




 本文详细解析了Spark中的容错与鲁棒性增强机制,包括应用、Executor、Stage及Task级别的重试策略,shuffle IO、RPC重试机制,推测执行、黑名单机制、Cache与Checkpoint策略,旨在提升Spark作业的稳定性和效率。
本文详细解析了Spark中的容错与鲁棒性增强机制,包括应用、Executor、Stage及Task级别的重试策略,shuffle IO、RPC重试机制,推测执行、黑名单机制、Cache与Checkpoint策略,旨在提升Spark作业的稳定性和效率。
哎,我又来写文章了!
最近在看spark源码(照着这本书看的《Spark内核设计的艺术架构设计与实现》),想整理一些东西(一些以前面试被问到的在我脑中没有体系的知识点吧)
一、任务运行中主要的一些重试机制
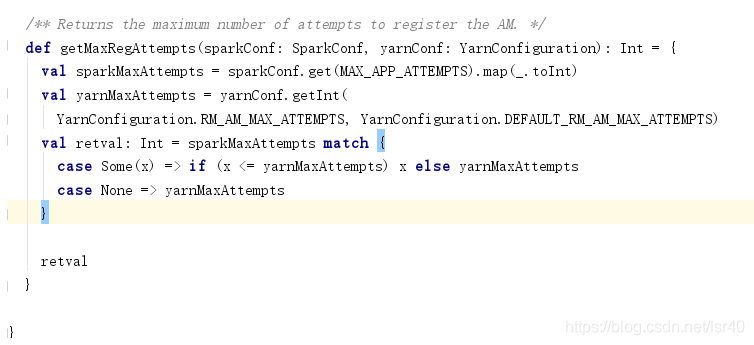
1、Application级别的容错
spark.yarn.maxAppAttempts
如果没有手动配置这个参数,那就会使用集群的默认值yarn.resourcemanager.am.max-attempts,默认是2,这是hadoop的yarn-site.xml里面配置的,当然spark.yarn.maxAppAttempts要小于yarn.resourcemanager.am.max-attempts值,才生效
在YarnRMClient类中:
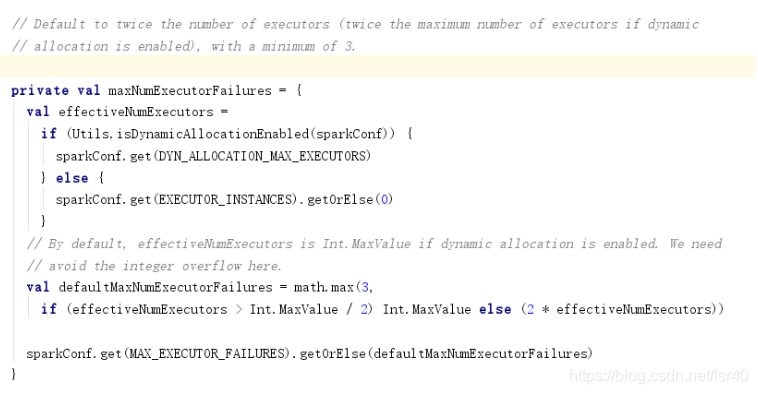
2、executor级别的容错
spark.yarn.max.executor.failures
当executor挂了一定个数之后,整个任务就会挂掉
讲真的,这个我找了好久,但是就是找不到executor死掉之后,是否会重新启动几个executor,只找到相关的代码死后如何清理相关信息,然后把死掉的task全部扔到其他executor上执行
不过我好像还没遇到过因为executor挂太多导致整个任务失败的
在ApplicationMaster类中:
3、stage级别的容错
| spark.stage.maxConsecutiveAttempts |
4 |
Number of consecutive stage attempts allowed before a stage is aborted. |
2.2.0 |
一个stage失败了,会重试,通过如上的参数设置
4、task级别的容错
| spark.task.maxFailures |
4 |
Number of failures of any particular task before giving up on the job. The total number of failure |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 832
832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









