数,特别用于重复性验证。只要在使用函数生成随机数之前设定set.seed(n),即可生成相同的随机数。
注释:n必须一致
#了解第一个随机数生成函数:runif
runif(n,min,max)#随机生成n个在min和max之间的随机数
#默认runif(n)中min=0,max=1
#未设置set.seed
> runif(5,0,1) #第1次未设置set.seed
[1] 0.24910169 0.58064847 0.83125620 0.20406744 0.07102857
> runif(5,0,1) #第2次未设置set.seed
[1] 0.75107020 0.57290066 0.74190823 0.07562258 0.92335997
> runif(5,0,1) #第3次未设置set.seed
[1] 0.2254366 0.2745305 0.2723051 0.6158293 0.4296715
#设置set.seed(10)
> set.seed(10) #第1次设置set.seed(10)
> runif(5,0,1)
[1] 0.50747820 0.30676851 0.42690767 0.69310208 0.08513597
> set.seed(10)
> runif(5,0,1) #第2次设置set.seed(10)
[1] 0.50747820 0.30676851 0.42690767 0.69310208 0.085135972 生成常规数据
2.1 最常见的“c”
> c(1,2,8)#生成包含1,2,8的向量
[1] 1 2 82.2 “:“ 等差生成等差为1或-1的向量
> 1.1:10
[1] 1.1 2.1 3.1 4.1 5.1 6.1 7.1 8.1 9.1
> 1:10
[1] 1 2 3 4 5 6 7 8 9 10
> 10:1 #如x=1:10(递减,如y=10:1)
[1] 10 9 8 7 6 5 4 3 2 12.3 seq 等距向量
①seq(起点,终点,步长);
②seq(length=9, from=1, to=5)
> seq(1,10,2)
[1] 1 3 5 7 9
> seq(length=5,1,10)
[1] 1.00 3.25 5.50 7.75 10.00
#seq(x)相当于1:length(x);length(x)为0时,返回integer(0)
> seq(10)
[1] 1 2 3 4 5 6 7 8 9 10
> seq(c())
integer(0)2.4 rep(x,n) 重复
#将x重复n次,可使用each限定为依次重复形式
rep(1:3,3)
rep(1:3,each=3)
#> rep(1:3,3)
#[1] 1 2 3 1 2 3 1 2 3
#> rep(1:3,each = 3)
#[1] 1 1 1 2 2 2 3 3 32.5 gl()和factor()
gl(k,n,length=,label=)构造一个因子序列。k为水平数,n为每个水平连续出现的次数,length为整个序列的长度,label为因子标签。
> gl(3,5,length=15,label=c('a','b','c'))
[1] a a a a a b b b b b c c c c c
Levels: a b cfactor(x = character(), levels, labels = levels)构造一个因子序列。x为原数据,levels是x中的不同水平,labels是与x中每个水平对应的标签。
x <- c("Man", "Male", "Man", "Lady", "Female")
## Map from 4 different values to only two levels:
xf <- factor(x, levels = c("Male", "Man" , "Lady", "Female"),
labels = c("Male", "Male", "Female", "Female"))
> xf
[1] Male Male Male Female Female
Levels: Male Female2.6 paste() 字符连接
该函数每次从每个参数中提取一个元素组成一个字符串,直至元素最多的参数取完,其它元素不足的参数循环补足。 可接受多个参数,每个参数可包括多个元素。
paste (..., rep = "@", collapse = NULL)
#sep="@"是在每个对象后加入@字符> paste(c("X","Y"), 1:10, sep="")
[1] "X1" "Y2" "X3" "Y4" "X5" "Y6" "X7" "Y8" "X9" "Y10"
> paste(c("X","Y","Z"), 1:9, sep="")
[1] "X1" "Y2" "Z3" "X4" "Y5" "Z6" "X7" "Y8" "Z9"
> paste(letters,collapse='')#将26个小写字母连成一个字符串
[1] "abcdefghijklmnopqrstuvwxyz"
> paste(letters,collapse='@')#将26个小写字母连成一个字符串
[1] "a@b@c@d@e@f@g@h@i@j@k@l@m@n@o@p@q@r@s@t@u@v@w@x@y@z"2.7 sample() 随机抽样
sample(x, size, replace = FALSE, prob = NULL)
#x被抽样数据;size抽样个数;replace = FALSE/TRUE无重复抽样/重复抽样;prob挑选概率(x与prob对应)sample(x, n, replace=FALSE)
#从x中无重复的取n个数据,replace=TRUE为可重复
> sample(1:100, 20, replace=FALSE)
[1] 71 83 24 75 35 51 9 16 99 39 68 74 85 60 44 98 20 2 87 21
> sample(letters, 20, replace=FALSE) #无重复
[1] "e" "a" "l" "c" "r" "h" "s" "z" "i" "d" "j" "g" "o" "f" "n" "y" "b" "t"
[19] "q" "m"
> sample(letters, 20, replace= TRUE) #可重复
[1] "t" "o" "l" "c" "f" "b" "n" "q" "n" "b" "o" "j" "y" "g" "f" "w" "m" "f"
[19] "q" "f"sample(x) #对x进行堆积排序,可用于打乱原始数据顺序
x = c(1:20)
sample(x)#随机排列x
[1] 7 2 20 18 15 14 16 17 9 5 8 10 19 4 11 6 12 3 13 1sample(c(0,1), 10, replace=TRUE, prob=c(0.2, 0.8))
#分别以0.2和0.8的概率抽取0和1
> sample(c(0,1), 10, replace=TRUE, prob=c(0.2, 0.8))
[1] 1 1 1 1 1 1 1 1 0 02.8 strsplit(x) 字符分割
strsplit(x, split, fixed = FALSE, perl = FALSE)
#根据split将x分割,若split=“”,则将x分为单个字符。
> strsplit("split","", fixed = FALSE, perl = FALSE)
[[1]]
[1] "s" "p" "l" "i" "t"
#默认split为正则表达式,可使用fixed=TRUE,对split做精确匹配
#当perl=TRUE时,使用perl的正则表达式规则
#当分隔符为?, +, {, |, (, )时,要使用'\\'来消除特殊含义
> x
[1] "a5aa646a4d9a4da1d3a49d79a41d1da"
> strsplit(x, "\\d") #根据每个数字分割
[[1]]
[1] "a" "aa" "" "" "a" "d" "a" "da" "d" "a" "" "d" "" "a" "" "d" "da"
> strsplit(x, "[:alnum:]") #任何一个字母或数字(等价于[a-ZA-Z0-9])
[[1]]
[1] "" "5" "" "646" "4d9" "4d" "1d3" "49d79" "41d1d"R语言之正则表达式
https://www.cnblogs.com/wheng/p/6262737.html
2.9 R语言中正则表达式转义字符
| 正则化表达式转义字符 | ||
| 空白元字符 | [\b] | 回退(并删除)一个字符(backspace) |
| \f | 换页符 | |
| \n | 换行符 | |
| \r | 回车符 | |
| \t | 制表符(tab) | |
| \v | 垂直制表符 | |
| 注:\r\n是windows所用的文本行结束符,Unix和Linux只是用一个换行符来结束一个文本行 | ||
| 匹配数字与非数字 | \d | 任何一个数字字符,等价于[0-9] |
| \D | 任何一个非数字字符,等价于^[0-9] | |
| 匹配字母\非字母与数字 | \w | 任何一个字母数字字符(大小写均可以)或下划线字符(等价于[a-zA-Z0-9]) |
| \W | 任何一个非字母数字或下划线字符(等价于[^a-zA-Z0-9]) | |
| 匹配空白字符 | \s | 任何一个空白字符(等价于[\f\n\r\t\v]) |
| \S | 任何一个非空白字符(等价于[^\f\n\r\t\v]) | |
| POSIX字符类 | [:alnum:] | 任何一个字母或数字(等价于[a-ZA-Z0-9]) |
| [:alpha:] | 任何一个字母(等价于[a-ZA-Z]) | |
| [:blank:] | 空格或制表符(等价于[\t ]) 注:t后面有一个空格 | |
| [:cntrl:] | ASCII控制字符(ASCII 0到31,再加上ASCII 127) | |
| [:digit:] | 任何一个数字(等价于[0-9]) | |
| [:graph:] | 和[:print:]一样,但不包括空格 | |
| [:lower:] | 任何一个小写字母(等价于[a-z]) | |
| [:print:] | 任何一个可打印字符 | |
| [:punct:] | 既不属于[:alnum:],也不属于[:cntrl:]的任何一个字符 | |
| [:space:] | 任何一个空格字符,包括空格(等价于[f\n\r\t\v ] 注:v后面有一个空格 | |
| [:upper:] | 任何一个大写字母(等价于[A-Z]) | |
| [:xdigit:] | 任何一个十六进制数字(等价于[a-fA-F0-9]) | |
| 其他 | . | 可以匹配任何单个的字符字母数字甚至.字符本身。同一个正则表达式允许使用多个.字符。但不能匹配换行 |
| \\ | 转义字符,如果要匹配就要写成“\\(\\)” | |
| | | 表示可选项,即|前后的表达式任选一个 | |
| ^ | 取非匹配 | |
| $ | 放在句尾,表示一行字符串的结束 | |
| () | 提取匹配的字符串,(\\s*)表示连续空格的字符串 | |
| [] | 选择方括号中的任意一个(如[0-2]和[012]完全等价,[Rr]负责匹配字母R和r) | |
| {} | 前面的字符或表达式的重复次数。如{5,12}表示重复的次数不能小于5,不能多于12,否则都不匹配 | |
| * | 匹配零个或任意多个字符或字符集合,也可以没有匹配 | |
| + | 匹配一个或多个字符,至少匹配一次 | |
| ? | 匹配零个或一个字符 | |
3 生成拟合概率函数的数据
统一的形式:前缀+分布函数名。
d 表示密度函数(density);
p 表示分布函数(生成相应分布的累积概率密度函数);
q 表示分位数函数,能够返回特定分布的分位数(quantile);
r 表示随机函数,生成特定分布的随机数(random)。
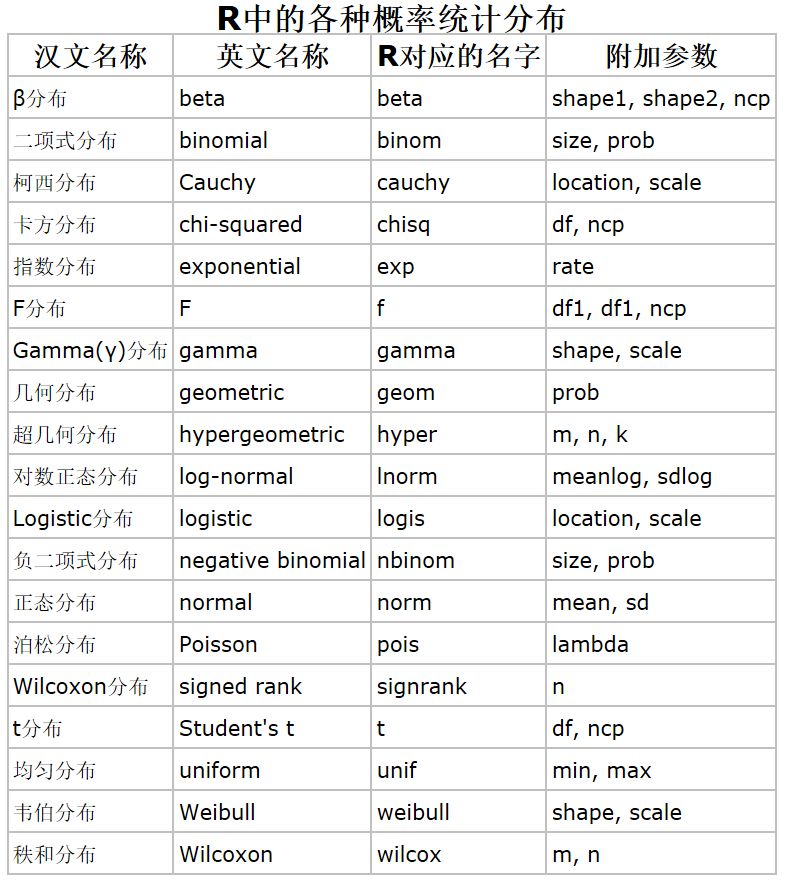
各种分布的随机数样例:
rnorm(n, mean=0, sd=1) #正态分布
#> rnorm(10, mean=0, sd=1) #n=10,生成10个拟合标准正太分布的随机数
# [1] 0.6715239 -1.3813153 -1.3577117 0.2135950 0.2826674 -0.3110641
# [7] -1.0306989 -0.4910372 0.9163312 0.1502577
#其他以此类推
rexp(n, rate=1) #指数
rgamma(n, shape, rate=1, scale=1/rate) #r 分布
rpois(n, lambda) #泊松
rt(n, df, ncp) #t 分布
rf(n, df1, df2, ncp) #f 分布
rbinom(n, size, prob) #二项分布
rweibull(n, shape, scale=1) #weibull 分布
rbata(n, shape1, shape2) #bata 分布runif(n,min=0,max=1) #均匀分布4 生成离散随机变量(借助for循环)
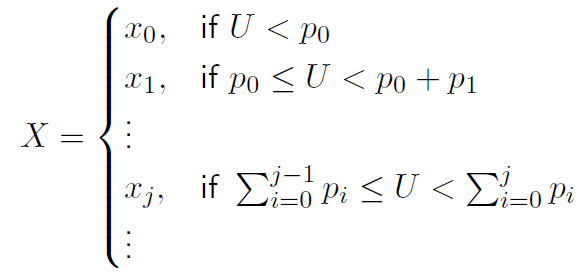
#方法一:设计disrand函数
p1<-0.15
p2<-0.2
p3<-0.3
p4<-0.35
disrand<-function(i){
u<-runif(1,0,1) #生成0-1之间的一个随机数
if(u<p1) x <- 1 else #如果随机数u小于p1
if(u<p2+p2) x <- 2 else #如果随机数u大于等于p1且小于p2+p2
if(u<p3+p2+p1) x <- 3 else
x <- 4
return(x) #返回x
}
Xa <- rep(NA,100) #生成一个有100个NA的向量,用于存放生成的随机数
for (i in 1:100)
Xa[i] <- disrand(i)
Xa
#> Xa
# [1] 1 1 2 3 2 4 1 1 2 4 4 2 2 2 2 4 2 4 4 4 3 2 4 1 1 1 2 4 1 3 1 3 4 2 4 2
# [37] 2 4 4 1 4 3 2 4 3 4 3 3 3 4 4 3 4 2 2 1 4 4 2 1 4 2 4 2 4 1 2 2 1 4 4 3
# [73] 4 4 4 4 4 2 4 1 4 3 4 3 4 1 4 4 4 2 3 4 3 2 3 2 4 4 1 4#方法二:sample抽样函数
> sample(c(1,2,3,4), 100, replace=TRUE, prob=c(0.15, 0.2,0.3,0.35))
[1] 3 3 1 4 2 4 1 3 2 2 4 3 3 4 3 2 4 1 2 2 4 1 3 4 4 2 3 3 4 2 1 4
[33] 2 3 4 3 4 3 4 1 4 1 2 4 2 1 2 2 2 4 4 1 4 1 4 1 1 3 3 1 1 1 2 1
[65] 3 3 1 4 3 4 4 4 3 3 1 2 4 3 4 2 4 3 2 3 1 4 4 4 4 3 2 3 4 1 2 4
[97] 4 3 4 1
推荐参考书籍

















 685
685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









