







硬核干货!Kafka高可用集群在Linux上的终极部署指南(全网最细节解析)
一、引言
1、Kafka简介
Apache Kafka 是一个开源的分布式流处理平台,它最初由 LinkedIn 开发,后来成为 Apache 软件基金会的顶级项目。Kafka 设计用于处理实时数据流,提供了一种高效、可扩展、持久化的方式来进行数据发布和订阅。它通常被描述为一种分布式发布-订阅消息队列,但它实际上超越了传统消息队列的概念。

2、Kafka核心优势
- 高吞吐量:
-
• Kafka 能够处理海量数据,支持每秒数十万条消息的读写操作,即使在大规模部署中也能保持高性能。
-
• 通过高效的文件系统设计和内存管理机制,Kafka 能够在处理大量数据的同时保持低延迟。
-
持久性和可靠性:
-
• Kafka 将数据存储在磁盘上,并支持数据复制(replication),确保即使在节点故障的情况下也能保证数据的可靠性和持久性。
-
• 数据以追加的方式写入日志文件,减少了磁盘的随机写操作,提高了写入速度和数据完整性。
-
可扩展性:
-
• Kafka 具有良好的水平扩展能力,可以通过增加更多的节点来提升系统的处理能力和存储容量。
-
• 分布式架构使得 Kafka 能够轻松地在多台服务器上部署,并且能够动态扩展和收缩集群大小。
-
灵活的发布-订阅模型:
-
• Kafka 支持发布-订阅模式,允许多个消费者订阅同一个主题,并且消费者可以独立消费消息。
-
• 消费者可以控制自己的消费进度,不会影响其他消费者的状态,实现了消息消费的解耦。
二、环境准备
1、服务器
准备3台或者5台Linux服务器,用来组建高可用集群,这里使用3台Centos 7.9来进行搭建,大家也可以使用其他的Linux发行版本
配置如下:

2、服务器环境初始化
3台机器都要执行
关闭Selinux
vi /etc/selinux/config
#修改成如下
SELINUX=disabled
之后重启服务器
`reboot`
关闭并禁用防火墙
`[root@kafka1 ~]# systemctl stop firewalld && systemctl disable firewalld`
修改 /etc/hosts
vi /etc/hosts
# 添加以下内容
192.168.40.100 kafka1
192.168.40.101 kafka2
192.168.40.102 kafka3
修改镜像源
`curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo`
三、安装zookeeper
为什么安装Kafka时,要先安装zookeeper:
ZooKeeper 是一个分布式的协调服务,它为分布式应用程序提供了一套完整的协调服务功能,包括命名服务、配置管理、集群管理和同步等。Kafka 利用 ZooKeeper 来管理其集群中的多个组件,确保系统的稳定性和一致性。
1、上传tar包
apache-zookeeper-3.8.0-bin.tar.gz
tar包可以去官网进行下载 Apache ZooKeeper icon-default.png?t=O83Ahttps://zookeeper.apache.org/releases.html[#download](javascript:😉
icon-default.png?t=O83Ahttps://zookeeper.apache.org/releases.html[#download](javascript:😉
解压tar包至 /opt 下
`tar zxvf apache-zookeeper-3.8.0-bin.tar.gz -C /opt`
2、编辑配置文件
vim /opt/apache-zookeeper-3.8.0-bin/conf/zoo.cfg
# 输入如下内容
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/zookeeper/zkData
dataLogDir=/opt/zookeeper/zkLog
clientPort=2181
server.1=kafka1:2188:3888
server.2=kafka2:2188:3888
server.3=kafka3:2188:3888
4lw.commands.whitelist=*

tickTime=2000:
- • tickTime 定义了 ZooKeeper 服务器之间的心跳间隔时间(毫秒)。它是 ZooKeeper 中最基本的单位时间。默认值通常是 2000 毫秒(即 2 秒)。
initLimit=10:
- • initLimit 定义了初始同步阶段的最大超时时间(心跳次数)。这意味着在初始同步阶段,跟随者(follower)必须在 initLimit * tickTime 毫秒内完成与领导者(leader)的同步。例如,这里设置为 20 秒(10 * 2000 毫秒)。
syncLimit=5:
- • syncLimit 定义了在领导者和跟随者之间发送消息的最大超时时间(心跳次数)。这意味着在同步阶段,跟随者必须在 syncLimit * tickTime 毫秒内响应领导者的请求。例如,这里设置为 10 秒(5 * 2000 毫秒)。
dataDir=/opt/zookeeper/zkData:
- • dataDir 指定 ZooKeeper 服务器用来存储快照(snapshot)的目录。
dataLogDir=/opt/zookeeper/zkLog:
- • dataLogDir 指定 ZooKeeper 服务器用来存储事务日志(transaction logs)的目录。这是从 ZooKeeper 3.4.6 开始引入的一个配置项,使得日志和数据可以分开存储。
clientPort=2181:
- • clientPort 指定客户端连接到 ZooKeeper 服务器的端口,默认为 2181。
server.1=ka1:2188:3888:
- • server.N 表示第 N 台服务器的信息,格式为 hostname:peerPort:leaderPort。peerPort 是服务器之间通信的端口,leaderPort 是选举领导者时使用的端口。
4lw.commands.whitelist=*:
- • 4lw.commands.whitelist 指定客户端可以执行的命令白名单。* 表示允许所有命令。
3、创建数据目录
mkdir -p /opt/zookeeper/zkData
mkdir -p /opt/zookeeper/zkLog
创建集群ID文件
在3台机器上分别执行
[root@kafka1 bin]# echo 1 > /opt/zookeeper/zkData/myid
[root@kafka2 bin]# echo 2 > /opt/zookeeper/zkData/myid
[root@kafka3 bin]# echo 3 > /opt/zookeeper/zkData/myid
4、安装JAVA
`yum install -y java-1.8.0-openjdk-devel`
5、启动zookeeper
cd /opt/apache-zookeeper-3.8.0-bin/bin/
./zkServer.sh start ../conf/zoo.cfg &
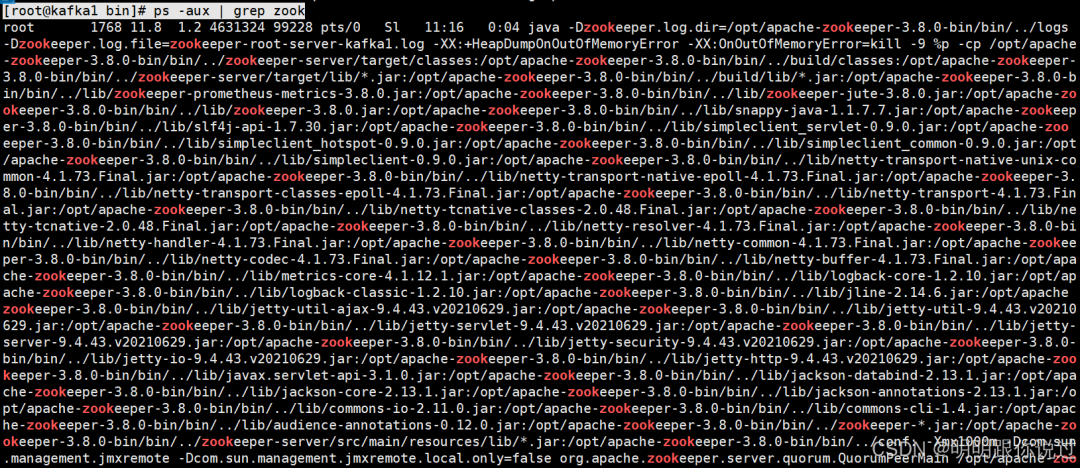
查看状态
`[root@kafka1 bin]# ps -aux | grep zook`
四**、**Kafka集群搭建
1、上传tar包
资源包大家可以到官网下载
https://kafka.apache.org/
解压至指定目录
[root@kafka1 ~]# tar zxvf kafka_2.13-3.1.0.tgz -C /opt/
[root@kafka2 ~]# tar zxvf kafka_2.13-3.1.0.tgz -C /opt/
[root@kafka3 ~]# tar zxvf kafka_2.13-3.1.0.tgz -C /opt/
2、编辑配置文件
在kafka1上执行
[root@kafka1 config]# vim /opt/kafka_2.13-3.1.0/config/server.properties
#输入如下内容
broker.id=0
listeners=PLAINTEXT://kafka1:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/kafka-logs
num.partitions=5
default.replication.factor=2
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=kafka1:2181,kafka2:2181,kafka3:2181/kafka
zookeeper.connection.timeout.ms=18000
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
在kafka2上执行
[root@kafka2 config]# vim /opt/kafka_2.13-3.1.0/config/server.properties
#输入如下内容
broker.id=1
listeners=PLAINTEXT://kafka2:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/kafka-logs
num.partitions=5
default.replication.factor=2
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=kafka1:2181,kafka2:2181,kafka3:2181/kafka
zookeeper.connection.timeout.ms=18000
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
在kafka3上执行
[root@kafka3 config]# vim /opt/kafka_2.13-3.1.0/config/server.properties
#输入如下内容
broker.id=2
listeners=PLAINTEXT://kafka3:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/kafka-logs
num.partitions=5
default.replication.factor=2
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=kafka1:2181,kafka2:2181,kafka3:2181/kafka
zookeeper.connection.timeout.ms=18000
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0

broker.id=0
- • 这是 Kafka broker 的唯一标识符。每个 broker 必须有唯一的 ID。这里的值为 0,意味着这是一个集群中的单个 broker 或者是第一个 broker。
listeners=PLAINTEXT://kafka1:9092
- • 定义了 broker 监听的网络接口和端口。此处使用 PLAINTEXT 协议,意味着没有加密。kafka1:9092 表示监听名为 kafka1 的主机上的 9092 端口。
num.network.threads=3
- • 指定了用于网络请求处理的线程数。网络请求包括接收来自生产者的消息、发送消息给消费者等操作。这里设置为 3 个线程。
num.io.threads=8
- • 指定了用于处理 I/O 请求的线程数。I/O 请求包括磁盘上的读写操作。这里设置为 8 个线程。
socket.send.buffer.bytes=102400
- • 设置了发送套接字的缓冲区大小(单位:字节)。此配置影响网络数据包的发送速度。此处设置为 102400 字节。
socket.receive.buffer.bytes=102400
- • 设置了接收套接字的缓冲区大小(单位:字节)。此配置影响网络数据包的接收速度。此处设置为 102400 字节。
socket.request.max.bytes=104857600
- • 定义了从客户端接收的最大请求大小(单位:字节)。这有助于防止因过大请求而导致的内存溢出。此处设置为 104857600 字节,即约 100MB。
log.dirs=/opt/kafka-logs
- • 指定了日志文件存储的位置。日志文件包含了 Kafka topic 的数据。这里设置的日志目录为 /opt/kafka-logs。
num.partitions=5
- • 指定了默认主题分区的数量。分区越多,通常意味着更高的并发度。这里设置的主题默认分区数为 5。
default.replication.factor=2
- • 指定了创建新主题时的默认复制因子。复制因子决定了每个分区的副本数量。这里设置的复制因子为 2,意味着每个分区有 2 份副本。
num.recovery.threads.per.data.dir=1
- • 指定了用于恢复日志段的线程数。每个数据目录可以有不同的线程数。这里设置为 1 个线程。
offsets.topic.replication.factor=1
- • 指定了 _consumer_offsets 主题的复制因子。此主题用于存储消费者的偏移量信息。这里设置的复制因子为 1,意味着只有一个副本。
transaction.state.log.replication.factor=1
- • 指定了 _transactions 主题的复制因子。此主题用于记录事务状态。这里设置的复制因子为 1,意味着只有一个副本。
transaction.state.log.min.isr=1
- • 指定了 _transactions 主题的最小 ISR(In-Sync Replicas)数量。ISR 是与 leader 同步的副本集合。这里设置的最小 ISR 数量为 1。
log.retention.hours=168
- • 指定了日志数据保留的时间长度(单位:小时)。这里设置的日志保留时间为 168 小时,即 7 天。
log.segment.bytes=1073741824
- • 指定了日志段的最大大小(单位:字节)。一旦达到这个大小,Kafka 就会创建一个新的日志段。这里设置的日志段大小为 1073741824 字节,即 1GB。
log.retention.check.interval.ms=300000
- • 指定了检查日志清理的间隔时间(单位:毫秒)。这里设置的检查间隔为 300000 毫秒,即 5 分钟。
zookeeper.connect=kafka1:2181,kafka2:2181,kafka3:2181/kafka
- • 指定了 ZooKeeper 服务器列表。ZooKeeper 用于协调 Kafka 集群。这里设置的 ZooKeeper 服务器为 kafka1:2181, kafka2:2181, kafka3:2181,路径为 /kafka。
zookeeper.connection.timeout.ms=18000
- • 指定了 Kafka 与 ZooKeeper 之间的连接超时时间(单位:毫秒)。这里设置的超时时间为 18000 毫秒,即 18 秒。请注意,zookeeper.connection.timeout.ms 在配置中出现了两次,应该是误写,只需要保留一次即可。
group.initial.rebalance.delay.ms=0
- • 指定了消费者组初始重新平衡的延迟时间(单位:毫秒)。这里设置的延迟时间为 0,即立即开始重新平衡。
3、创建数据目录
在3台机器上分别执行
`mkdir /opt/kafka-logs`
4、启动kafka
[root@kafka1 bin]# cd /opt/kafka_2.13-3.1.0/bin/
[root@kafka1 bin]# ./kafka-server-start.sh -daemon ../config/server.properties
[root@kafka2 bin]# cd /opt/kafka_2.13-3.1.0/bin/
[root@kafka2 bin]# ./kafka-server-start.sh -daemon ../config/server.properties
[root@kafka3 bin]# cd /opt/kafka_2.13-3.1.0/bin/
[root@kafka3 bin]# ./kafka-server-start.sh -daemon ../config/server.properties
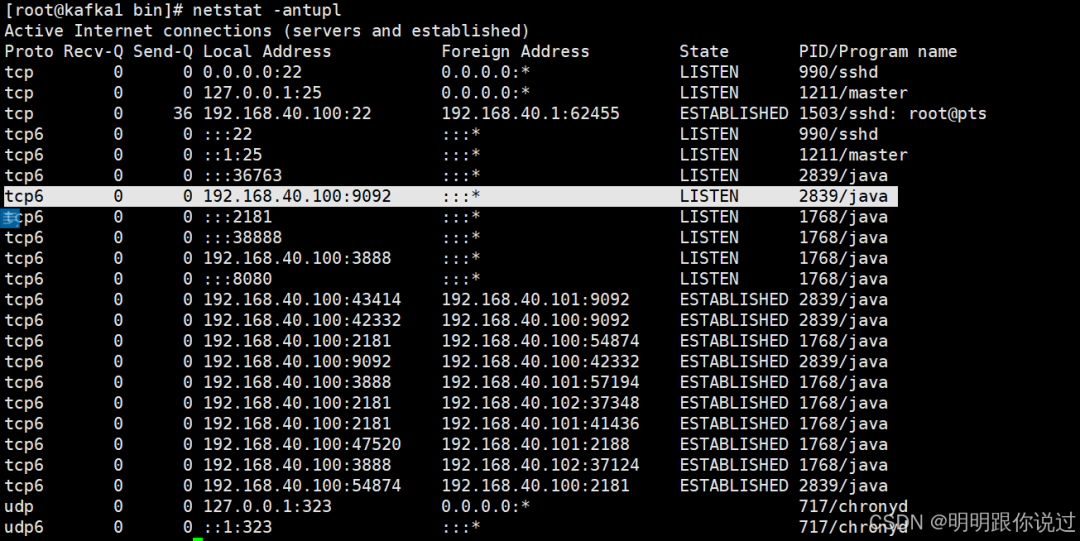
5、查看端口状态
`[root@kafka1 bin]# netstat -antupl`
五、测试
1、创建Topic
前面我们已经将kafka集群搭建起来了,接下来创建一个Topic进行写入测试,如果不清楚Topic是什么,可以翻看作者之前的文章。
在kafka1上执行
[root@kafka1 bin]# cd /opt/kafka_2.13-3.1.0/bin
[root@kafka1 bin]# ./kafka-topics.sh --bootstrap-server=192.168.40.100:9092 --topic test --create --partitions=3 --replication-factor=2
- • **–bootstrap-server:**指定 Kafka broker 的地址和端口号。这里的 192.168.40.100:9092 指定了 broker 的 IP 地址为 192.168.40.100,端口号为 9092。
- • **–topic:**指定要操作的主题名称。在这个例子中,主题名为 test。
- • **–create:**告诉 Kafka 创建一个新主题。如果主题已经存在,这条命令将会失败,除非你配置了允许创建已存在的主题。
- • **–partitions:**指定主题的分区数。分区数决定了主题能够并行处理消息的能力。在这个例子中,主题 test 将会有 3 个分区。
- • **–replication-factor:**指定主题的复制因子。复制因子决定了每个分区的副本数量,这对于数据的冗余和可靠性非常重要。在这个例子中,主题 test 的每个分区将会有 2 个副本。
查看Topic
`[root@kafka1 bin]# ./kafka-topics.sh --bootstrap-server=192.168.40.100:9092 --list`

2、生产消息
`[root@kafka1 bin]# ./kafka-console-producer.sh --bootstrap-server 192.168.40.100:9092 --topic test`
向我们刚刚创建的test Topic写入几条消息

3、消费消息
`[root@kafka1 bin]# ./kafka-console-consumer.sh --bootstrap-server=192.168.40.100:9092 --topic test --from-beginning`
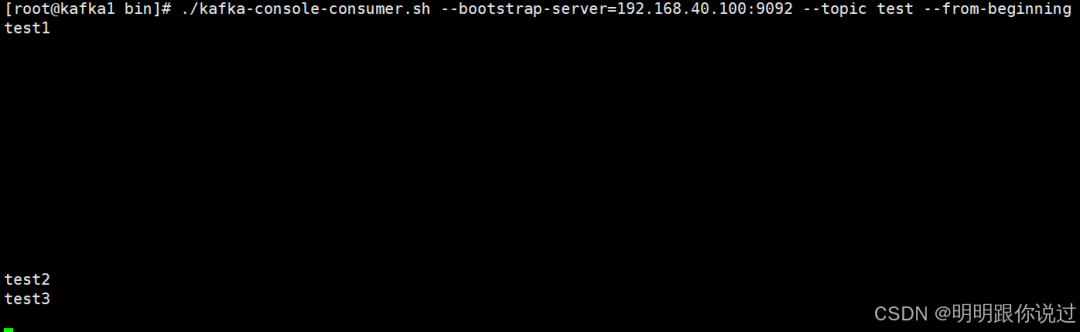
如果能看到之前生产的消息,则证明集群搭建成功
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些关于大数据的文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!
黑客&网络安全如何学习**
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图

攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我们和网安大厂360共同研发的的网安视频教程,之前都是内部资源,专业方面绝对可以秒杀国内99%的机构和个人教学!全网独一份,你不可能在网上找到这么专业的教程。
内容涵盖了入门必备的操作系统、计算机网络和编程语言等初级知识,而且包含了中级的各种渗透技术,并且还有后期的CTF对抗、区块链安全等高阶技术。总共200多节视频,200多G的资源,不用担心学不全。

因篇幅有限,仅展示部分资料,需要见下图即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
————————————————
本文转自 https://blog.youkuaiyun.com/bdfcfff77fa/article/details/149347288?spm=1001.2014.3001.5502,如有侵权,请联系删除。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









