







 本文通过实例详细讲解如何使用Python的mlxtend库实现关联规则算法,包括数据预处理、apriori算法及计算支持度、置信度、提升度。并介绍如何在PowerBI中导入Python脚本生成数据表并进行动态可视化展示,帮助业务人员理解和应用关联规则。
本文通过实例详细讲解如何使用Python的mlxtend库实现关联规则算法,包括数据预处理、apriori算法及计算支持度、置信度、提升度。并介绍如何在PowerBI中导入Python脚本生成数据表并进行动态可视化展示,帮助业务人员理解和应用关联规则。

在上一篇中,我讲解了关联规则的原理和实现步骤,如果大家看懂了,其实很好理解。但是说起来容易做起来难,如何通过工具将原始数据处理得到有效可靠的结果还是会存在问题。实际工作是让你解决问题而不只是说出解决思路。本篇就是在理论的基础上,结合实际数据来展示如何使用Python实现关联规则和如何在PowerBI中导入Python脚本生成数据表并以可视化的方式动态展示。
在使用Python解决某个问题时,其实并不是从0到1一步一步搭建,这个过程很繁琐,有时候为了实现一个小小的效果可能得绕很大的弯,所以就跟“调参侠”一样,我们往往使用别的搭好的梯子。这也是为什么Python语言这么受欢迎,因为它有很完善的开源社区和不计其数的工具库库来实现某个目的。我们在实现计算关联规则时,使用的是机器学习库mlxtend中的apriori,fpgrowth,association_rules算法。
apriori 是一种流行的算法,用于在关联规则学习中应用提取频繁项集。apriori 算法旨在对包含交易的数据库进行操作,例如商店客户的购买。如果满足用户指定的支持阈值,则项集被认为是“频繁的”。例如,如果支持阈值设置为 0.5 (50%),则频繁项集被定义为在数据库中至少 50% 的所有事务中一起出现的一组项目。
一、数据集
#导入相关的库
import pandas as pd
import mlxtend #机器学习库
#编码包
from mlxtend.preprocessing import TransactionEncoder
#关联规则计算包
from mlxtend.frequent_patterns import apriori, fpmax, fpgrowth,association_rules
pd.set_option('max_colwidth',150) #对pandas显示效果设置,列显示字段长度最长为150个字符 #导入数据集
Order = pd.read_excel("D:/orders.xlsx")
#查看数据集的大小
Order.shape
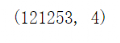
#查看数据前10行
Order.tail(5)
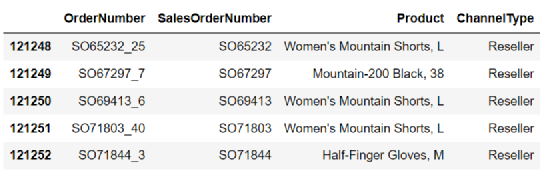
数据集中有121253条数据,总共有四个字段,SalesOrderNumber是指订单号;ordernumber是指子订单号,下换线加数字表明是订单的第几个子订单,每个订单号下可能有一个或多个子订单,而每个子订单是不重复的,对应一个产品;Product是指商品名称。
二、mlxtend
在实际开始前我们先来了解这个mlxtend中的包怎么用的。在mlxtend官网上演示了如何实现关联规则的计算,我们来看一下总共有三步:
第一步,导入apriori算法包;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









