




 博客分享了提高GPU训练效率的两种方法。一是利用NVIDIA DALI模块加速数据预处理,通过并行处理减少训练延迟。二是升级PyTorch到1.7以上版本,利用新增的`prefetch_factor`参数,预先加载更多批次的数据,显著缩短数据读取时间,提高显卡利用率。作者实测将加载时间从3s降至0.5s,效果明显。
博客分享了提高GPU训练效率的两种方法。一是利用NVIDIA DALI模块加速数据预处理,通过并行处理减少训练延迟。二是升级PyTorch到1.7以上版本,利用新增的`prefetch_factor`参数,预先加载更多批次的数据,显著缩短数据读取时间,提高显卡利用率。作者实测将加载时间从3s降至0.5s,效果明显。
最近使用四卡训练图片,发现总有卡的效率突变到0,大致就是在读取以及处理数据了
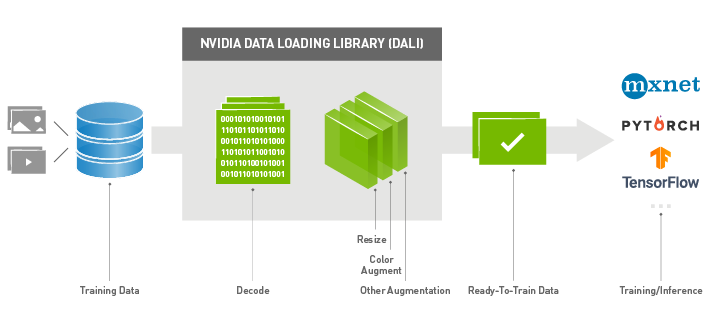
怎么能加速读取呢?一个方法是用NVIDIA的DALI模块,可以加速,具体可以参考 英伟达DALI加速技巧:让数据预处理速度比原生PyTorch快4倍
主要就是通过并行训练和预处理过程,减少了延迟及训练时间
但是今天我发现一个更简单的方法
就是升级pytorch到1.7以上,目前是1.8.1,最好的1.8.1吧
为什么会这么说呢,因为在dataloader中加入了一个参数 prefetch_factor,这个就是提前加载多少个batch的数据,具体更改看github ,具体说如下,现在默认prefetch_factor =2 ,就是意味着预先加载 prefetch 2 * num_workers 个data
fix #40604
Add parameter to Dataloader to configure the per-worker prefetch number.
Before this edit, the prefetch process always prefetch 2 * num_workers data items, this commit help us make this configurable, e.x. you can specify to prefetch 10 * num_workers data items
我在我这里试了一下,升级以后,有从3s到0.5s,速度还是很明显的,而且显卡利用率都上来了。大家可以自己试试~


















 819
819




 到【灌水乐园】发言
到【灌水乐园】发言







