









 本文讲述了项目组在处理物联网设备监测大屏项目时,由于缓存策略设计不当,导致服务器CPU满载并引发生产事故。经过分析,问题出在缓存失效时间设置不合理,大量请求直接穿透缓存,压垮服务器。改进措施包括增加缓存降级策略、任务代码解耦和设置永不失效的缓存时间。事故提醒我们,技术方案设计需全面考虑,注重系统容错和解耦。
本文讲述了项目组在处理物联网设备监测大屏项目时,由于缓存策略设计不当,导致服务器CPU满载并引发生产事故。经过分析,问题出在缓存失效时间设置不合理,大量请求直接穿透缓存,压垮服务器。改进措施包括增加缓存降级策略、任务代码解耦和设置永不失效的缓存时间。事故提醒我们,技术方案设计需全面考虑,注重系统容错和解耦。
菠菜最近在整理一些技术文档的时候,偶然发现项目组之前的一次真实线上事故,往事历历在目,值得深思。现刚加入星球,发出来和各位球友分享。
背景:去年我所在的项目研发组接到一个项目,其中有一个需求业务类似于物联设备监测大屏,物联监控设备数据量比较大。和产品沟通了一下,设备数量以及调用链路很长,该页面数据对实时性要求不是很高,当时就想着可以做一层数据缓存来应对较大数据级的查询以及统计。
过程:因为项目比较着急,作为项目研发组长的菠菜,快速做了一个技术方案以及任务拆解,安排组员投入研发。下面是还原的一个大致方案图,球友也可以思考一下,这样会有什么问题。
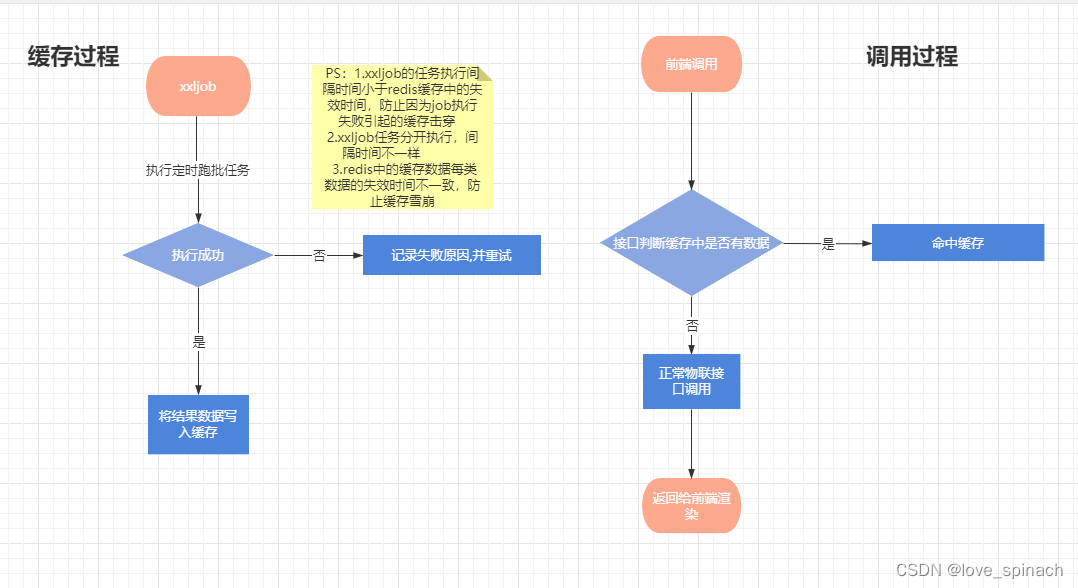
应用开发以及测试正常进行,上线那天晚上,应用服务一上线,服务器cpu全部拉满,不出一个小时,服务实例节点全都挂掉了,发生了生产事故。公司的质量安全团队立马拉群,将故障上报到我的leader那边,应用紧急下线,连夜抓紧重新调整方案。熬夜带着小伙伴们肝代码,重新修复上线,服务恢复正常。
分析:当晚服务紧急下线后,通过grafana查看应用实例节点的信息,发现服务器的cpu一直是满的,开始查看应用业务日志分析原因。查看xxljob任务调度,发现每个跑批任务的执行时间都很长,并且超过缓存结果数据的失效时间,导致缓存数据失效,所有的请求都走接口调用。因为在测试的时候没考虑到这么大数据量,实时iot接口调用链路长,且一次请求数据量较大,导致服务器资源一直被占满,定时任务抢占不到资源,又不断有新的请求进来,不断恶行循环,服务器最终拉崩,造成生产事故。
改进:分析找到原因后,立马对之前的方案做了改进。如下图:
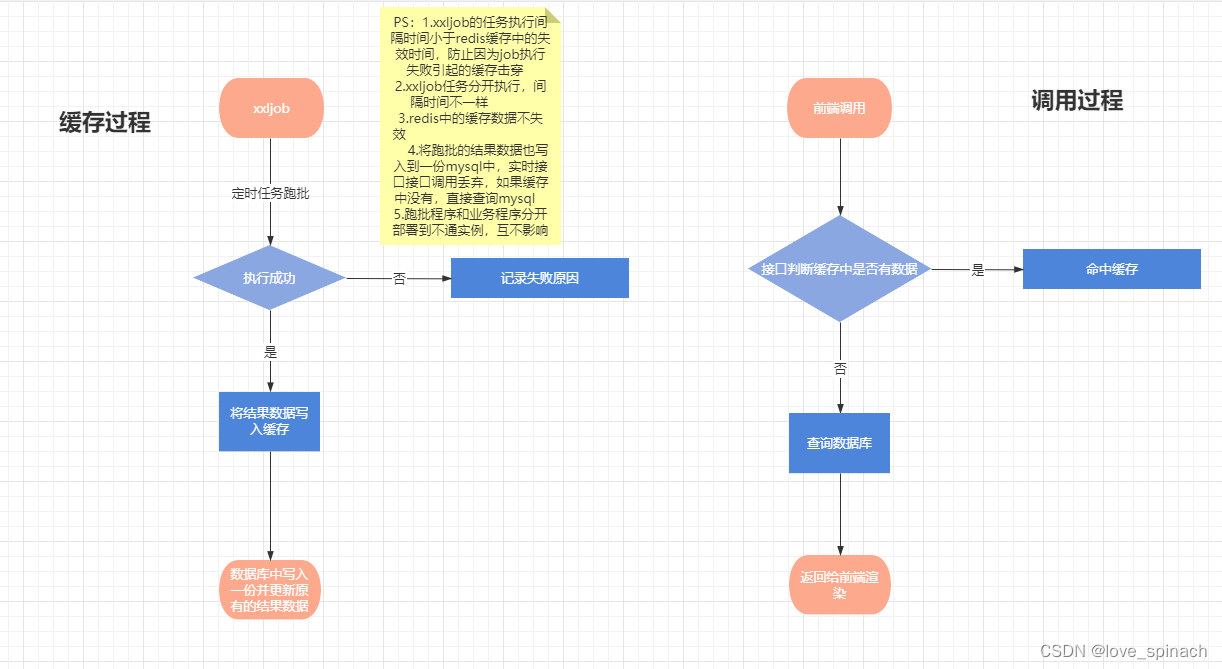
1.增加缓存失效降级方案,由原来的iot实时调用改为直接查询mysql数据库
2.xxljob定时任务程序代码和业务程序代码拆开,解耦,互不影响,也变相增加服务器的规格
3.缓存失效时间设为永不失效
结果:所以的结果就是,大家加班连夜修复代码,测试并上线,解决这个问题。还好这个问题我们响应比较快,并且没有交付给客户,事故没有造成太大的影响面。当然,菠菜肯定是挨批了,好在和领导关系比较好,但是作为一个有经验的开发,犯这样的错是不应该的。要是toC的业务,发生这样的事故,裁掉你算轻的了。
浅谈:其实后面认真复盘了一下,造成此次的问题,还是因为技术方案设计的有问题。你在设计的时候考虑问题是否全面,系统是否有容错机制?业务服务是否解耦?这些都要我们好好去思考。看见有些球友抱怨一直在写一些基础的CURD,自己没有成长什么的。其实不然,你写的每个接口你有没有重新去review自己写的代码,去做接口调优。如果你能深挖其中的细节,你又会学习到很多东西。可以学习一些新的技术,无可厚非,因为技术迭代太快了。但是也不能盲目去追求新的技术,例如你使用了某些中间件,你有没有想过它的优缺点以及它带来的一些问题,这些都是我们要去考虑的。
有道云原文链接地址:浅谈一起线上事故,大家如果觉得有所收获,帮忙点个赞~
菠菜分享自己地亲身经历,和大家一起交流,一起加油,感谢~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









