







 本文详细解读了Vue实例的完整生命周期,包括beforeCreate、created、beforeMount、mounted、beforeUpdate和updated等关键阶段,以及它们在实例创建过程中的作用和应用场景。
本文详细解读了Vue实例的完整生命周期,包括beforeCreate、created、beforeMount、mounted、beforeUpdate和updated等关键阶段,以及它们在实例创建过程中的作用和应用场景。
什么是生命周期
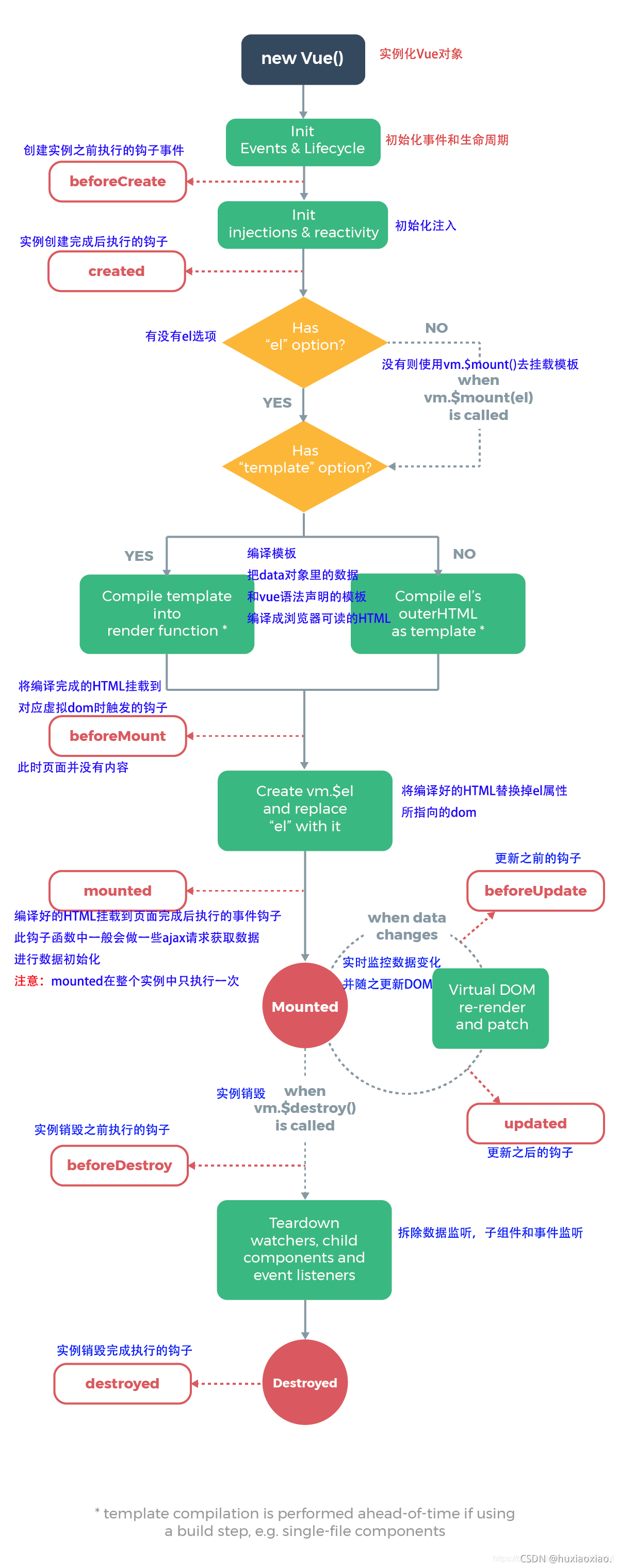
Vue 实例有一个完整的生命周期,也就是从开始创建、初始化数据、编译模板、挂载 Dom、渲染 → 更新 → 渲染、卸载等一系列过程,我们称这是 Vue 的生命周期。通俗说就是 Vue 实例从创建到销毁的过程,就是生命周期。
在 Vue 的整个生命周期中,它提供了一系列的事件,可以让我们在事件触发时注册 js 方法,可以让我们用自己注册的 js 方法控制整个大局,在这些事件响应方法中的 this 直接指向的是 vue 的实例。
vue 的生命周期
生命周期函数,又叫钩子函数(生命周期钩子===生命周期函数===生命周期事件)
vue 中的生命周期函数,一般都是 成对出现。所以我们成对比较一下,他们的区别。
10 个生命周期函数 牢记!具体使用!
生命周期钩子函数
特点:自动调用的,只是他们的调用的时间节点 有 先 有 后。
在官网上拿了张图:
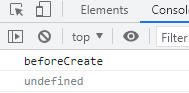
beforeCreate --- vue实例"创建前" ,注意:在这个函数中,vue中data数据中心的数据,它是读不到的。
<script src="./js/vue.js"></script>
<script>
let vm = new Vue({
el:'#app',
data:{
name:"哈哈哈",
num:1111
},
methods: {
},
// vue实例创建之前
beforeCreate(){
console.log('beforeCreate');
console.log(this.name);
}
</script>输出数据中心的 name 是读不到的:
created --- vue实例"创建后",注意:在这个函数中,可以识别 到 vue中data数据中心的数据
<script src="./js/vue.js"></script>
<script>
let vm = new Vue({
el:'#app',
data:{
name:"哈哈哈",
num:1111
},
// vue实例创建之后
created(){
console.log("created");
console.log(this.name);
}
})
</script>查看结果:
![]()
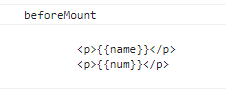
beforeMount --- DOM挂载之前 this.$el---此时的$el为“虚拟的”DOM节点
在视图层渲染标签:
<div id="app">
<p>{{name}}</p>
<p>{{num}}</p>
</div><script src="./js/vue.js"></script>
<script>
let vm = new Vue({
el:'#app',
data:{
name:"哈哈哈",
num:1111
},
// dom挂载之前
beforeMount(){
console.log("beforeMount");
//查看dom元素
console.log(document.body.querySelector("#app").innerHTML);
}
})
</script>dom挂载前输出结果:
mounted ---DOM挂载之后 this.$el---此时的$el为“真实的”DOM节点
<script src="./js/vue.js"></script>
<script>
let vm = new Vue({
el:'#app',
data:{
name:"哈哈哈",
num:1111
},
// dom挂载之后
mounted(){
console.log("mounted");
console.log(document.body.querySelector("#app").innerHTML);
}
})
</script>查看输出结果:
beforeUpdate --- 数据更新之前(----视图层中的数据的前后变化)
updated --- 数据更新之后(----视图层中的数据的前后变化)
在视图层通过 点击让 num 的数值发生改变来模拟数据更新,查看结果:
<div id="app">
<p id="num">{{num}}</p>
<button @click="num++">点击数据更新(num+1)</button>
</div>
// 数据更新前
beforeUpdate(){
console.log("beforeUpdate--数据更新前");
// 查看dom元素
console.log(document.body.querySelector("#num").innerHTML);
},
// 数据更新后
updated(){
console.log("updated--数据更新后");
// 查看dom元素
console.log(document.body.querySelector("#num").innerHTML);
}此时数据无变化时,在控制台是看不到效果的,当我们点击按钮后:
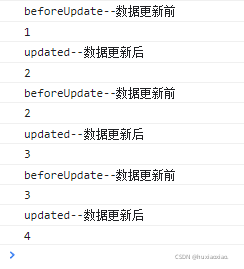

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









