







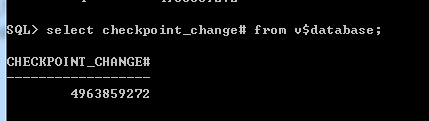
1、系统检查点(记录在控制文件中)
SQL> select checkpoint_change# from v$database;
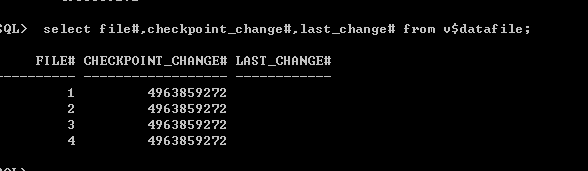
2、数据文件检查点(记录在控制文件中)
SQL> select file#,checkpoint_change#,last_change# from v$datafile;
3、数据文件头检查点(记录在数据文件中)
SQL> select file#,checkpoint_change# from v$datafile_header;

正常关库时,会生成新的检查点,写入上述三个checkpoint_change#,同时控制文件中的last_change#也会记录下该检查点,也就是说三个checkpoint_change#与last_change#记录着同一个值。 数据库成功打开后,控制文件中的last_change#会被清空。下一次正常关库时,再重新生成新的检查点。abort关库,last_change#是空的或者认为是无穷大,此时数据库需要进行实例恢复,恢复后数据库才正常打开。 需要注意日志文件里也有个这样的SCN,出现在v$log表的FIRST_CHANGE#列和V$DATAFILE的CHECKPOINT_CHANGE#列还有V$DATABASE的CHECKPOINT_CHANGE#上。 只要说明三个值相同,那么数据库就没有不同步的现象。否则就要进行介质恢复.
备注:
v$datafile是从oracle的控制文件中获得的数据文件的信息
v$datafile_header是从数据文件的头部获得的数据文件的信息
在正常运行下,两者的检查点SCN值是一致的,但当datafile出现损坏时可以用v$datafile_header确定应用重做的起始SCN,而v$datafile可确定应用重做的结束SCN值
sql> select a.name,a.checkpoint_change# “start_SCN”,
> b.checkpoint_change# “last_SCN”
> from v$datafile_header a, v$datafile b
> where a.file#=b.file#;

















 2742
2742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









