








LLM构建流程
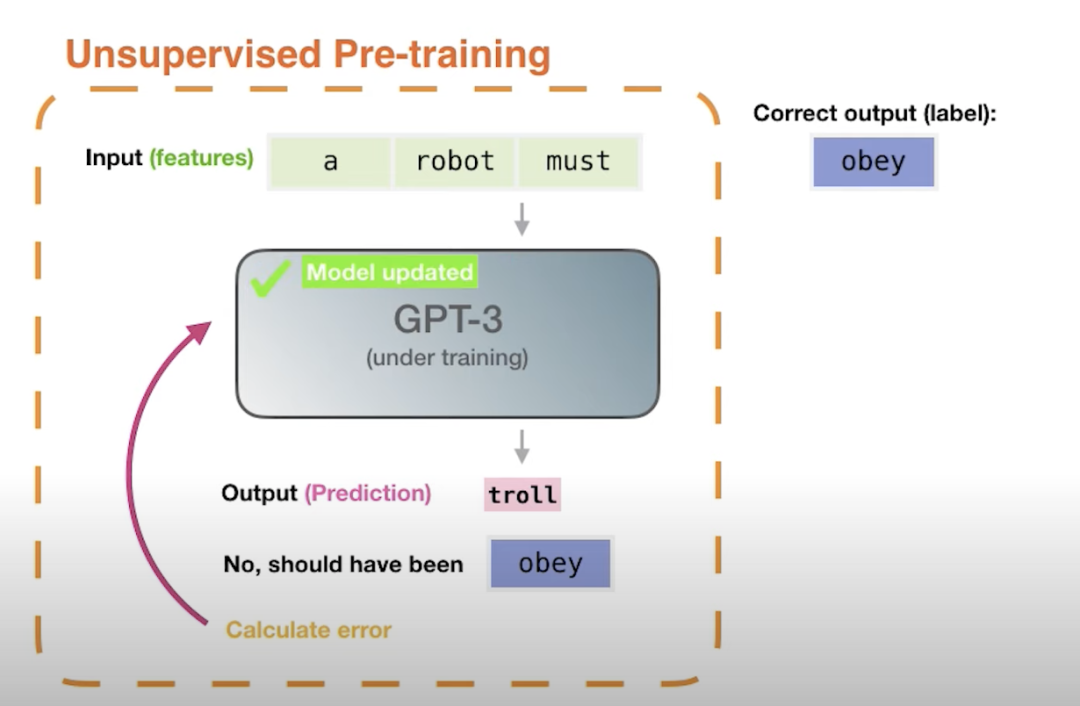
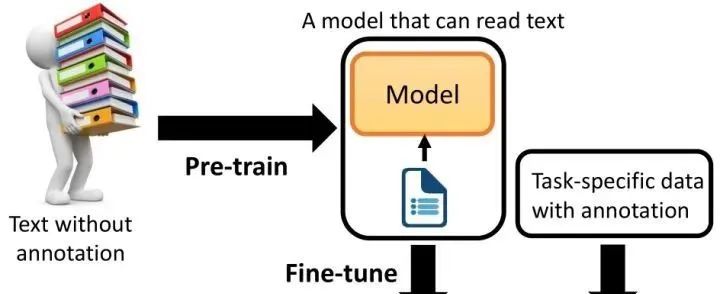
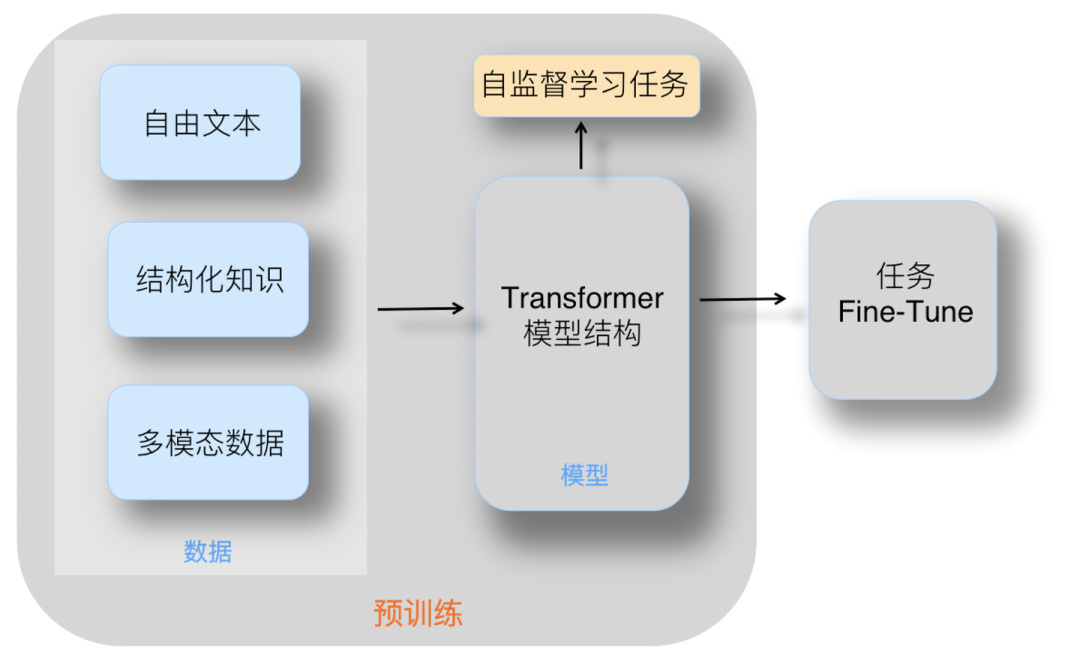
大模型(LLM,Large Language Model)的构建流程,特别是OpenAI所使用的大语言模型GPT构建流程,主要包含四个阶段:预训练、有监督微调、奖励建模和强化学习**。这四个阶段各自需要不同规模的数据集、不同类型的算法,并会产出不同类型的模型,同时所需的资源也有显著差异。**

LLM构建流程
一、预训练(Pre-training)****
**什么是预训练?**预训练技术通过从大规模未标记数据中学习通用特征和先验知识,减少对标记数据的依赖,加速并优化在有限数据集上的模型训练。
-
目标:让模型学习语言的统计模式和语义信息。
-
数据集:利用海量的训练数据,这些数据可以来自互联网网页、维基百科、书籍、GitHub、论文、问答网站等,构建包含数千亿甚至数万亿单词的具有多样性的内容。
-
算法与资源:利用由数千块高性能GPU和高速网络组成的超级计算机,花费数十天甚至数月的时间完成深度神经网络参数的训练,构建基础模型(Foundation Model)。这一阶段对计算资源的需求极大,例如GPT-3的训练就使用了1000+的NVIDIA GPU,并花费了相当长的时间。
-
结果:基础模型能够对长文本进行建模,具备语言生成能力,根据输入的提示词,模型可以生成文本补全句子。
Pre-training
**为什么需要预训练?**预训练是为了让模型在见到特定任务数据之前,先通过学习大量通用数据来捕获广泛有用的特征,从而提升模型在目标任务上的表现和泛化能力。
Pre-training
预训练的技术原理是什么?预训练利用大量无标签或弱标签的数据,通过某种算法模型进行训练,得到一个初步具备通用知识或能力的模型******。**********
Pre-training
********预训练是语言模型学习的初始阶段。**************在预训练期间,模型会接触大量未标记的文本数据,例如书籍、文章和网站。******目标是捕获文本语料库中存在的底层模式、结构和语义知识。
Pre-training
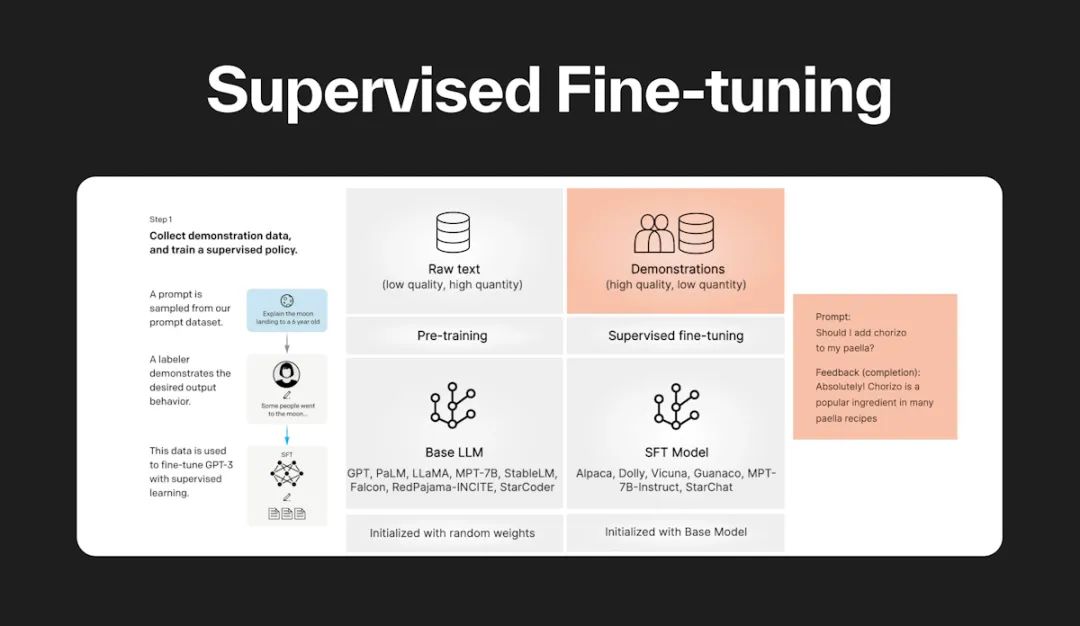
二、有监督**微调(**Supervised Fine Tuning**)**
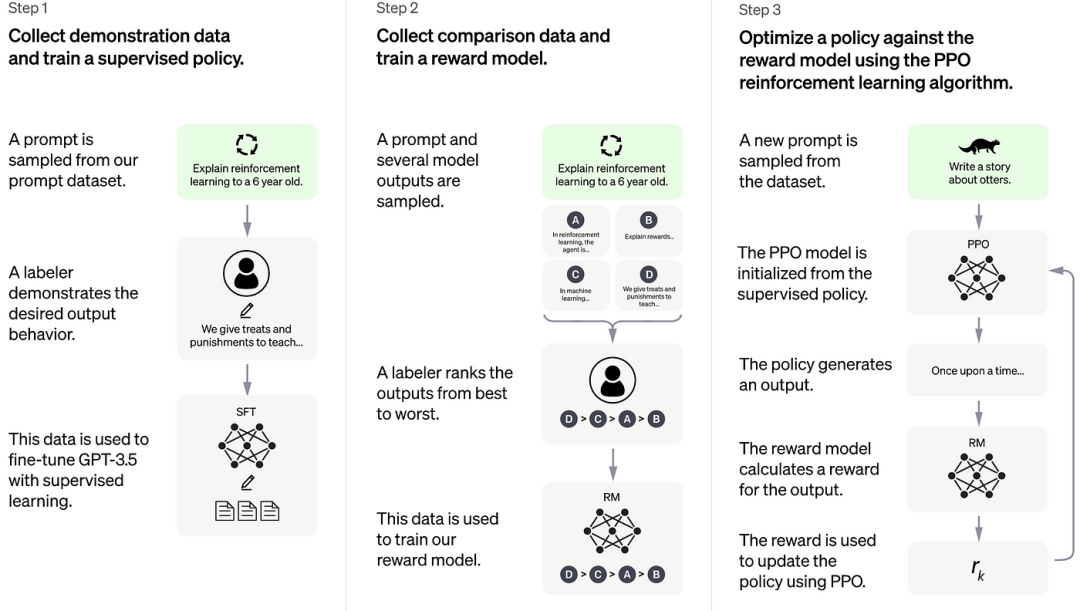
**什么是有监督微调?有监督微调(Supervised Fine-Tuning, SFT),**也被称为指令微调(Instruction Tuning)。在已经预训练好的模型基础上,通过使用有标注的特定任务数据对模型进行进一步的训练和调整,以提高模型在特定任务或领域上的性能。
-
目标:使模型具备完成特定任务(如问题回答、翻译、写作等)的能力。
-
数据集:使用少量高质量数据集,这些数据集包含用户输入的提示词和对应的理想输出结果。
-
算法:在基础模型的基础上进行有监督训练,使用与预训练阶段相同的语言模型训练算法。
-
资源:相比预训练阶段,有监督微调所需的计算资源较少,通常只需要数十块GPU,并在数天内完成训练。
-
结果:得到有监督微调模型(SFT模型),该模型具备初步的指令理解能力和上下文理解能力,能够完成开放领域问答、阅读理解、翻译、生成代码等任务。
Supervised Fine-tuning
****为什么需要有监督微调?******尽管预训练模型已经在大规模数据集上学到了丰富的通用特征和先验知识,但这些特征和知识可能并不完全适用于特定的目标任务。**微调通过在新任务的少量标注数据上进一步训练预训练模型,使模型能够学习到与目标任务相关的特定特征和规律,从而更好地适应新任务。
-
**减少对新数据的需求:**可以利用预训练模型已经学到的知识,减少对新数据的需求,从而在小数据集上获得更好的性能。
-
**降低训练成本:**微调只需要调整预训练模型的部分参数,而不是从头开始训练整个模型,因此可以大大减少训练时间和所需的计算资源。

Supervised Fine-tuning
有监督微调的技术原理是什么?在预训练模型的基础上,针对特定任务或数据领域,通过在新任务的小规模标注数据集上进一步训练和******调整模型的部分或全部参数**************,使模型能够更好地适应新任务,提高在新任务上的性能。********
Supervised Fine-tuning
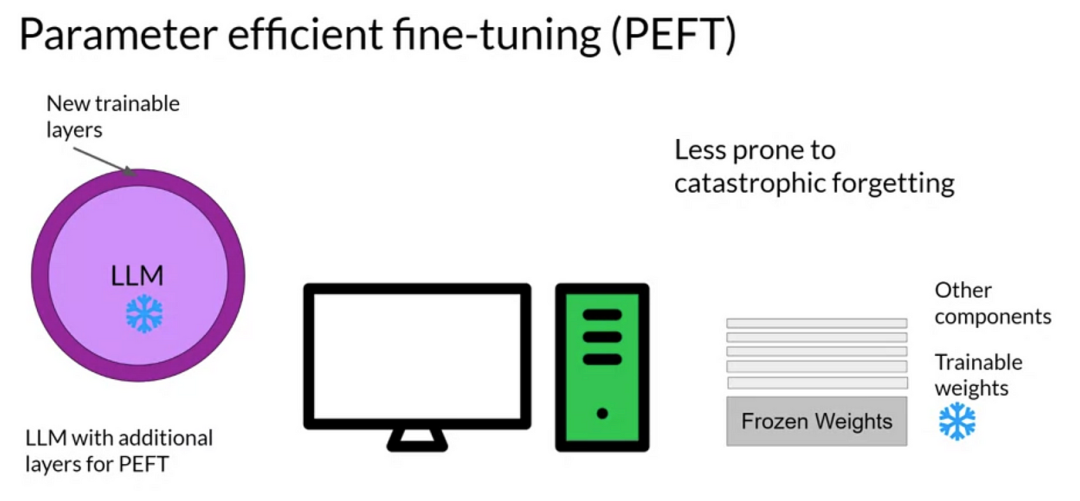
**********有监督微调如何分类?**SFT根据是否调整全部参数,可以细分为全面微调(Full Fine-tuning)和部分/参数高效微调(Parameter-Efficient Fine-tuning, PEFT)。

Supervised Fine-tuning
-
定义:在新任务上调整模型的全部参数,以使其完全适应新任务。
-
步骤:加载预训练模型 → 在新任务数据集上训练模型,调整所有参数。
-
应用:当新任务与预训练任务差异较大,或者想要充分利用新任务数据集时,可以选择全面微调。
-
**定义:**仅调整模型的部分参数,如添加一些可训练的适配器(adapters)、前缀(prefixes)或微调少量的参数,以保持模型大部分参数不变的同时,实现对新任务的适应。
-
**步骤:**加载预训练模型 → 在模型中添加可训练的组件或选择部分参数 → 在新任务数据集上训练这些组件或参数。
-
应用:当计算资源有限,或者想要快速适应新任务而不影响模型在其他任务上的性能时,PEFT是一个很好的选择。
**************PEFT
三、奖励建模(Reward Modeling)
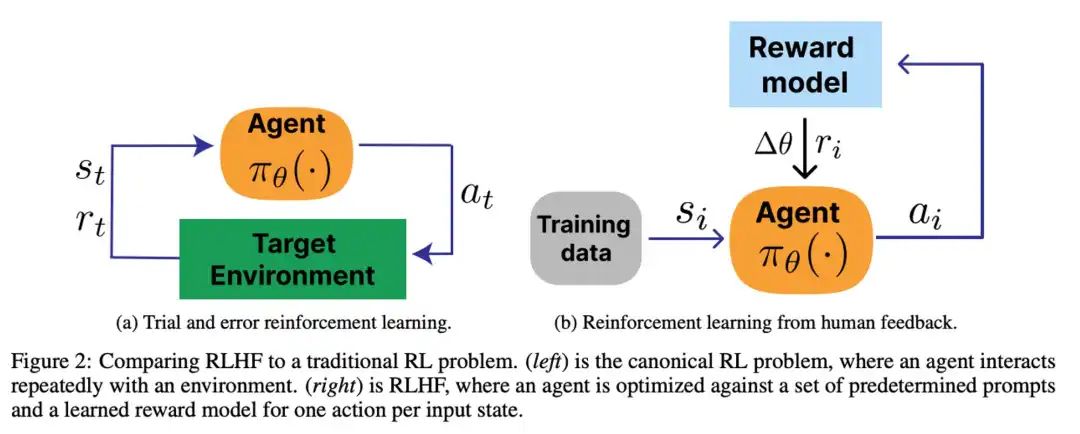
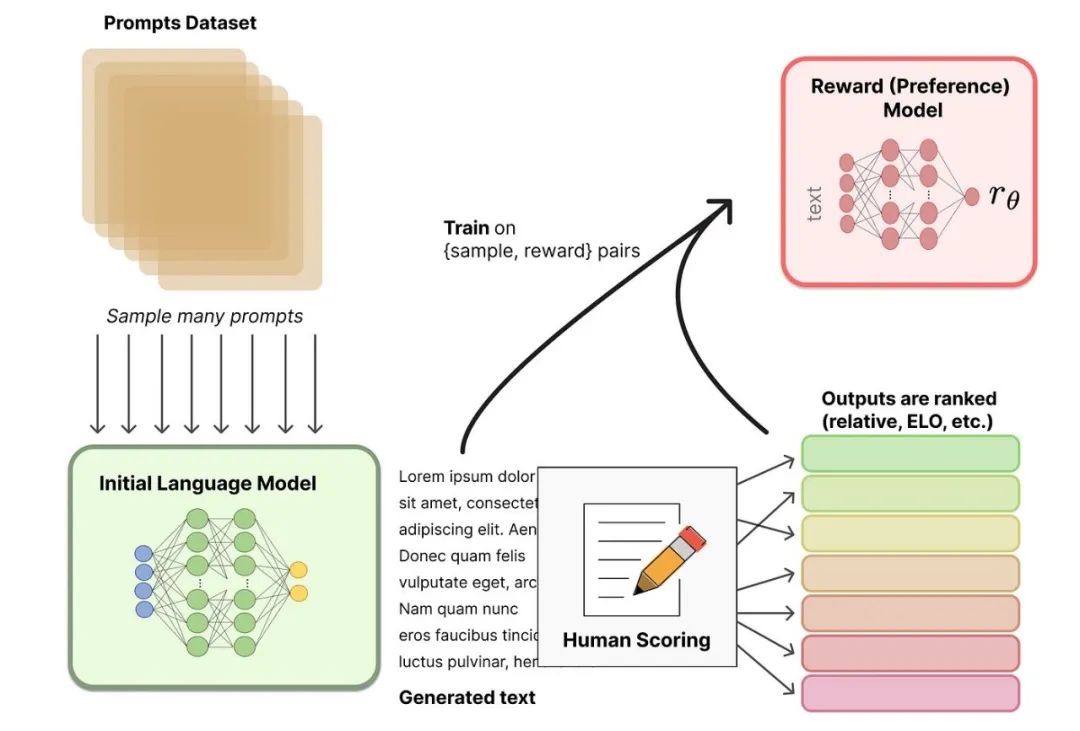
**什么是奖励模型?**************奖励模型是一个文本质量对比模型,它接受环境状态、生成的结果等信息作为输入,并输出一个奖励值作为反馈。************奖励模型通过训练,能够识别并区分不同输出文本之间的优劣,为后续的强化学习阶段提供准确的奖励信号。
-
目标:构建一个文本质量对比模型,用于评估模型生成文本的质量。
-
数据集:需要百万量级的对比数据标注,这些数据标注需要消耗大量的人力和时间。
-
算法:通过二分类模型,对输入的两个结果之间的优劣进行判断。
-
资源:奖励模型的训练同样需要数十块GPU,并在数天内完成。
-
结果:得到一个能够评估模型生成文本质量的奖励模型,该模型本身并不能单独提供给用户使用,但为后续强化学习阶段提供重要支持。
Reward Modeling
为什么需要奖励模型****?****奖励模型能够量化并优化LLM生成的文本质量,使其更符合人类期望,从而提升LLM的性能和实用性。
Reward Modeling
**********奖励模型如何构建与训练?**********奖励模型采用二分类结构,通过对比人工标注的文本数据集进行训练,优化参数以最小化预测错误率或最大化排序准确性,需要大量计算资源和时间。
-
模型架构:奖励模型通常采用二分类模型的结构,通过输入一对文本(即两个输出结果),判断它们之间的优劣关系。
-
训练数据:奖励模型的训练数据通常来源于人工标注的对比数据集。标注者需要根据预设的标准(如准确性、有用性、流畅性等)对多个输出文本进行排序或分类。
-
训练过程:奖励模型的训练过程类似于其他机器学习模型,需要使用大量的计算资源(如数十块GPU)和较长时间(数天)来完成。

Reward Modeling
四、强化学习(Reinforcement Learning)
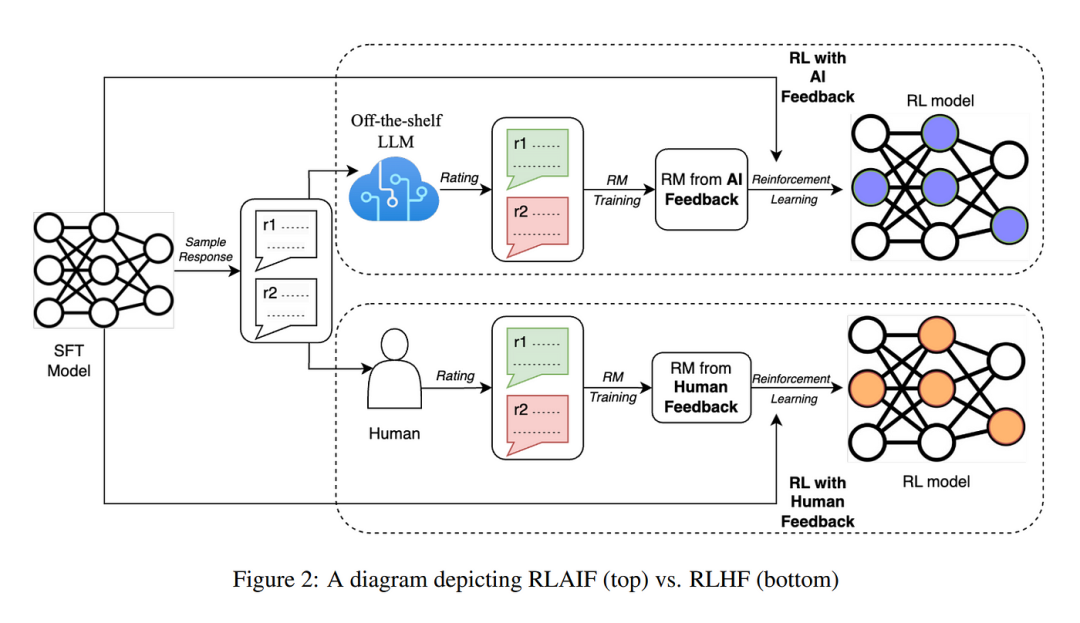
**什么是强化学习?**根据数十万名用户给出的提示词,利用前一阶段训练的奖励模型,给出SFT模型对用户提示词补全结果的质量评估,并与语言模型建模目标综合得到更好的效果。
-
目标:根据奖励模型的评估,进一步优化模型生成文本的能力,使其更符合人类期望。
-
数据集:使用数十万用户给出的提示词和奖励模型评估的结果。
-
算法:利用强化学习算法(如PPO)调整模型参数,使模型生成的文本能够获得更高的奖励。
-
资源:相比预训练阶段,强化学习所需的计算资源较少,通常也只需要数十块GPU,并在数天内完成训练。
-
结果:得到最终的强化学习模型(RL模型),该模型具备更强的理解和生成能力,能够更好地满足人类的需求和期望。
Reinforcement Learning
为什么需要强化学习****?****使用强化学习,在SFT模型的基础上调整参数,使最终生成的文本可以获得更高的奖励(Reward)。
题外话
黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
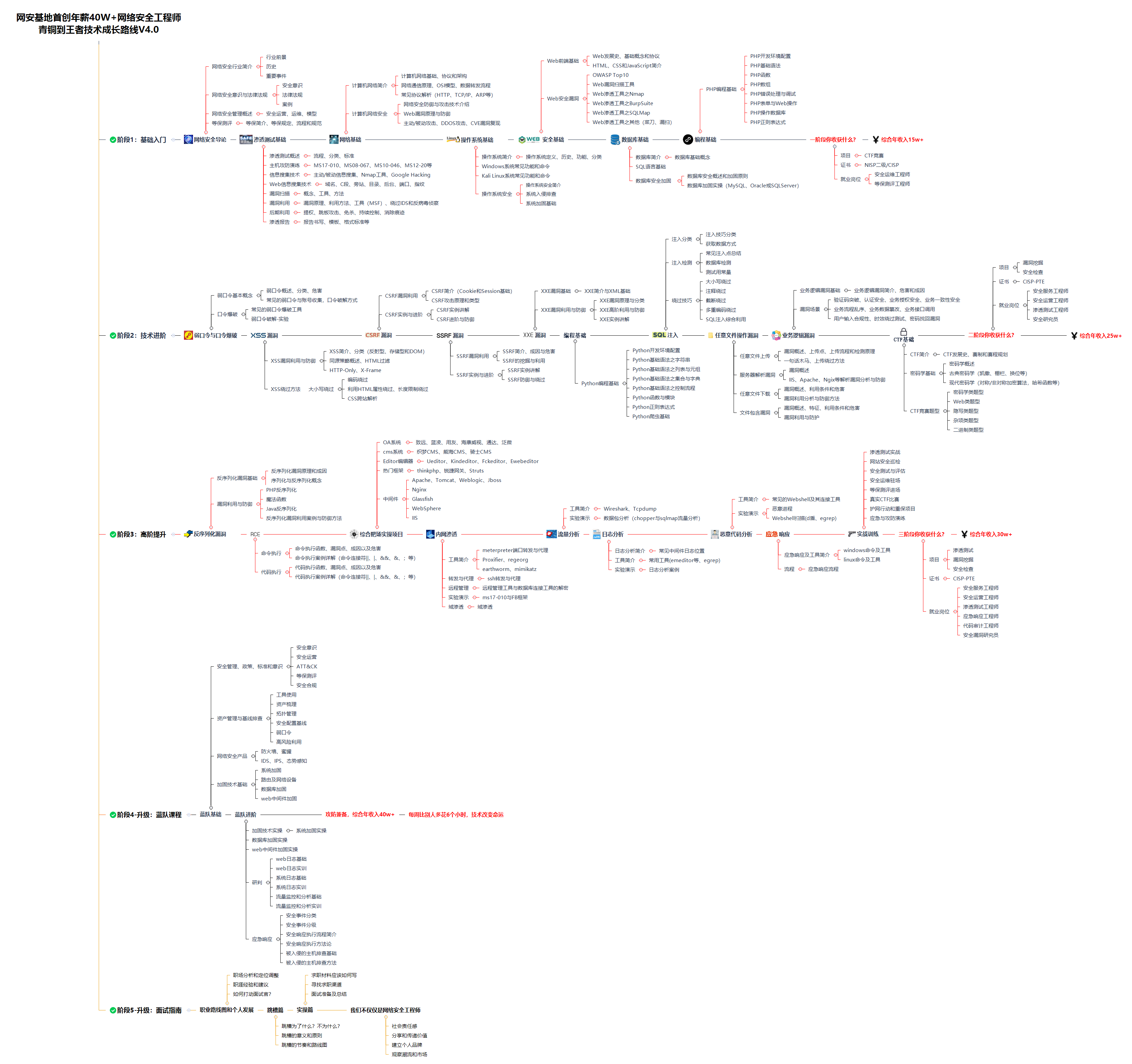
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









