




 文章讲述了在训练LSTM网络时遇到的错误,涉及retain_graph设置问题。作者发现错误源于在for循环梯度反向传播中使用了循环外部的变量。通过将变量初始化移动到for循环内部,解决了问题。同时介绍了Conda这个包管理器和环境管理工具在Python项目中的重要性。
文章讲述了在训练LSTM网络时遇到的错误,涉及retain_graph设置问题。作者发现错误源于在for循环梯度反向传播中使用了循环外部的变量。通过将变量初始化移动到for循环内部,解决了问题。同时介绍了Conda这个包管理器和环境管理工具在Python项目中的重要性。
1 问题描述
在训练lstm网络过程中出现如下错误:
Traceback (most recent call last):
File "D:\code\lstm_emotion_analyse\text_analyse.py", line 82, in <module>
loss.backward()
File "C:\Users\lishu\anaconda3\envs\pt2\lib\site-packages\torch\_tensor.py", line 487, in backward
torch.autograd.backward(
File "C:\Users\lishu\anaconda3\envs\pt2\lib\site-packages\torch\autograd\__init__.py", line 200, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed). Saved intermediate values of the graph are freed when you call .backward() or autograd.grad(). Specify retain_graph=True if you need to backward through the graph a second time or if you need to access saved tensors after calling backward.
2 问题分析
按照错误提示查阅相关资料了解到,实际上在大多数情况下retain_graph都应采用默认的False,除了几种特殊情况:
- 一个网络有两个output分别执行backward进行回传的时候: output1.backward(), output2.backward().
- 一个网络有两个loss需要分别执行backward进行回传的时候: loss1.backward(), loss2.backward().
但本项目的LSTM训练模型不属于以上情况,再次查找资料,在在pytorch的官方论坛上找到了真正的原因:
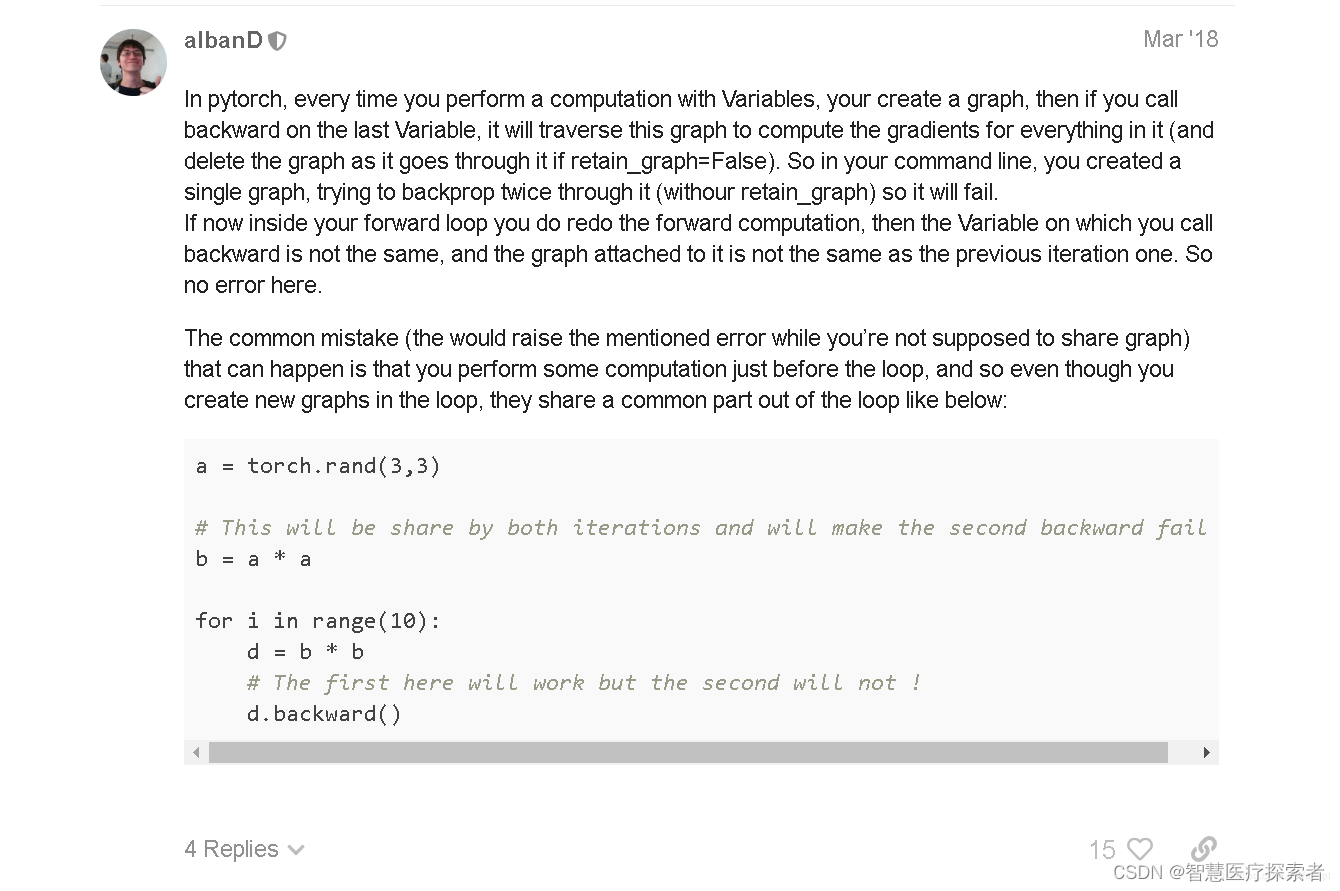
如截图中的描述,只要我们对变量进行运算了,就会加进计算图中。所以本项目的问题在于在for循环梯度反向传播中,使用了循环外部的变量h,如下所示:
epochs = 128
step = 0
model.train() # 开启训练模式
for epoch in range(epochs):
h = model.init_hidden(batch_size) # 初始化第一个Hidden_state
for data in tqdm(train_loader):
x_train, y_train = data
x_train, y_train = x_train.to(device), y_train.to(device)
step += 1 # 训练次数+1
x_input = x_train.to(device)
model.zero_grad()
output, h = model(x_input, h)
# 计算损失
loss = criterion(output, y_train.float().view(-1))
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), max_norm=5)
optimizer.step()
if step % 10 == 0:
print("Epoch: {}/{}...".format(epoch + 1, epochs),
"Step: {}...".format(step),
"Loss: {:.6f}...".format(loss.item()))
3 问题解决
代码修改如下:
epochs = 128
step = 0
model.train() # 开启训练模式
for epoch in range(epochs):
for data in tqdm(train_loader):
h = model.init_hidden(batch_size) # 初始化第一个Hidden_state
x_train, y_train = data
x_train, y_train = x_train.to(device), y_train.to(device)
step += 1 # 训练次数+1
x_input = x_train.to(device)
model.zero_grad()
output, h = model(x_input, h)
# 计算损失
loss = criterion(output, y_train.float().view(-1))
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), max_norm=5)
optimizer.step()
if step % 10 == 0:
print("Epoch: {}/{}...".format(epoch + 1, epochs),
"Step: {}...".format(step),
"Loss: {:.6f}...".format(loss.item()))
在for循环内部初始化状态变量,内部变量参与梯度传播,问题解决。
4 conda环境介绍
Conda是一个开源的包管理器和环境管理系统,用于安装、运行和更新包和其依赖项。它是由Anaconda, Inc.(以前称为Continuum Analytics)创建,用于支持Python程序开发,但它也可以用来管理来自其他语言的包。Conda使得包管理和环境隔离变得简单,对于处理多个项目中的依赖关系和版本控制尤其有用。

Conda是一个强大的工具,对于管理复杂的Python项目和环境至关重要。它简化了包管理和环境设置,使得Python开发更加容易和高效。通过使用Conda,开发者可以确保他们的项目在不同机器和操作系统上都能以相同的方式运行,大大提高了项目的可移植性和可复现性。
4.1 Conda的核心功能
-
包管理:Conda作为包管理器,可以安装、更新和移除Python包。它通过Conda仓库,如Anaconda Cloud或Conda Forge,来获取包。
-
环境管理:Conda允许用户创建隔离的环境,以便于不同项目可以拥有不同的库和/或Python版本。这在处理不兼容的依赖项或不同项目的需求时非常有用。
-
跨平台:Conda支持Linux、OS X和Windows,并允许创建跨平台的Python环境。
-
开源:Conda是开源的,允许用户查看源代码并对其进行改进。
4.2 使用Conda的优势
-
解决依赖性问题:Conda可以自动解决包之间的依赖关系,简化了安装过程。
-
环境隔离:创建独立的环境可以避免包之间的版本冲突,使得项目更稳定。
-
易于使用:Conda的命令行界面简单直观,易于学习和使用。
-
广泛的包支持:Conda支持Python的许多流行库和应用程序。
-
社区支持:作为一个流行的工具,Conda拥有一个活跃的社区,用户可以从中找到支持和资源。
4.3 Conda环境的创建和管理
-
创建新环境:使用
conda create命令创建一个新环境,可以指定Python版本和所需的包。 -
激活环境:使用
conda activate命令来激活环境。 -
安装包:在激活的环境中使用
conda install命令来安装新的包。 -
环境列表:使用
conda env list来查看所有可用的Conda环境。 -
移除环境:使用
conda env remove命令来移除不再需要的环境。
4.4 应用场景
- 数据科学和机器学习:Conda非常适合于数据科学和机器学习项目,这些项目通常需要多个库和框架。
- 软件开发:软件开发者使用Conda来管理项目依赖,确保一致的开发环境。
- 教学和学术研究:教师和研究人员使用Conda来创建具有特定库和工具的环境,用于教学和研究。
4.5 常用命令
Conda 是一个开源的包管理器和环境管理器,广泛用于管理Python环境和包。以下是一些常用的 Conda 命令:
-
安装 Conda 包:
conda install [package-name]: 安装指定的包。
-
创建和管理环境:
conda create --name [env-name]: 创建一个新的环境。conda activate [env-name]: 激活指定环境。conda deactivate: 退出当前环境。conda env list: 列出所有可用的环境。
-
管理包:
conda list: 在当前环境中列出所有已安装的包。conda update [package-name]: 更新指定的包。conda remove [package-name]: 移除指定的包。
-
搜索包:
conda search [package-name]: 搜索可用的包版本。
-
环境导出和导入:
conda env export > environment.yml: 导出当前环境的配置到一个YAML文件。conda env create -f environment.yml: 使用YAML文件创建一个新环境。
-
更新 Conda:
conda update conda: 更新 Conda 到最新版本。
-
查看 Conda 信息:
conda info: 显示关于 Conda 的信息。



















 2244
2244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











