






 本文介绍了如何通过创建拉链表来解决数据量大但变化不大的场景下,避免全量同步导致的重复数据问题。首先,通过初始化数据并设置起止时间来构建拉链表,然后在数据更新时,将新增和变更数据存储到对应日期分区,并更新旧记录的结束时间为前一天。通过全连接、条件选择和动态分区插入,实现了新旧数据的有效管理和同步。
本文介绍了如何通过创建拉链表来解决数据量大但变化不大的场景下,避免全量同步导致的重复数据问题。首先,通过初始化数据并设置起止时间来构建拉链表,然后在数据更新时,将新增和变更数据存储到对应日期分区,并更新旧记录的结束时间为前一天。通过全连接、条件选择和动态分区插入,实现了新旧数据的有效管理和同步。
1.为什么要制作拉链表
数据量大,且数据的变化不大,若按全量同步策略则会每天存很多重复的数据。
因此需要制作拉链表来解决
2.如何制作拉链表
01
| id | name |
|---|---|
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
第一天
02 先把初始化数据,加上初始时间和结束时间(无限大),第一天的数据存储在hdfs的 9999-99-99分区
| id | name | start-day | end-day |
|---|---|---|---|
| 1 | 张三 | 2021-01-01 | 9999-99-99 |
| 2 | 李四 | 2021-01-01 | 9999-99-99 |
| 3 | 王五 | 2021-01-01 | 9999-99-99 |
第二天(即有新增 还有变化的内容)
| id | name | start-day | end-day |
|---|---|---|---|
| 3 | 王小五 | 2021-01-02 | 9999-99-99 |
| 4 | 小刘 | 2021-01-02 | 9999-99-99 |
| 5 | 王强 | 2021-01-02 | 9999-99-99 |
那么我们如何把新增数据存储到hdfs 9999-99-99分区,并且把过期的数据存储在 2021-01-01 分区呢。也就是下面这条数据
| 1 | 张三 | 2021-01-01 | 2021-01-01 |
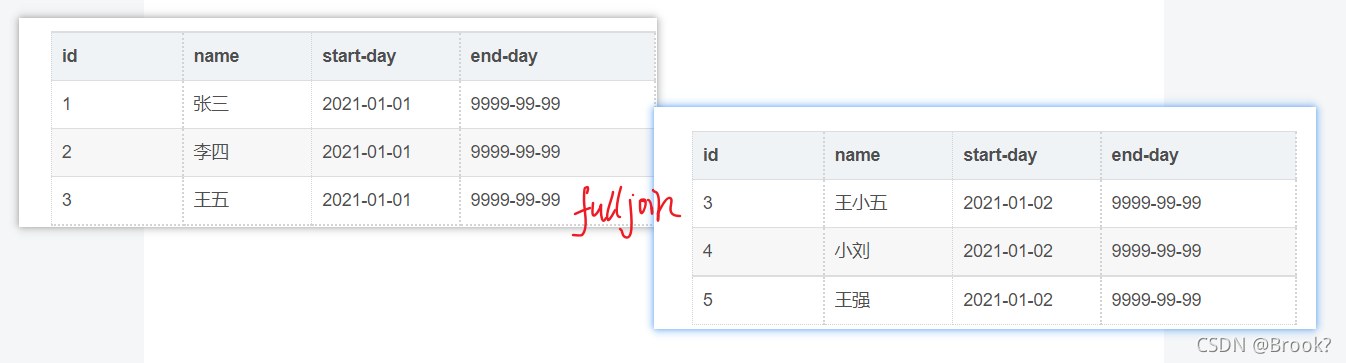
old_name,old_start_day ,old_end_day new_name,new_start_day ,new_end_day 03
——1
把 9999-99-99 分区里的数据 full join上 新增及变化的数据连接键为 id。从full join 的表里拿 8列 。
——2 前4列是 新的内容,从t2表(新增及变化)里面拿,若t2 表这个字段未null值,则从第一个表里拿。
——3 后4列是 旧的内容(过期的内容),若join上的 两边字段都不为null,则 从t1 表里面拿旧的数据,并且把结束时间 修改成 当天的 前一天
——4 查到新的数据,unoin上,查到旧的数据,按照动态分区插入到不同的分区
with tmp as
(select
nvl(t2.id,t1.id) new_id,
nvl(t2.name,t1.name) new_name,
nvl(t2.start_day,t1.start_day) new_start_day,
nvl(t2.end_day,t1.end_day) new_end_day,
if(t1.id is not null and t2.id is not null,t1.id,null) old_id,
if(t1.id is not null and t2.id is not null,t1.name,null) old_name,
if(t1.id is not null and t2.id is not null,t1.start_day,null) old_start_day,
if(t1.id is not null and t2.id is not null,case(date_add(taday,-1) as String),null) old_end_day
from t1
full join t2 on t1.id=t2.id
)t3
insert overwrite into table *** partition(dt)
select
new_id,
new_name,
new_end_day,
new_end_day dt
from tmp
union all
(
select
end_id,
end_name,
end_end_day,
end_end_day dt
from tmp
where old_name is not null
)
















 521
521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









