






参考链接:
Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
scrapy.Request是没办法处理动态渲染网页的,而使用request-html等常见的渲染方法又难以契合Scrapy框架。
这里呢推荐使用Splash,在做好配置后,原Scrapy框架下只能处理静态网页的代码只需稍微改动便可处理动态网页。
改动1:导入Splash包
from scrapy_splash import SplashRequest #重新定义了请求改动2:将scrapy.Request 改为 SplashRequest
改动3:在settings文件最后添加如下语句
#Splash服务器地址
SPLASH_URL = 'http://localhost:8050'
#开启两个下载中间件,并调整HttpCompressionMiddlewares的次序
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware':725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware':810,
}
#设置去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
#用来支持cache_args(可选)
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware':100,
}
DUPEFILTER_CLASS ='scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE ='scrapy_splash.SplashAwareFSCacheStorage'这样,程序就能爬取动态网页了,十分的方便,不用写bug了
配置可查看文章开头的第二个链接,里边写的很清楚。我这里就写一下大致流程
1.先安装Dockerapp。下载地址
2.安装好后打开app,可能会提示你下载Linux 内核更新包,应该会给你弹出这个网页,按照提示下载执行即可正常运行Dockerapp。
3.设置镜像源地址。
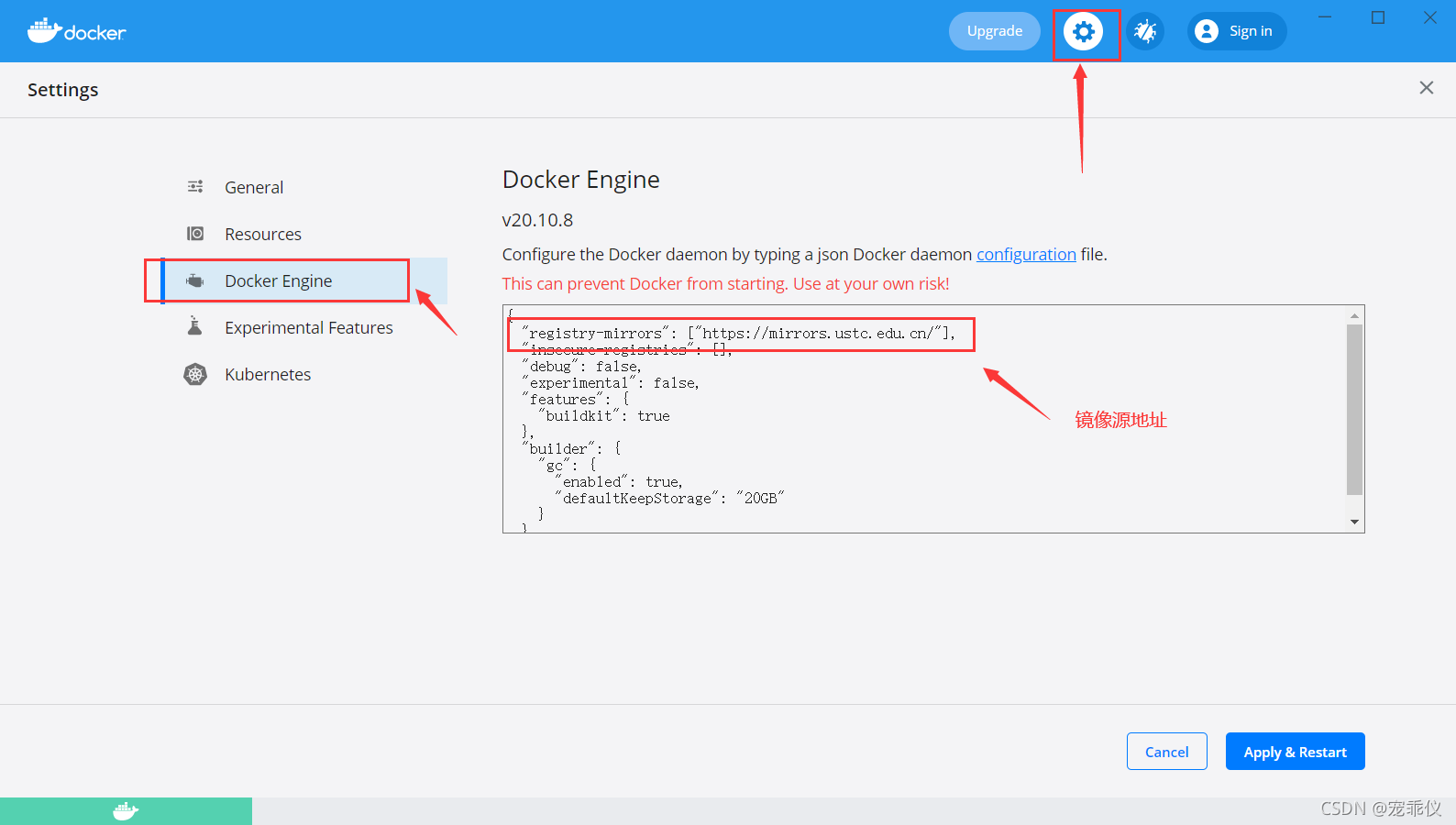
这里给出我的设置,方便复制
{
"builder": {
"features": {
"buildkit": true
},
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"experimental": false,
"registry-mirrors": [
"https://mirrors.ustc.edu.cn/"
]
}4.打开cmd,分别执行如下语句
- 4.1
docker ps- 4.2 拉取镜像。安装需要耗费一点时间,等待即可
docker pull scrapinghub/splash- 4.3 用docker运行scrapinghub/splash
docker run -p 8050:8050 scrapinghub/splash5.不要关掉docker,此时运行你的爬虫程序,即可

















 355
355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









