







题目:
给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址? 与上题条件相同, 如何找到top K的IP?
1.找出出现次数最多的IP地址
最易想到的方法就是去遍历这个文件:使用嵌套的循环去统计每个IP地址出现的次数,最终找出出现次数最多的。
这种方法可行,但有很大缺陷:
首先100G的文件不可能一次性加载到内存,因此就需要对文件进行分割,而统计每一个IP地址的数量时,都需要将整个文件都进行一次遍历,由此就会引发多次的IO操作,效率是及其低下的。
这里我们应该使用哈希的思想:
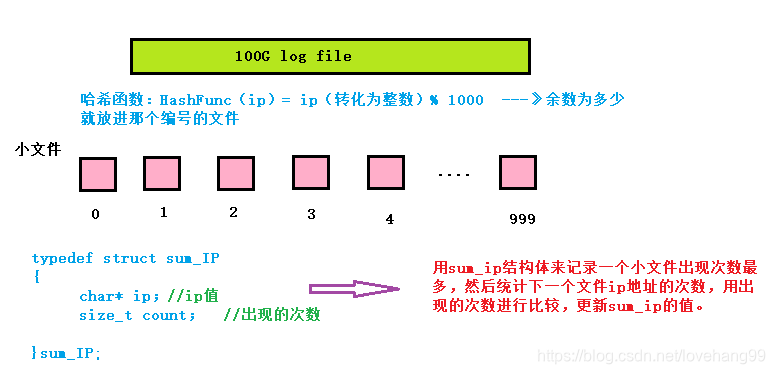
我们可以给出n个文件(n的取值结合内存的大小),编号由0 – n-1,将IP地址转化为十进制的整数,利用哈希函数(采用直接定址法)将不同的ip地址存放到对应编号的文件中去,那么最后相同的ip地址就会存放在同一个文件中,一次遍历每一个文件,统计出每个ip地址的次数,这样就可以找到出现次数最多的ip地址。
2.TOP k问题
关于topK,我们想到的解决方式就是建立一个堆,要找到前K个次数最多的ip地址我们就建立一个有K个元素的小堆,找前K个出现次数最少的我们就建立一个大堆,这里我们建的是小堆。第一问中,我们已经求得了每个ip地址出现得次数,我们只需要将IP地址和它出现的次数封装成一个键值对,以键值对中IP地址出现的次数作为关键码,先向堆中插入K个元素,以后再插入元素时,以后再插入元素时,先与堆顶元素进行比较,如果小于堆顶元素,不做处理,如果大于,则将堆顶元素删除,将此元素重新插入堆中,当遍历完所有IP地址后,堆中保存最多的元素就是出现次数最多的K个。

















09-10
 254
254
254
12-31
1665
1665
06-03
2449
2449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









