







1、背景
GPU Direct Peer-to-Peer(P2P) 技术主要用于单机GPU间的高速通信,它使得GPU可以通过PCI Express直接访问目标GPU的显存,避免了通过拷贝到CPU host memory作为中转,大大降低了数据交换的延迟。
为了避免混淆,本文会略过 GPUDirect Remote Direct Memory Access (RDMA),即通过 RDMA 网卡实现 P2P
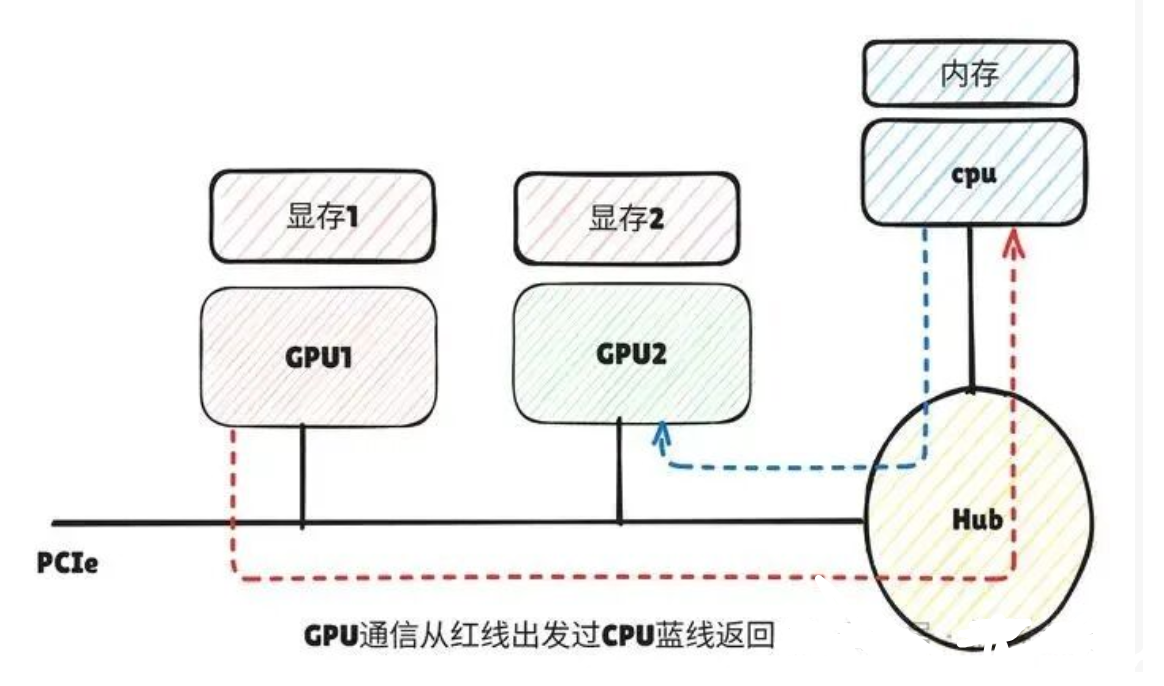
如下图,未开启 P2P 时卡间通信需要通过 CPU
开启后卡间直接通信
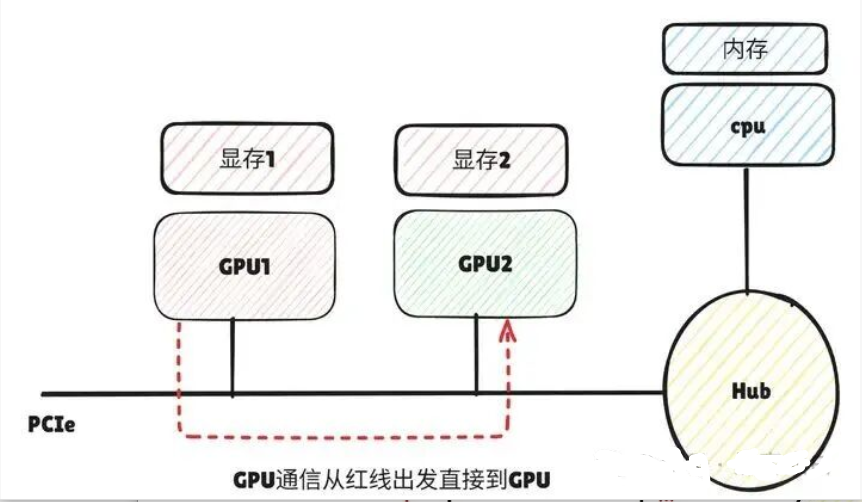
以深度学习应用为例,主流的开源深度学习框架如TensorFlow、MXNet都提供了对GPUDirect P2P的支持,NVIDIA开发的NCCL也提供了针对GPUDirect P2P的特别优化。 GPUDirect P2P发展历经几个比较重要的时间点:
早期基于PCIe和小BAR的P2P
在Resizable BAR技术普及之前,GPU的BAR(Base Address Register)空间通常很小(例如256MB),P2P通信需要通过这个有限的BAR窗口进行,这时候通常通过专用硬件接口实现P2P通信(NVLINK)。
Resizable BAR (ReBAR) 技术的引入
ReBAR允许CPU(以及潜在的其他PCIe设备)访问GPU的全部显存,而不是仅限于小的BAR窗口。例如,在拥有24GB显存的RTX 3090/4090上启用ReBAR,可以将整个24GB显存映射到PCIe地址空间。ReBAR本身是一种PCIe特性,它使能了更高效的P2P实现。
现代PCIe BAR的P2P 技术(BAR1 P2P)出现
在现代数据中心GPU(如Hopper架构的H100)上,可以利用大型BAR(得益于ReBAR)和优化的PCIe特性实现了高效的P2P通信,该技术降低了对传统MAILBOX式硬件协调接口的依赖。
本文所诉的开源驱动正是通过将4090等显卡的 P2P 开启并使用 BAR1P2P 进行卡间通信,来大幅提高通信效率。
2、操作方法
# Bios 需要关闭 IOMMU 开启 resizeBAR
# 首先需要卸载原有驱动,用下面命令检查是否卸载成功
lsmod | grep nvidia
# 如果有残留尝试 rmmod
rmmod nvidia*
# 开始编译
git clone https://github.com/tinygrad/open-gpu-kernel-modules.git
cd open-gpu-kernel-modules
make modules -j$(nproc)
make modules_install -j$(nproc)
# 安装官网驱动的run包
sh ./NVIDIA-Linux-[...].run --no-kernel-modules
3、代码分析
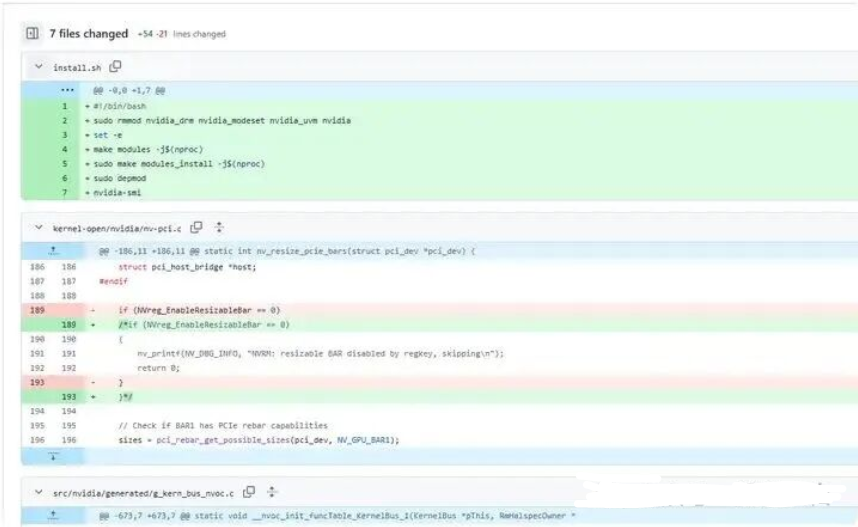 github commit 记录
github commit 记录
一个优秀的 modder 往往只需要在原有的游戏框架上进行简单的修修补补。 TinyCorp 的 geohot 的这次 hack 就是如此,50行代码便突破了老黄对部分显卡的性能封锁。
4、各个文件的修改大致如下:
kernel-open/nvidia/nv-pci. c
中注释掉了检查 NVreg_EnableResizableBar 注册表键值的代码块。通过移除了这个检查,让注册表项如何设置,驱动程序总是会尝试调用 pci_rebar_get_possible_sizes 和后续的调整大小逻辑(如果硬件和内核支持 Resizable BAR)。
src/nvidia/generated/g_kern_bus_nvoc. c
中将多个与 BAR1 P2P 相关的函数指针强制指向了 GH100 后缀的实现版本(原始状态下非 Hopper/Blackwell 架构的 GPU 会指向另一个实现)。这是关键的修改之一。
src/nvidia/src/kernel/gpu/bif/kernel_bif. c
中将
p2pOverride
默认值从
BIF_P2P_NOT_OVERRIDEN
改为
0x11
并将
forceP2PType
默认值改为
NV_REG_STR_RM_FORCE_P2P_TYPE_BAR1P2P
这行为应该会强制驱动开启 P2P 通信功能并强制使用 BAR1 进行 P2P 通信。
src/nvidia/src/kernel/gpu/bus/arch/pascal/kern_bus_gp100. c
中在
kbusCreateP2PMapping_GP100
和
kbusRemoveP2PMapping_GP100
函数中添加了对
_PCIE_BAR1
类型的检查,使得旧架构显卡也能利用BAR1 进行 P2P 映射(即使它原本不官方支持)。
src/nvidia/src/kernel/rmapi/nv_gpu_ops. c
中将
GMMU_APERTURE_PEER
改为
GMMU_APERTURE_SYS_NONCOH
并直接使用
gpumgrGetGpuPhysFbAddr
获取GPU 的 BAR1 物理地址写入 PTE 的
fldAddrSysmem 字段。
这个改动让 GPU 操作 GPU 的 BAR1 地址空间时认为是在操作普通内存,可能是为了避开官方驱动的检查进行欺骗。
src/nvidia/src/libraries/mmu/gmmu_fmt. c
中在
gmmuFmtPtePhysAddrFld
函数中,将
GMMU_APERTURE_PEER
的情况从返回
&pPte->fldAddrPeer
修改为返回
&pPte->fldAddrSysmem
目的应该是适配上一步的改动,PTE 的地址必须写入
fldAddrSysmem 字段。
核心思路大致为让原本不支持或不默认使用 BAR1进行 P2P 通信的 NVIDIA GPU,强制使用其(经过 ReBAR 调整大小后的)BAR1空间来进行 GPU 之间的直接内存访问。这通常是为了在没有 NVLink 连接的 GPU 之间实现更高带宽的 P2P。
TinyCorp 在这个作品之前有对 AMD 显卡做过一次攻击,可以看出团队对于显卡驱动源码是有很深的技术积累的。50行的改动虽然看起来粗暴且没有深入显卡驱动的核心,但是没有对驱动源码/硬件体系的深度掌握是绝对做不出来的。
题外话
黑客&网络安全如何学习
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我们和网安大厂360共同研发的的网安视频教程,内容涵盖了入门必备的操作系统、计算机网络和编程语言等初级知识,而且包含了中级的各种渗透技术,并且还有后期的CTF对抗、区块链安全等高阶技术。总共200多节视频,100多本网安电子书,最新学习路线图和工具安装包都有,不用担心学不全。


















 944
944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









