




 本文分享了一个Python爬虫程序,用于抓取豆瓣电影正在热播的电影信息,包括电影标题、导演、时长、国家和评分等,并展示了如何使用requests和BeautifulSoup进行网页请求和解析,同时保存了电影详情页的HTML和电影海报。
本文分享了一个Python爬虫程序,用于抓取豆瓣电影正在热播的电影信息,包括电影标题、导演、时长、国家和评分等,并展示了如何使用requests和BeautifulSoup进行网页请求和解析,同时保存了电影详情页的HTML和电影海报。
个人的第一个python爬虫程序,如果错误,请指正。
程序用于抓取豆瓣电影正在热播的电影信息,详细代码如下所示:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os,requests
from bs4 import BeautifulSoup
def get_url_page(url,headers):
try:
response = requests.get(url,headers = headers)
if response.status_code == 200:
return response.text
else:
raise Exception('获取页面信息异常,response_stauts = %s '%response.status_code)
except RequestException:
return None
if __name__ == '__main__':
print('采集豆瓣电影信息')
##获取页面信息
url = 'https://movie.douban.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0'}
page_content = get_url_page(url,headers)
##切换路径
folder_path,file_name = os.path.split(os.path.realpath(__file__))
os.chdir(folder_path)
##存储网页html
html_file = os.path.splitext(file_name)[0] + '.html'
file = open(html_file,'w+',encoding='utf-8')
file.truncate()
file.write(page_content)
file.close()
##使用beautifulsoup解析
soup = BeautifulSoup(open(html_file,encoding='utf-8'),features='html.parser')
##soup = BeautifulSoup(page_content,'lxml')
for i,row in enumerate(soup.body.findAll('div',attrs = {"id":"screening"})):
movies_dict = {}
for j,col in enumerate(row.findAll('li',attrs = {"class":"ui-slide-item"})):
if 'data-director' in col.attrs:
##返回上级目录
os.chdir(folder_path)
movies_path = os.path.join(folder_path,col.ul.li.a.img['alt'])
if not os.path.isdir(movies_path):
os.mkdir(movies_path)
##进入电影目录,下载电影图片
os.chdir(movies_path)
movie_name = col.ul.li.a.img['alt']
img_link = col.ul.li.a.img['src']
img = requests.get(img_link)
if img.status_code == 200:
open('1.jpg', 'wb').write(img.content) # 写入文件
else:
print('图片不存在')
#写入电影信息
fo = open(movie_name + '.txt','w',encoding='utf-8')
fo.truncate()
fo.writelines('电影标题:' + col['data-title'] + '\n')
fo.writelines('导演:' + col['data-director'] + '\n')
fo.writelines('时长:' + col['data-duration'] + '\n')
fo.writelines('国家:' + col['data-region'] + '\n')
fo.writelines('评分:' + col['data-rate'] + '\n')
fo.close()
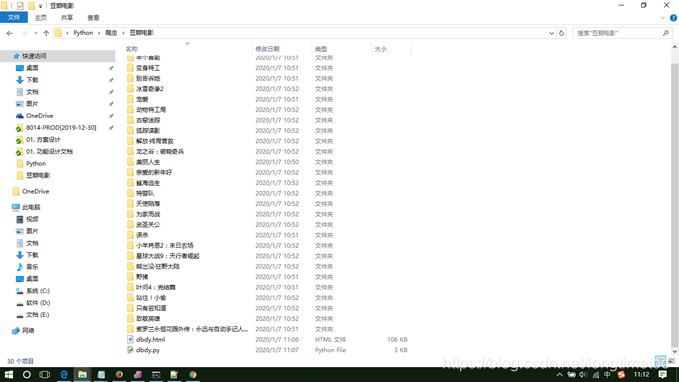
代码运行效果如下所示:

















 1328
1328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









