



 本文介绍如何利用sklearn的make_blobs函数生成用于聚类的数据集,并使用matplotlib进行可视化展示。通过调整参数如样本数量、特征数、类别数等,可以灵活地创建适合不同场景的数据集。
本文介绍如何利用sklearn的make_blobs函数生成用于聚类的数据集,并使用matplotlib进行可视化展示。通过调整参数如样本数量、特征数、类别数等,可以灵活地创建适合不同场景的数据集。
eg.
from sklearn.datasets import make_blobs
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
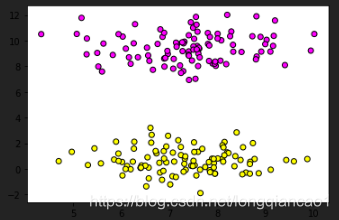
data = make_blobs(n_samples=200, centers=2, random_state=8)
X, y = data #将data赋值给X, y
plt.scatter(X[:,0], X[:,1], c=y, cmap=plt.cm.spring, edgecolor='k')
plt.show()
--------------------------------------------
make_blobs()
make_blobs()函数用于生成一个样本数量, 为聚类产生数据集。
sklearn.datasets.make_blobs(n_samples, n_features, centers, cluster_std, center_box, shuffle, random_state)
- n_samples:待生成的样本的总数。
- n_features:每个样本的特征数,默认值是2。
- centers:类别数,默认值3。
- cluster_std:数据集的标准差,浮点数或者浮点数序列,默认值1.0。
- center_box:中心确定之后的数据边界,默认值(-10.0, 10.0)
- shuffle :洗乱,默认值是True
- random_state:官网解释是随机生成器的种子
plt.scatter()
plt.scatter()用于绘制散点图
函数的原型:
matplotlib.pyplot.scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=None, linewidths=None, verts=None, edgecolors=None, *, data=None, **kwargs)
- x,y:数组,散点图的数据点
- c: color
- marker: 标记的样式
- cmap: Colormap实体或者是一个colormap的名字,cmap仅仅当c是一个浮点数数组的时候才使用。如果没有申明就是image.cmap
- norm: Normalize实体来将数据亮度转化到0-1之间,也是只有c是一个浮点数的数组的时候才使用。如果没有申明,就是默认为colors.Normalize。
在感知机模型中,其中有一条语句如下,x,y后面跟随一个属性,则表示只对该属性进行切片。(其中'sepal length' 是df的一个属性)
plt.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0') #前50个数据
#df[:50]['sepal length'],只对'sepal length'这个标量进行切分

















 399
399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









