







《性能之巅:洞悉系统、企业与云计算》第一章(绪论)和第二章(方法)的笔记,请参考Part 1,第三章(操作系统)的笔记,请参考Part 2,第四章(观测工具)的笔记,请参考Part 3,第五章(应用程序)的笔记,请参考Part 4,本文是第六章——CPU。
当需求的CPU资源超过系统力所能及的范围时,进程里的线程(或任务)将会排队,等待轮候自己运行的机会。等待给应用程序的运行带来严重延时,使得性能下降。
从上层来说,可按进程、线程或任务来检查CPU用量。从下层来看,可剖析并研究应用程序和内核里的代码路径。在底层,可研究CPU指令的执行和周期行为。
术语
CPU相关术语如下:
- 处理器:插到系统插槽或处理器板上的物理芯片,以核或硬件线程的方式包含一块或多块CPU;
- 核:一颗多核处理器上的一个独立CPU实例。核的使用是处理器扩展的一种方式,又称为芯片级多处理(chip-level multiprocessing,CMP);
- 硬件线程:一种支持在一个核上同时执行多个线程(包括Intel超线程技术)的CPU架构,每个线程是一个独立的CPU实例。这种扩展的方法又称为多线程;
- CPU指令:单个CPU操作,来源于它的指令集。指令用于算术操作、内存I/O,以及逻辑控制;
- 逻辑CPU:又称为虚拟处理器,一个操作系统CPU的实例(一个可调度的CPU实体)。处理器可通过硬件线程(虚拟核)、一个核,或一个单核的处理器实现;
- 调度器:把CPU分配给线程运行的内核子系统;
- 运行队列:一个等待CPU服务的可运行线程队列。Solaris上常被称为分发器队列;
模型
CPU架构
单个处理器内共有四个核和八个硬件线程。
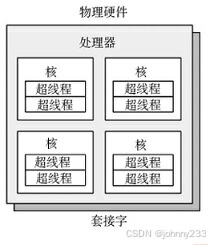
每个硬件线程都可以按逻辑CPU寻址,因此这个处理器看上去有八块CPU。对这种拓扑结构,操作系统可能有一些额外信息,如哪些CPU在同一个核上,可提高调度的质量。
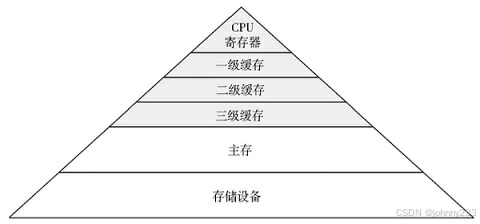
CPU内存缓存
越小则速度越快,并且越靠近CPU。
CPU运行队列
概念
时钟频率
时钟是一个驱动所有处理器逻辑的数字信号。每个CPU指令都可能会花费一或多个时钟周期(CPU周期)。有些处理器可改变时钟频率,升频以改进性能或降频以减少能耗。
更快的时钟频率并不一定会提高性能。
指令
一个指令包括以下步骤,每个都由CPU的一个叫作功能单元的组件处理:
- 指令预取
- 指令解码
- 执行
- 内存访问
- 寄存器写回
最后两步是可选的,取决于指令本身。许多指令仅仅操作寄存器,并不需要访问内存。这里每一步都至少需要一个时钟周期来执行。内存访问经常是最慢的,因为它通常需要几十个时钟周期读或写主存,在此期间指令执行陷入停滞(停滞期间的这些周期称为停滞周期)。这就是CPU缓存如此重要的原因:它可以极大地降低内存访问需要的周期数。
指令流水线
指令流水线是一种CPU架构,通过同时执行不同指令的不同部分,来达到同时执行多个指令的结果。
指令宽度
同一种类型的功能单元可以有好几个,这样每个时钟周期里就可以处理更多的指令。这种CPU架构被称为超标量,通常和流水线一起使用以达到高指令吞吐量。
指令宽度描述了同时处理的目标指令数量。现代处理器宽度一般为3或4,意味着它们可以在每个周期里最多完成3~4个指令。如何取得这个结果取决于处理器本身,每个环节都有不同数量的功能单元处理指令。
CPI,IPC
CPI:cycles per instruction,每指令周期数,描述CPU如何使用它的时钟周期,也可用来理解CPU使用率本质。
IPC:instructions per cycle,每周期指令数,CPI的倒数。
CPI较高代表CPU经常陷入停滞,通常都是在访问内存。CPI较低则代表CPU基本没有停滞,指令吞吐量较高。
内存访问密集的负载,提高性能的方法,如使用更快的内存(DRAM)、提高内存本地性(软件配置)、减少内存I/O数量。使用更高时钟频率的CPU并不能达到预期的性能目标,因为CPU还是需要为等待内存I/O完成而花费同样的时间。换句话说,更快的CPU意味着更多的停滞周期,而指令完成速率不变。
CPI的高低与否实际上和处理器以及处理器功能有关,可通过实验方法运行已知的负载得出。例如,你会发现高CPI的负载可以使CPI达到10或更高,而在低CPI的负载下,CPI低于1(受益于前述的指令流水线和宽度技术,这是可以达到的)。
CPI代表指令处理的效率,但并不代表指令本身的效率。假设有一个软件改动,加入一个低效率的循环,这个循环主要在操作CPU寄存器(没有停滞周期):这种改动可能会降低总体CPI,但会提高CPU的使用和利用度。
使用率
CPU使用率通过测量一段时间内CPU实例忙于执行工作的时间比例获得,以百分比表示。它也可以通过测量CPU未运行内核空闲线程的时间得出,这段时间内CPU可能在运行一些用户态应用程序线程,或其他的内核线程,或在处理中断。
高CPU使用率并不一定代表着问题,仅仅表示系统正在工作。有些人认为这是ROI的指示器:高度利用的系统被认为有着较好的ROI,而空闲的系统则是浪费。和其他类型的资源(磁盘)不同,在高使用率的情况下,性能并不会出现显著下降,因为内核支持优先级、抢占和分时共享。这些概念加起来让内核决定了什么线程的优先级更高,并保证它优先运行。
CPU使用率的测量包括了所有符合条件活动的时钟周期,包括内存停滞周期。虽然看上去有些违反直觉,但CPU有可能像前面描述的那样,会因为经常停滞等待I/O而导致高使用率,而不仅是在执行指令。
CPU使用率通常被分成内核时间和用户时间两个指标。
用户时间/内核时间
CPU花在执行用户态应用程序代码的时间称为用户时间,而执行内核态代码的时间称为内核时间。内核时间包括系统调用、内核线程和中断的时间。当在整个系统范围内进行测量时,用户时间和内核时间之比可揭示运行的负载类型。
计算密集型应用会把大量时间用在用户态代码上,用户/内核时间之比接近99/1。如:图像处理、基因组学和数据分析。
I/O密集型应用的系统调用频率较高,通过执行内核代码进行I/O操作。例如,一个进行网络I/O的Web服务器的用户/内核时间比大约为70/30。
饱和度
CPU饱和:100%使用率的CPU,线程在这种情况下会碰上调度器延时,需要等待才能在CPU上运行,降低总体性能。这个延时是线程花在等待CPU运行队列或其他管理线程的数据结构上的时间。
另一个CPU饱和度的形式则和CPU资源控制有关,这个控制会在云计算环境下发生。尽管CPU并没有100%地被使用,但已经达到控制的上限,因此可运行的线程就必须等待轮到它们的机会。这个过程对用户的可见度取决于使用的虚拟化技术。
一个饱和运行的CPU不像其他类型资源那样问题重重,因为更高优先级的工作可以抢占当前线程。
抢占
抢占允许更高优先级的线程抢占当前正在运行的线程,并开始执行。节省更高优先级工作的运行队列延时时间,提高性能。
优先级反转
优先级反转指的是一个低优先级线程拥有一项资源,从而阻塞高优先级线程运行的情况。高优先级工作被迫阻塞等待,性能降低。
Solaris内核实现了一套完整的优先级继承机制,以避免优先级反转。
Linux 2.6.18提供一个支持优先级继承的用户态mutex,用于实时负载。
多进程,多线程
大多数处理器都以某种形式提供多个CPU。对于想使用这个功能
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











