



 本文介绍了Linux集群的三种类型:负载均衡集群(LBC)、高可用集群(HAC)和高性能运算集群(HPC)。LBC通过负载调度器分发请求,减轻服务器压力,实现高性能和高可用性;HAC确保服务持续可用,通过心跳检测进行故障转移;HPC则用于处理大规模计算任务。文章详细阐述了各种集群的工作原理、调度算法和实现方法。
本文介绍了Linux集群的三种类型:负载均衡集群(LBC)、高可用集群(HAC)和高性能运算集群(HPC)。LBC通过负载调度器分发请求,减轻服务器压力,实现高性能和高可用性;HAC确保服务持续可用,通过心跳检测进行故障转移;HPC则用于处理大规模计算任务。文章详细阐述了各种集群的工作原理、调度算法和实现方法。
什么是集群
集群是一组协同工作的服务器,各有分工,对外表现为一个整体,只提供一个访问入口。
集群就是指一组(若干个)相互独立的计算机,利用高速通信网络组成的一个较大的计算机服务系统,每个集群节点(即集群中的每台计算机)都是运行各自服务的独立服务器。这些服务器之间可以彼此通信,协同向用户提供应用程序,系统资源和数据,并以单一系统的模式加以管理。当用户请求集群系统时,集群给用户的感觉就是一个单一独立的服务器,而实际上用户请求的是一组集群服务器。
为什么要学习集群
单个服务器的能力终究是有上限的,面对海量信息,单台服务器远不能承担数据带来的压力,所以就需要多台服务器组成集群分享压力协同工作。
集群具有以下优点:
(1)高性能
一些重要的计算密集型应用如天气预报等,需要计算机有很强的运算处理能力。单台服务器不满足计算能力,很难单独完成此任务,因此对于这类复杂的计算业务,使用计算机集群技术,集中几十上百台计算机进行计算。
(2)价格性价比
通常一套系统集群架构,只需要几台或数十台服务器主机即可。与动辄价值上百万元的专用超级计算机相比便宜了很多。在达到同样性能需求的条件下,采用计算机集群架构比采用同等运算能力的大型计算机具有更高的性价比。
(3)可伸缩性
当服务负载,压力增长时,针对集群系统进行较简单的扩展即可满足需求,且不会降低服务质量。集群中的节点数目可以增长到几千乃至上万个,其伸缩性远超单台超级计算机。
(4)高可用性
单一的计算机系统总会面临设备损毁的问题,如CPU,内存,主板之类部件损坏,这时可能会导致计算机系统宕机,无法停供正常服务。在集群系统中,集群架构技术可以使系统在若干硬件设备故障时仍可以正常工作,将系统的停机时间减少到最少。
(5)透明性
多个独立计算机组成的松耦合集群系统构成一个虚拟服务器。用户或客户端程序访问集群系统时,就像访问一台高性能,高可用的服务器一样,集群中一部分服务器的上线,下线不会中断整个系统服务,这对用户也是透明的。
(6)可编程性
在集群系统上,容易开发及修改各类应用程序。
集群的分类
负载均衡集群_LBC: 分担服务的总体压力
高可用集群_HAC:尽可能的保障服务状态的可用性
高性能运算集群_HPC:提供单台服务器提供不了的计算能力
(1)负载均衡集群_LBC:(适用于业务较大的并发处理场景)
作用:减轻单台服务器的压力,把很多客户集中的访问请求负载压力尽可能平均地分摊在计算机集群中各服务器进行处理。这样的系统非常适合使用同一组应用程序为大量用户提供服务的模式,每个节点都可以承担一定的访问请求负载压力,并且可以实现访问请求在各节点之间动态分配,以实现负载均衡。
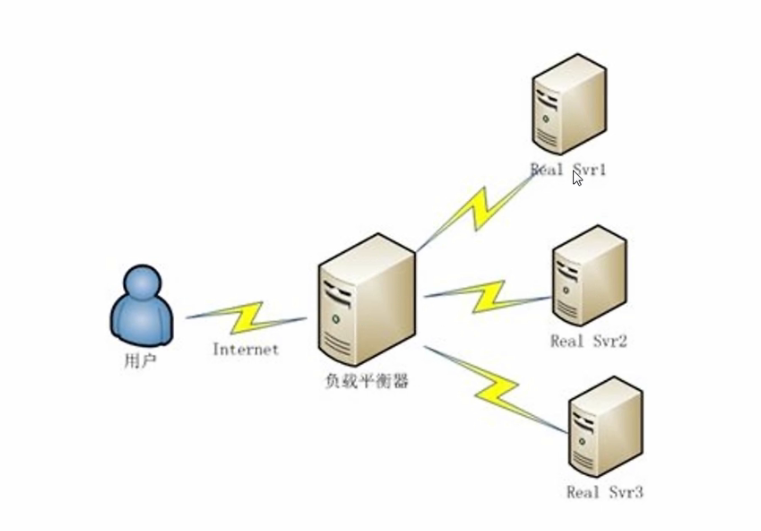
负载均衡集群运行时,一般是通过一个或多个前端负载均衡器将客户访问请求分发到后端的一组服务器上,从而达到整个系统的高性能和高可用性。一般好可用性集群和负载均衡集群会使用类似的技术,或同时具有高可用性和负载均衡的特点。
实现方法:
软件:LVS,Nginx,Haproxy等
硬件:F5(思科中继设备)
层级:
F5二层负载调度器;
LVS四层负载调度器:工作在传输层,转发数据依靠的是三层的ip和四层的port(效率更 高)
四层工作逻辑:
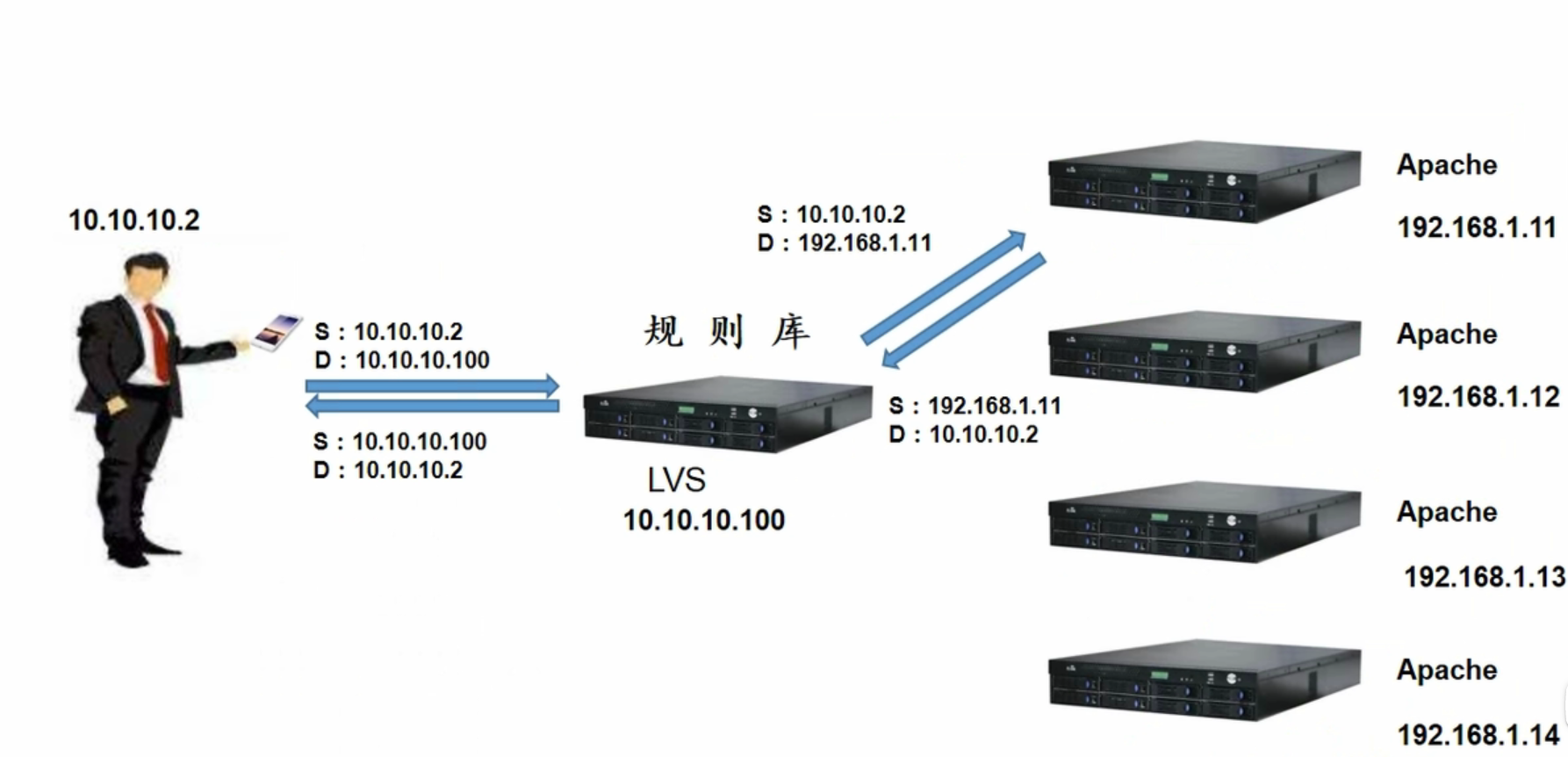
TCP连接只有一次,用户连接真实服务器。
LVS只做了地址信息的更改,并没有真实的流量转发以及流量生产,这就是负载均衡能力之高的特性。减轻LVS负载均衡的压力。
LVS负载均衡服务器的压力处理,就是整个服务器的瓶颈。
Nginx七层负载调度器:工作在应用层。转发数据依靠URL或主机名(针对性更强)
七层工作逻辑 :

1.TCP连接建立两次,客户端和负载调度器;负载调度器和RS主机。
2.Nginx服务器做真实的流量转发,负载压力较大。
使用范围:
LVS: TCP 应用为主; 应用:OA、ERP
Nginx:以HTTP协议为主,根据用户访问进行判断调度。
名词解释:
CIP:客户端IP
DIP:负载调度器IP
VIP:集群IP
RIP:真实服务器IP
LVS工作模式分类
1.NAT地址转换模式:
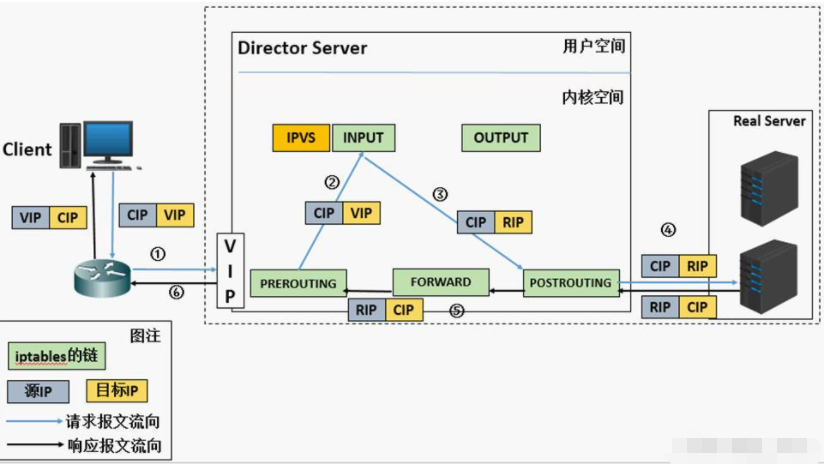
工作流程:
客户端将请求交给负载调度器,客户端发出数据包,此时这个数据包的源IP为CIP,目标目标IP为VIP(集群ip)
数据包到达负载调度器后,修改数据包的目标ip地址为真实服务器的IP,此时数据包的源IP为CIP,目标ip为RIP
将数据包发送给RS,之后RS响应将数据包发回给负载调度器,此时数据包的源IP为RIP,目标IP为CIP
负载调度器在转发时,会将源ip地址改为自己的VIP地址,然后再发给客户端,此时数据包的源ip为VIP,目标ip为CIP。
特点
负载调度器和真实服务器,必须位于同一网络。
真实服务器的网关必须指向DIP
负载调度器必须位于客户端和真实服务器之间
RIP通常都是私有地址,仅用于各个集群节点通信
支持端口映射
真实服务器可以使用任意操作系统、负载调度器必须时LINUX系统
缺点
所有数据报文都要经过负载调度器、压力过大。
2.DR路由模式:
实现原理
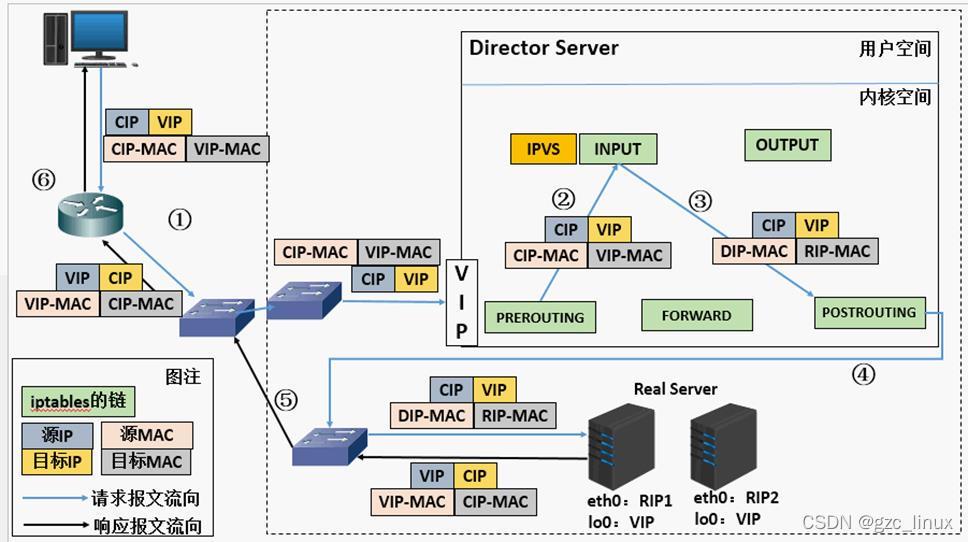
工作流程:
1.客户端发出数据包,源ip是CIP,目标是VIP
2.依靠路由把数据发送给负载调度器,负载调度器将数据包的源MAC地址修改为DIP的MAC地址, 将目标MAC地址修改为RIP的MAC地址,此时源IP和目标IP均未修改。
3.由于DS和RS在同一网络中,所以通过二层来传输,通过路由再将数据包发到RS。
4.RS接收数据包,之后通过IO接口传送给eth0向外发出,此时的源ip是VIP,目标ip为CIP。
5.最后通过路由发给客户端。
特点:
1.负载调度器和真实服务器,必须位于同一网络。
2.真是服务器的网关必须指向路由器。
3.负载调度只处理入站请求。
4.RIP可以是私有地址,也可以是公网地址。
5.真实服务器可以使用任意操作系统,负载调度器必须是LINUX系统。
优点:负载调度器压力较小,支持100台左右的RS
缺点:配置相对复杂。
3.TUN隧道模式:
实现原理
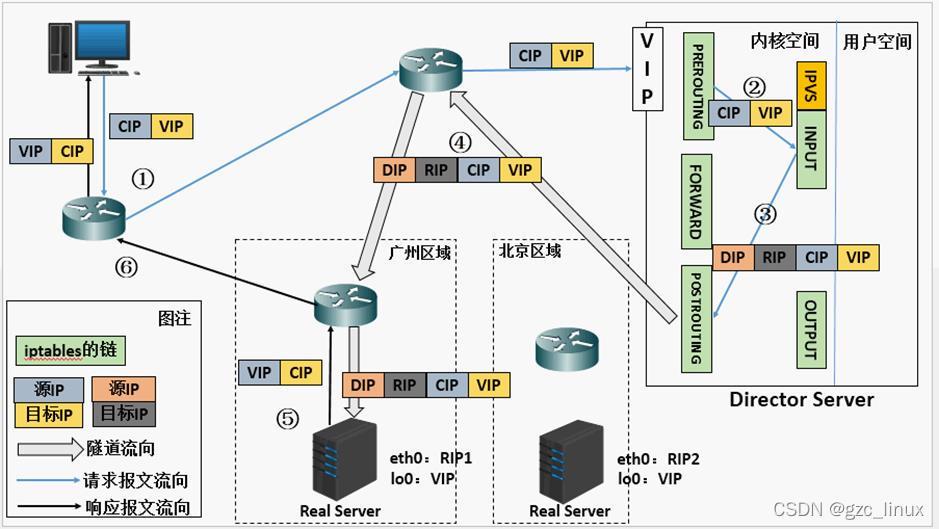
工作流程:
1.客户端发送数据包到负载调度器,此时数据包的源IP为CIP,目标ip为VIP。
2.负载调度器会在数据包的外面再次封装一层IP数据包,封装源ip为DIP,目标ip为RIP。此时源ip 为DIP,目标ip为RIP。
3.之后负载调度器将数据包发给RS(因为在外层多封装了一层ip首部,所以可以理解为此时通过隧道 传输),此时源ip为DIP,目标ip为RIP。
4.RS接收到报文后发现是自己的ip地址,就将报文接收下来,拆除掉最外层的ip后,会发现里面还 有一层IP首部,而且目标是自己的IO接口VIP,那么此时RS开始处理此请求,处理完成之后,通 过IO接口送给eth0网卡,然后向外传递。此时的源IP地址为VIP,目标ip为CIP。
5.之后将数据包发给客户端。
特点
1.所有真实服务器节点既要有RIP,又要有VIP,并且RIP,必须是公网IP
2.负载调度器和真实服务器必须支持隧道功能。
3.负载调度器只处理入站请求。
4.真实服务器一定不能使用负载调度集群做默认网关。
5.不支持端口映射
优点:可跨互联网搭建集群
缺点:对网络环境要求较高
调度器算法(通用的)
1. 静态算法:只考虑算法本身,不考虑服务器状态
rr(轮循): 从1开始到n结束。
wrr(加权轮循): 按权重比例进行调度,权重越大,负责的请求越多。
sh(源地址hash):实现会话绑定,保留之前建立的会话信息。将来自于同一个ip地址的请求发 送给一个真实服务器。
dh(目标地址hash): 将同一个目标地址的请求,发送给同一个服务器节点。提高缓存命中率。、
2.动态算法:
LC(最少连接):将新的连接请求分配给当前连接数最少的服务器。公式:活动连接*256+非活 动连接
WLC(加权最少连接):最少连接的特殊模式。 公式:(活动连接*256+非活动连接)/权重
SED(最短期望延迟):加权最少连接的特殊模式。 公式:(活动连接 +1)*256/权重
NQ(永不排队):sed的特殊模式,当某台真实服务器连接为0时,直接分配,不计算。
LBLC(基于局部性的最少连接):dh的特殊模式,既要提高缓存命中率,又要考虑连接 数量。先根据请求的目标IP地址寻找,最近的该目标IP
地址所有使用的服务器,如果这台服务器依然可用, 并且有能力处理该请求,调度器会尽量选择相同的服 务器,否则会继续选择其它可行的服务器。
LBLCR(带复制的基于局部性的最少连接):LBLCR=LBLC+缓存共享机制
调度器算法(LVS特有的)持久连接
特点:(1)类似于SH
(2)优先于通用算法
1.PPC(持久客户端连接):将来自于同一个客户端的所有请求统统定向至此前选定的RS;也就是只要IP相同,分配的服务器始终相同。
ipvsadm -A -t 172.16.0.8:0 -s wlc -p 120
2.PPC(持久端口连接):将来自于同一个客户端对同一个服务(端口)的请求,始终定向至此前选定的RS
ipvsadm -A -t 172.16.0.8:80 -s rr -p 120
3.PFMC:持久防火墙标记连接;将来自于同一客户端对指定服务(端口)的请求,始终定向至此选定的RS;不过它可以将俩个毫不相干的端口定义为一个集群服务。
#iptables -t mangle -A PREROUTING -d 172.16.0.8 -p tcp --dport 80 -j MARK --set-mark 10
#iptables -t mangle -A PREROUTING -d 172.16.0.8 -p tcp --dport 443 -j MARK --set-mark 10
#service iptable save
#ipvsadm -A -f 10 -s wlc -p 120
ARP通讯行为
ARP相应级别
arp-ignore
0 只要本机配置有相应IP地址就相应
1 仅在请求的目标地址配置在请求到达的网络接口上时,才给予响应
ARP通告行为
arp-announce
0 将本机任何网络接口上的任何地址都向外通告
1 尽可能避免像目标网络通告与其网络不匹配的地址信息表
2 仅向目标网络通告与其网络相匹配的地址信息
(2)高可用集群_HAC(需要持续提供服务的场景)
作用:最大限度的保证用户的应用程序持久,不间断的提供服务。(故障转移)
一般是指在集群中任意一个节点失效的情况下,该节点上的所有任务会自动转移到其他正常的节点上。此过程并不影响整个集群的运行。(常用于负载均衡器,主数据库,主存储对之间)
最大限度:
99% 87.6小时
99.9% 8.8小时
99.99% 53分钟
99.999% 5分钟
故障切换:
心跳检测:RS232串口线:串行电缆被认为是比以太网连接安全性稍好些的连接方式,因为hacker无法通过串行连接运行诸如 telnet、ssh或rsh类的程序,从而可以降低其通过已劫持的服务器再次侵入备份服务器的几率。但串行线缆受限于可用长度,因此主、备服务器的距离必须非常短。
脑分裂:在一个网络或线缆故障时导致俩个节点同时认为自己是唯一处于活动状态的服务器从而出现争用资源的场景即是所谓的“脑裂”,造成数据不完整,服务不可访问。
解决:设置参考ip,抢夺资源之前,都去ping参考ip(网关),ping不通时,不去抢资源,而是释放资源,将控制权交出去;设置冗余线路,设置两条心跳线,两个网卡,第一个测时不通,再拿第二个去测。
实现方法:
软件:双机备份软件 Keepalived,Rose,Heartbeat等
硬件:F5(思科中继设备)
使用范围:需要持续提供服务的场景。
(3)高性能运算集群_HPC
作用:高性能计算集群也称并行计算。高性能计算集群对外就好像一个超级计算机,这种超级计算机内部由数十至上万个独立服务器组成,并且在公共消息传递层上进行通信以并行运行应用程序。在生产环境中实际就是把任务切成蛋糕,然后下发到集群节点计算,计算后返回结果,然后继续领新任务计算,如此往复。
使用范围:天气预报,石油勘探,核反应模拟等。

















 765
765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









