




 本文讨论了大语言模型(LLMs)的幻觉问题,包括幻觉的分类(如输入冲突、上下文冲突和事实冲突)、检测方法、评估基准,以及来自哈尔滨工业大学和华为、腾讯AI的综述论文,强调了解决幻觉的挑战和未来研究方向。
本文讨论了大语言模型(LLMs)的幻觉问题,包括幻觉的分类(如输入冲突、上下文冲突和事实冲突)、检测方法、评估基准,以及来自哈尔滨工业大学和华为、腾讯AI的综述论文,强调了解决幻觉的挑战和未来研究方向。
引言
在使用ChatGPT或者其他大模型时,我们经常会遇到模型答非所问、知识错误、甚至自相矛盾的问题。
虽然大语言模型(LLMs)在各种下游任务中展示出了卓越的能力,在多个领域有广泛应用,但存在着幻觉的问题:即生成与用户输入不符、与先前生成的内容矛盾或与已知世界知识不符的内容。
这种现象对LLMs在现实世界场景中的可靠性构成了重大挑战。在准确率要求非常高的场景下幻觉是不可接受的,比如医疗领域、金融领域等。
目前在LLM幻觉问题上已经有无数的研究,比如关于幻觉的检测、幻觉的评估基准分类、缓解幻觉的方法等。
今天我会结合几篇有关LLM幻觉问题的综述论文,来理解LLM幻觉的分类、检测方法、评估和基准、减轻方法等。
最近的一篇是来自哈尔滨工业大学和华为的研究团队,长达49页,对有关LLM幻觉问题的最新进展来了一个全面而深入的概述。
这篇综述(下文简称:综述1)从LLM幻觉的创新分类方法出发,深入探究了可能导致幻觉的因素,并对检测幻觉的方法和基准进行了概述。

论文链接:https://arxiv.org/abs/2311.05232
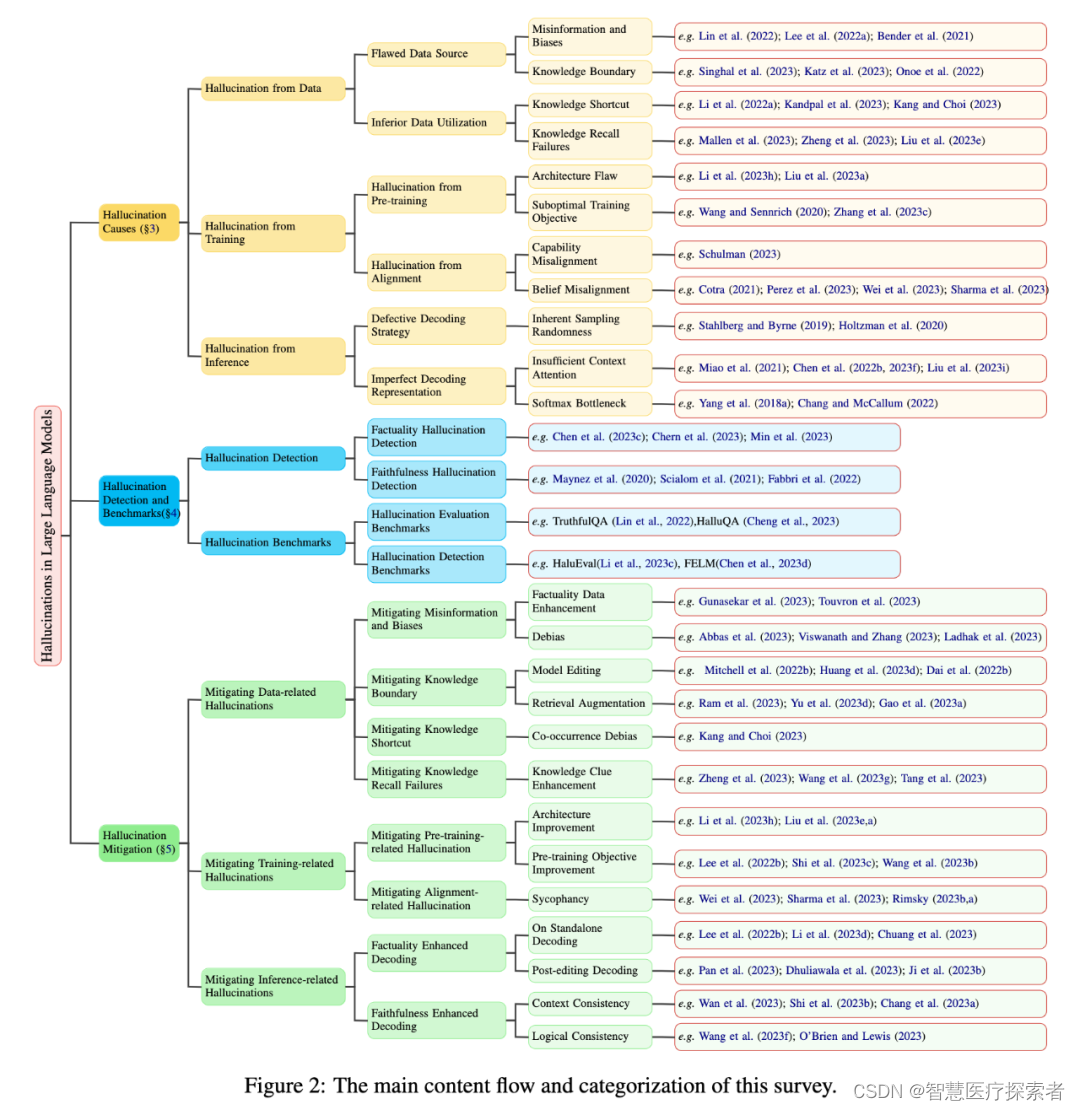
另外还有一篇综述(下文简称:综述2),来自腾讯AI实验室和一些国内大学的研究团队,综述提出了LLM幻觉现象的分类法和评估基准,分析旨在减轻LLM幻觉的现有方法,并确定未来研究的潜在方向。

论文链接:https://arxiv.org/pdf/2309.01219.pdf
还有一篇有关幻觉的论文(下文简称:论文1),对各种文本生成任务中的幻觉现象进行了新的分类,从而提供了理论分析、检测方法和改进方法。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1308
1308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











