







实战项目的三个任务:
1.使用随机森林算法完成基本建模:包括数据预处理,特征展示,完成建模并进行可视化展示分析。
2.分析数据样本量与特征个数对结果的影响,在保证算法一致的前提下,增加样本个数,观察结果变化,重新进行特征工程,引入新的特征后,观察结果走势。
3.对随机森林算法进行调参,找到最合适的参数,掌握机器学习中两种调参方法,找到模型最优参数。
任务1:
import pandas as pd
data =pd.read_csv()
data.head()
import datetime
year = data['year']
month =data['month']
day =data['day']
dates = [(str(year)+'-'+str(month)+'-'+str(day)) for year,month,day in zip(year,month,day)]
dates=[datetime.datetime.strptime(date,'%Y-%m-%d') for date in dates]
dates[:5]对时间序列进行重新调整,进行特征绘制。
##进行绘图
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('fivethirtyeight')##风格设置
# 设置布局
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize = (10,10))
fig.autofmt_xdate(rotation = 45)
# 标签值
ax1.plot(dates, data['actual'])
ax1.set_xlabel(''); ax1.set_ylabel('Temperature'); ax1.set_title('Max Temp')
# 昨天
ax2.plot(dates, data['temp_1'])
ax2.set_xlabel(''); ax2.set_ylabel('Temperature'); ax2.set_title('Previous Max Temp')
# 前天
ax3.plot(dates, data['temp_2'])
ax3.set_xlabel('Date'); ax3.set_ylabel('Temperature'); ax3.set_title('Two Days Prior Max Temp')
# 我的逗逼朋友
ax4.plot(dates, data['friend'])
ax4.set_xlabel('Date'); ax4.set_ylabel('Temperature'); ax4.set_title('Friend Estimate')
plt.tight_layout(pad=2)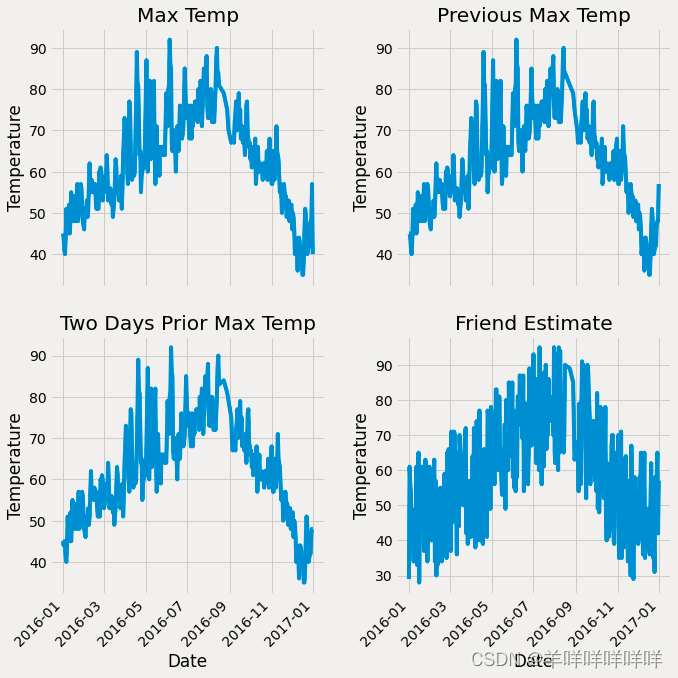
从中可以看出4个特征的基本影响走势。
import numpy as np
y = np.array(data['actual'])
x = data.drop(['actual'],axis=1)
x_list =list(x.columns)
x = np.array(x)
##数据分类
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test =train_test_split(x,y,test_size=0.25,random_state=42)
##建立随机森林模型
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor(n_estimators=1000,random_state=42)
rfr.fit(x_train,y_train)
y_pred = rfr.predict(x_test)
from sklearn.metrics import mean_squared_error
mse=mean_squared_error(y_test,y_pred)
print('mse',mse)这里进行了测试集与训练集的分割与随机森林模型的建立。通过建立的模型预测了结果与真实值计算量mse的值。
随后进行了决策树树的可视化
from sklearn.tree import export_graphviz
import pydot
tree = rfr.estimators_[5]
ex 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









