






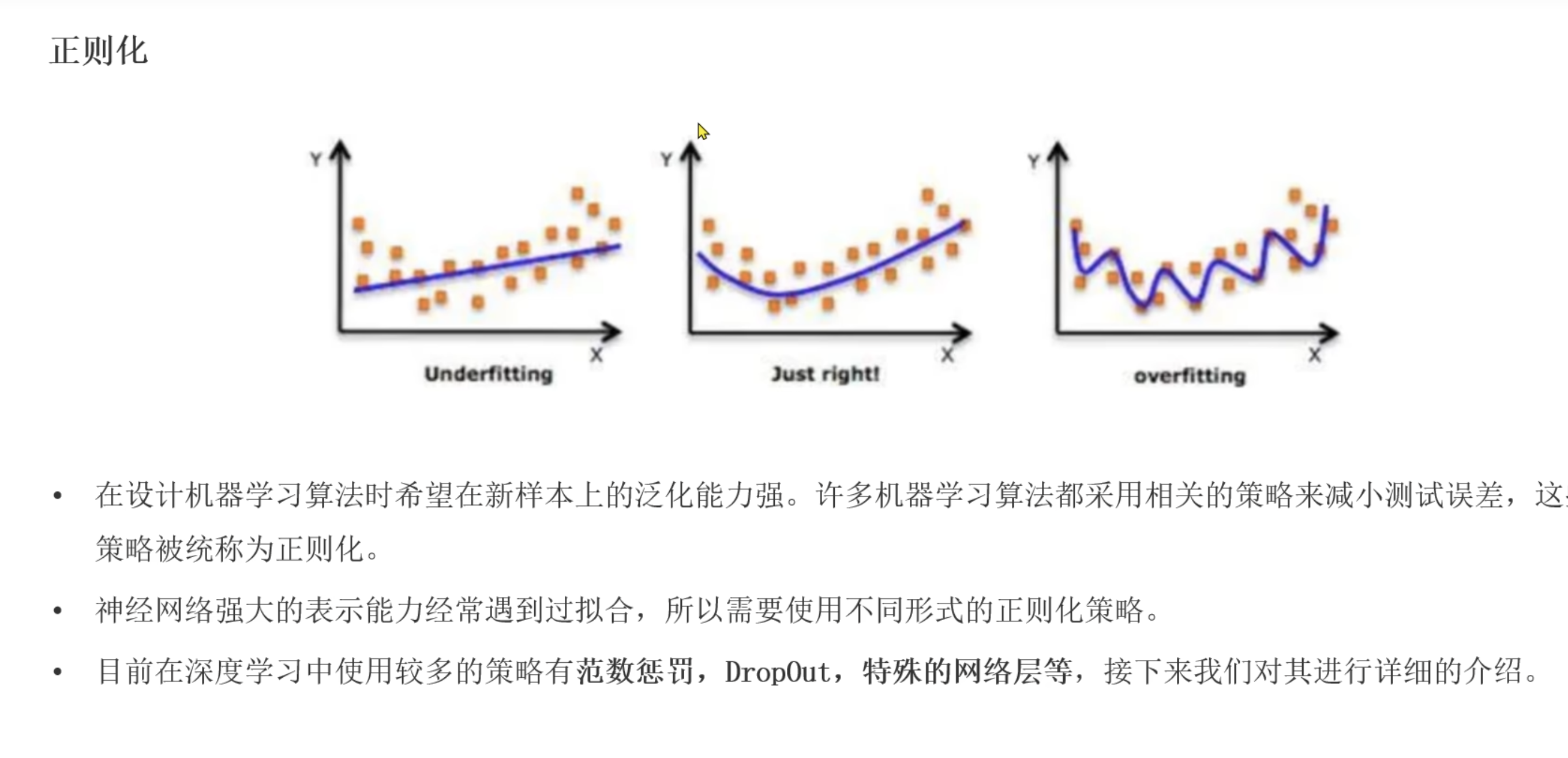
正则化(dropout随机失活)
- 解决模型的过拟合问题
Dropout正则化
- 模型参数较多,数据量不足的情况,容易过拟合。所以就使用Dropout正则化。
- 就是让神经元以一定p的概率失活。缩放比例为1/(1-p)
- 测试中随机失活不起作用
- 一批次训练都会随机概率p失活神经元
- 通常设置在0.2到0.5
- 一般都是放在激活函数之后(这个dropout层)
- 也就是会有一定概率,让激活后的值变为0(失活概率),还有一部分被放大(例如p为0.5 ,你们就是1/(1-0.5) = 2, 也就是方法两倍)缩放比例
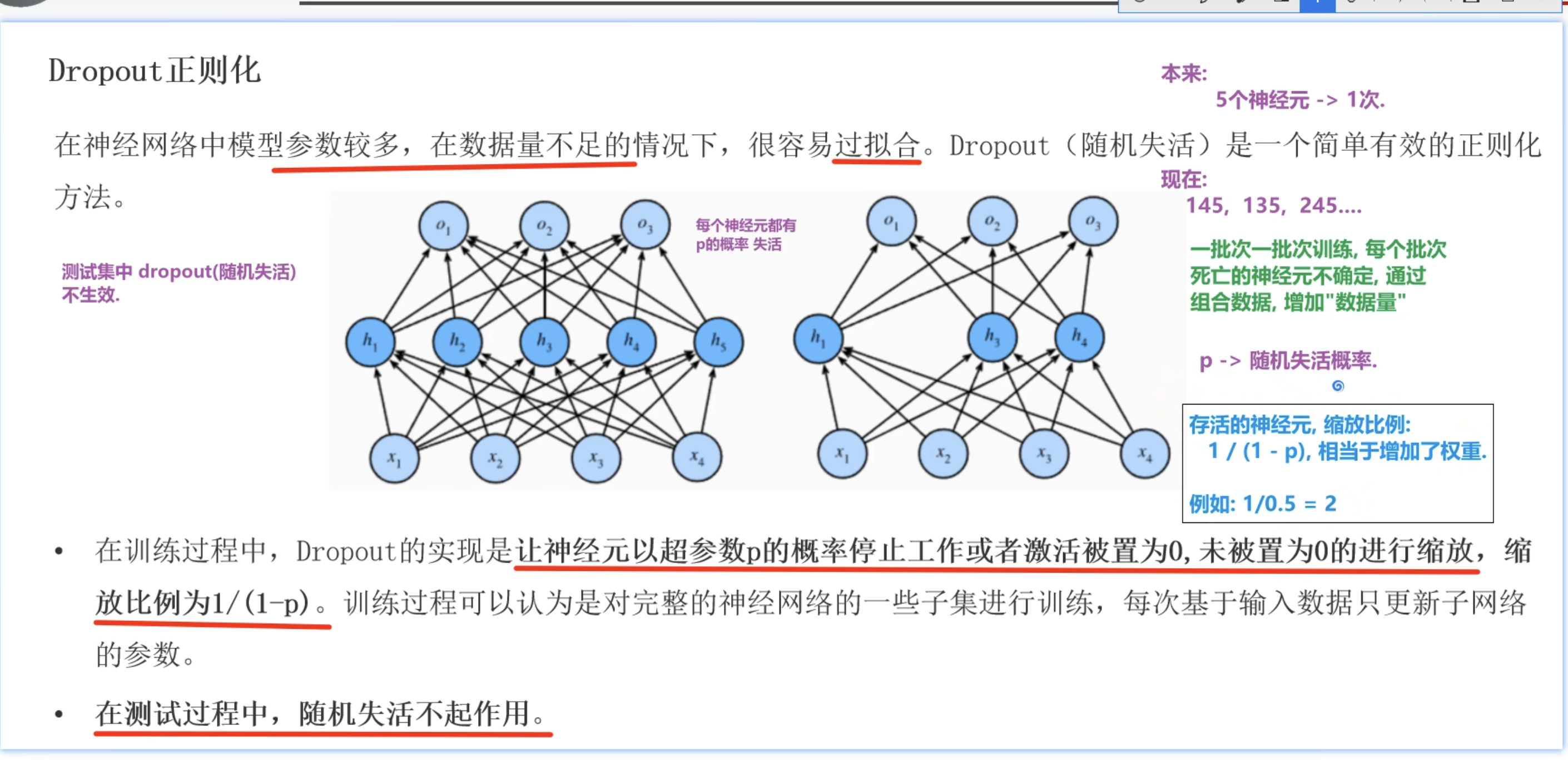

Dropout正则化的失活概率和缩放比例
- 首先要经过加权求和 + 激活函数
- 然后对这样的预测值进行失活和缩放了
- p = 0.5
- 失活比例为50%,说明有这个概率预测值被变为0了
- 缩放比例为1/(1-0.5) =2 ,也就是放大两倍
为什么正则化,Dropout随机失活,效果反而更好呢?
- 每个样本都被不同的子网络处理,相当于数据增强的效果。
过拟合的原因:
网络记住了训练数据的特定模式,而不是通用特征
Dropout的作用:
- 破坏共适应性:不让神经元依赖特定的伙伴
- 强制学习冗余特征:每个特征都要能独立起作用
- 模型平均:训练了多个子网络,测试时相当于它们的平均
数学示例:单一样本的"数据增强"
假设我们有1个训练样本,使用Dropout(p=0.5)训练3个epoch:
原始数据:x = 2.0
网络有3个神经元,权重:[0.5, -0.3, 0.8]
不同epoch的dropout效果:
Epoch 1:
激活模式: [1 0 1] # 神经元1和3激活
有效权重: [0.5 0. 0.8]
网络输出: 2.600
使用的子网络: 神经元[1 3]
Epoch 2:
激活模式: [0 1 1] # 神经元2和3激活
有效权重: [ 0. -0.3 0.8]
网络输出: 1.000
使用的子网络: 神经元[2 3]
Epoch 3:
激活模式: [1 1 0] # 神经元1和2激活
有效权重: [ 0.5 -0.3 0. ]
网络输出: 0.400
使用的子网络: 神经元[1 2]
关键理解:1个样本 ⇒ 多个"变体"
对同一个样本:
- Epoch 1:用
神经元1+3的子网络处理 - Epoch 2:用
神经元2+3的子网络处理 - Epoch 3:用
神经元1+2的子网络处理
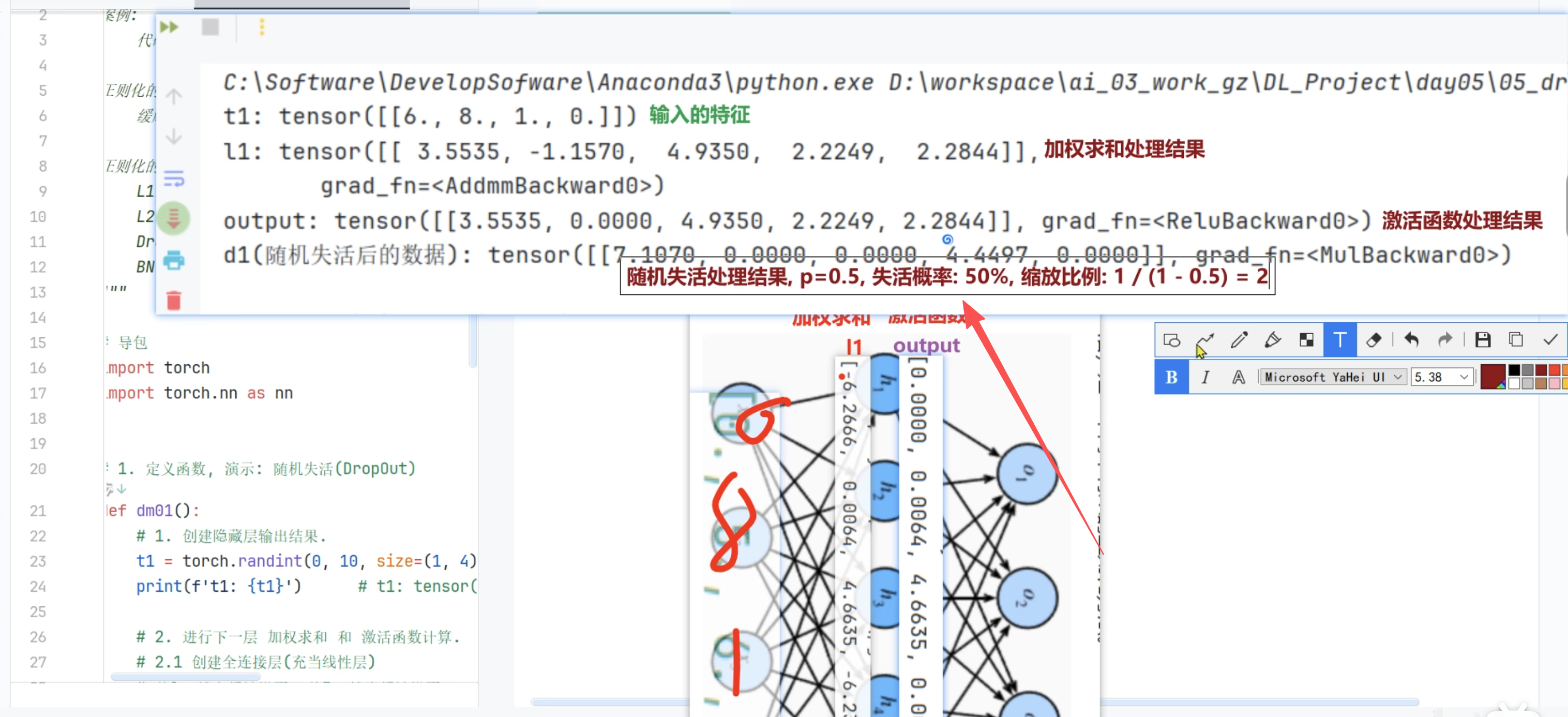
测试代码
import torch
import torch.nn as nn
def dm01():
x = torch.randint(0, 10, size=(1,4)).float()
print(f'x:{x}')
# 定义隐藏层
linear1 = nn.Linear(4, 5)
# 加权求和
l1 = linear1(x)
print(f'加权求和后的l1: {l1}')
# 激活函数
output = torch.relu(l1)
print(f'激活函数后的output: {output}')
dropout = nn.Dropout(0.5)
d1 = dropout(output)
print(f'dropout随机失活后: {d1}')
if __name__ == '__main__':
dm01()
测试结果
D:\software\python.exe -X pycache_prefix=C:\Users\HONOR\AppData\Local\JetBrains\PyCharm2025.2\cpython-cache "D:/software/PyCharm 2025.2.4/plugins/python-ce/helpers/pydev/pydevd.py" --multiprocess --qt-support=auto --client 127.0.0.1 --port 52266 --file C:\Users\HONOR\Desktop\python\test25_dropout.py
Connected to: <socket.socket fd=768, family=2, type=1, proto=0, laddr=('127.0.0.1', 52267), raddr=('127.0.0.1', 52266)>.
Connected to pydev debugger (build 252.27397.106)
x:tensor([[4., 6., 3., 3.]])
加权求和后的l1: tensor([[ 2.7057, 2.6478, -0.0525, -2.1561, 4.4334]],
grad_fn=<AddmmBackward0>)
激活函数后的output: tensor([[2.7057, 2.6478, 0.0000, 0.0000, 4.4334]], grad_fn=<ReluBackward0>)
dropout随机失活后: tensor([[5.4114, 5.2955, 0.0000, 0.0000, 0.0000]], grad_fn=<MulBackward0>)
Process finished with exit code 0

















 644
644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









