






💟博主:程序员君君:优快云作者、博客专家、全栈领域优质创作者
💟专注于计算机毕业设计,大数据、深度学习、Java、小程序、python、安卓等技术领域
📲文章末尾获取源码+数据库
🌈还有大家在毕设选题(免费咨询指导选题),毕设、作业项目以及论文编写等相关问题
⭐都可以直接找我解答、希望可以帮助更多人
今日要和大家分享的是《 基于Hadoop的健康饮食推荐系统的设计与实现 》
关键技术: Python、Spring Boot、Vue.js、Element UI、Spring Data JPA、Hadoop
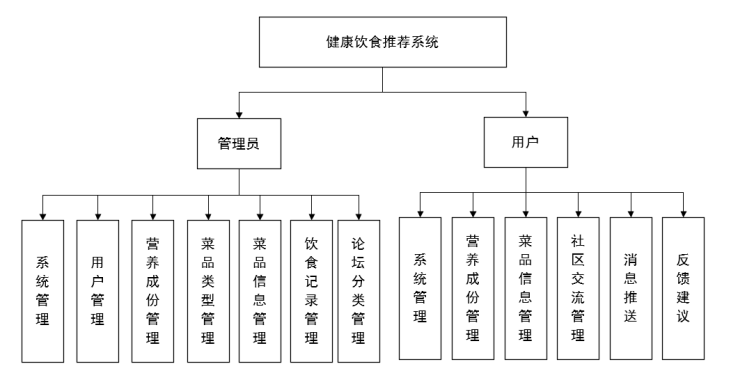
4.1系统功能结构设计图
根据需求说明设计系统各功能模块。采用模块化设计方法实现一个复杂结构进行简化,分成一个个小的容易解决的板块,然后再将小的板块继续分化成功能单一的更小模块。模块化设计方法使测试调试、维护更容易,减少模块间的干扰。各模块可以同时开发提高开发效率。本系统功能结构图:
5.2 用户功能实现
用户注册与登录模块是系统的核心功能之一。用户通过输入账号和密码进行注册,系统验证账号的唯一性后将用户信息存储在Hadoop分布式文件系统中。登录时,用户输入账号密码,系统进行校验并生成会话标识符,确保用户后续操作的安全性和连续性。该模块采用简单的加密算法对密码进行处理,保障用户信息安全。如图5-1 所示:
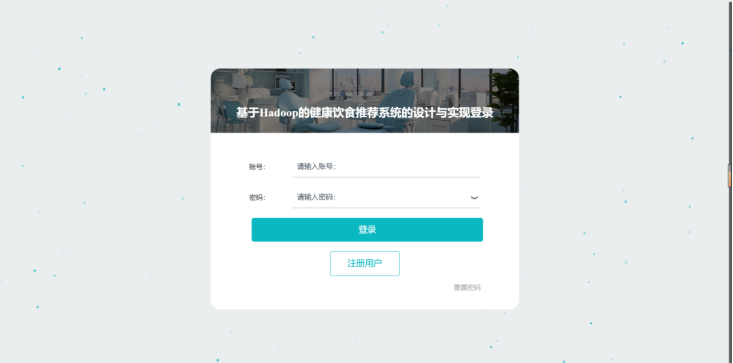
图5-1系统注册页面
用户个人信息管理模块允许用户查看和编辑个人资料,如姓名、性别、年龄等基本信息。用户登录后可进入个人信息页面,修改并保存更新后的信息。所有用户数据均存储于Hadoop集群中,确保数据的高可用性和可靠性。系统提供友好的用户界面,简化用户操作流程,提升用户体验。如图5-2 所示:
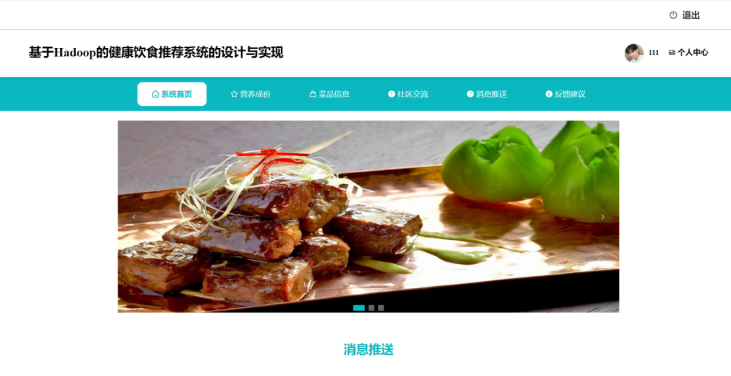
图5-2用户界面
用户营养成分页面的实现依托Hadoop生态体系的高效数据处理能力:首先,通过Hive或Spark对HDFS中存储的用户饮食日志(含食物种类、分量、摄入时间)进行清洗与聚合,结合预置的食物营养成分表(如USDA数据库)进行关联计算,生成用户每日营养素摄入量(如热量、蛋白质、维生素等)。其次,利用Hadoop的MapReduce并行计算能力优化批量数据分析性能,确保实时性。最终,前端通过API获取后端分析结果,以动态图表(ECharts)展示营养摄入分布,并提供超标/不足项预警及个性化饮食建议,形成完整的数据闭环。如图5-3 所示:
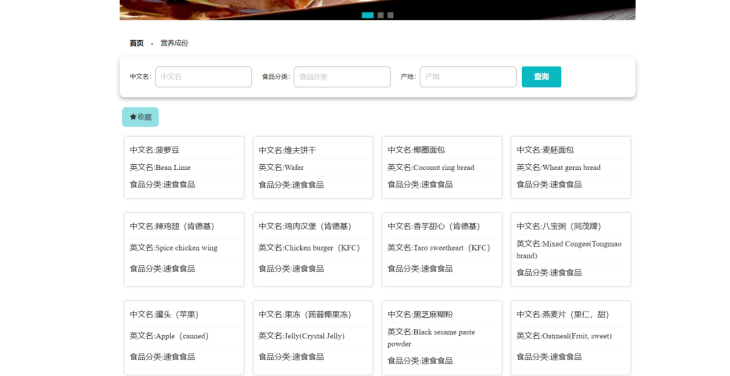
图5-3 用户营养成份页面
用户菜品信息页面的实现基于Hadoop生态实现高效数据管理与处理:系统通过Flume或Kafka收集用户上传的菜品数据(如图片、名称、食材列表),利用OCR技术与NLP模型解析图片及文本信息,并将结构化数据存储至HDFS。后端采用Spark对菜品数据进行清洗、去重及营养成分匹配(关联预置的营养数据库),通过Hive构建菜品标签体系(如“低脂”“高纤维”)。前端通过RESTful API调用分析结果,以卡片式布局展示菜品详情,支持多维度筛选(如热量范围、食材禁忌)及营养成分对比,实现数据驱动的菜品信息可视化呈现。如图5-4所示:
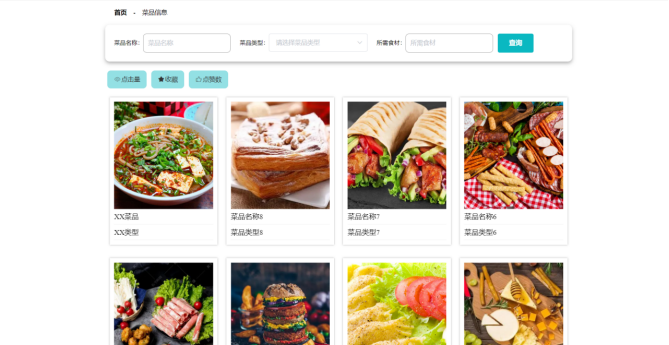
图5-4 用户菜品信息页面
用户社区交流页面的实现依托Hadoop生态构建了高效、可扩展的交互平台。系统通过Kafka实时收集用户发布的饮食心得、健康食谱等交流内容,并利用Spark Streaming进行数据清洗与分类(如按主题、标签聚合)。后端基于HBase存储用户互动数据(点赞、评论、关注关系),结合Hive构建社区话题分析模型,挖掘热门趋势。前端通过Vue.js动态渲染内容,支持按关键词搜索、话题排序及个性化推荐。同时,借助Hadoop的MapReduce能力对历史数据进行批量分析,优化内容推荐算法,最终形成以数据驱动的健康饮食社区生态。如图5-5所示:
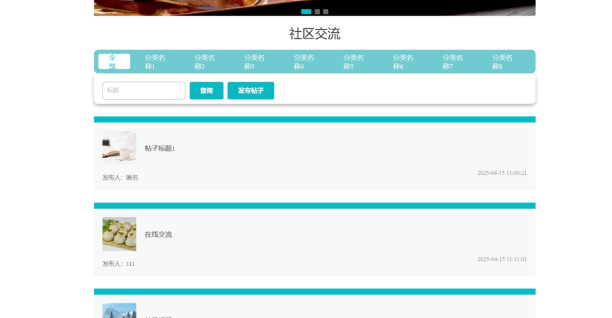
图5-5 用户社区交流页面
用户个性化推荐菜单浏览模块基于用户的饮食记录和个人信息,利用Hadoop平台的数据分析能力,为用户提供个性化的健康饮食推荐。用户可以选择感兴趣的菜品,获取详细的制作方法和营养成分,方便日常饮食安排。图5-4 用户个性化推荐菜单浏览页面。
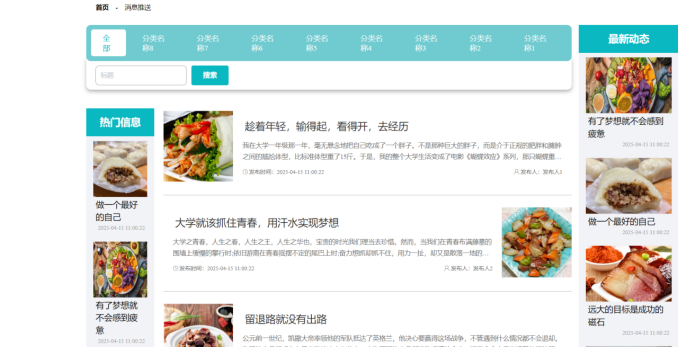
图5-6 用户消息推送页面
用户消息推送页面基于Hadoop生态实现精准触达:系统通过Spark Streaming实时处理用户行为日志(如饮食记录、社区互动),结合Hive构建用户画像(如饮食偏好、健康目标)。利用Hadoop的分布式存储能力整合消息模板库,通过Flink实现消息路由规则匹配,支持按用户标签(如“减脂用户”)定向推送健康贴士或食谱推荐,最终通过第三方服务(如短信/APP通知)完成消息分发。如图5-7所示:
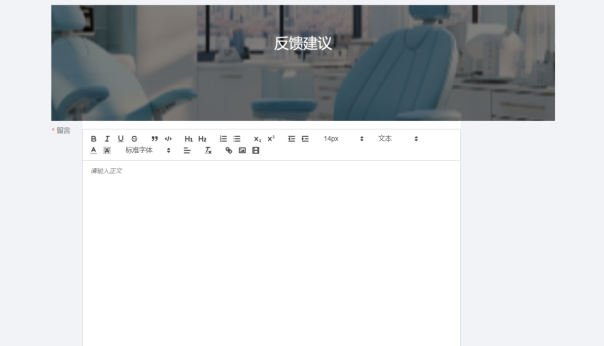
图5-7 用户反馈建议页面
5.3 管理员功能实现
管理员用户信息管理模块用于管理员查看和管理所有用户的注册信息。管理员登录后可进入管理后台,查询、添加、删除或修改用户信息。系统提供了便捷的搜索和过滤功能,帮助管理员快速定位特定用户。所有操作均记录在日志中,确保系统的透明性和安全性。管理员还可以批量导出用户数据,便于进一步分析和管理。图5-5 管理员用户信息管理页面
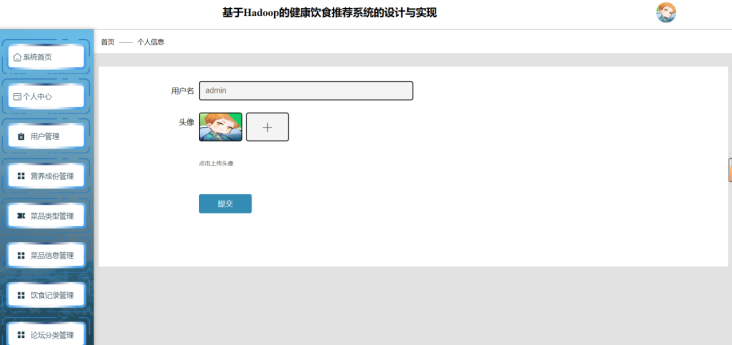
图5-8 管理员用户信息管理页面
管理员营养成分页面的实现基于Hadoop生态构建了高效数据管理平台:系统通过Spark对HDFS中存储的食品营养数据(如热量、维生素含量)进行批量处理与校验,利用Hive构建多维分析模型(按食品类别、营养素类型聚合)。管理员可通过前端页面动态增删改查食品数据,并借助Hadoop的分布式计算能力实时更新营养成分推荐规则,确保用户端数据准确性。如图5-9所示:
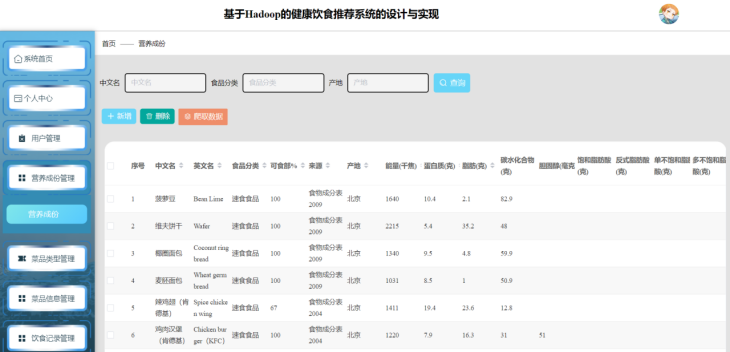
图5-9 管理员营养成份页面
管理员菜品类型页面的实现依托Hadoop生态构建了灵活的菜品分类体系:系统通过Hive对HDFS中存储的菜品数据(如名称、食材、烹饪方式)进行结构化处理,利用Spark MLlib训练菜品分类模型(如基于TF-IDF的文本聚类)。管理员可通过前端页面直观管理菜品标签(如“素食”“低糖”),并通过MapReduce任务批量更新菜品分类规则,确保推荐系统的菜品类型维度实时同步。如图5-10所示:
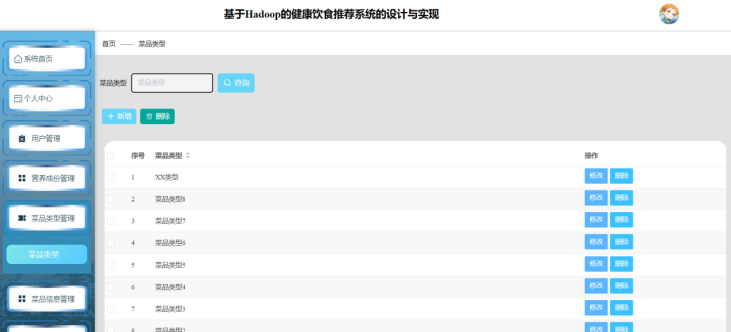
图5-10 管理员菜品类型页面
管理员菜品信息页面基于Hadoop生态实现高效数据运维:系统通过Hive对HDFS中的菜品数据(名称、食材、营养值等)进行结构化存储与索引,利用Spark进行批量数据校验(如检测重复菜品、营养值异常)。管理员可通过前端页面增删改查菜品信息,借助MapReduce任务同步更新菜品库至推荐引擎,并利用Hadoop的容错机制保障数据一致性,确保用户端菜品推荐准确无误。如图5-11所示:
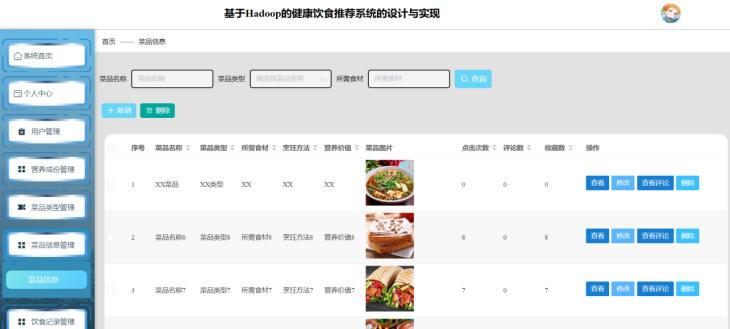
图5-11 管理员菜品信息页面
管理员饮食记录页面的实现基于Hadoop生态构建了可靠的饮食数据管理平台:系统通过Flume收集用户饮食记录日志并存储至HDFS,利用Spark Streaming进行实时清洗与结构化处理。管理员可通过Hive查询接口按用户、时间范围筛选记录,借助MapReduce任务分析饮食趋势(如热量超标用户分布)。如图5-12所示:
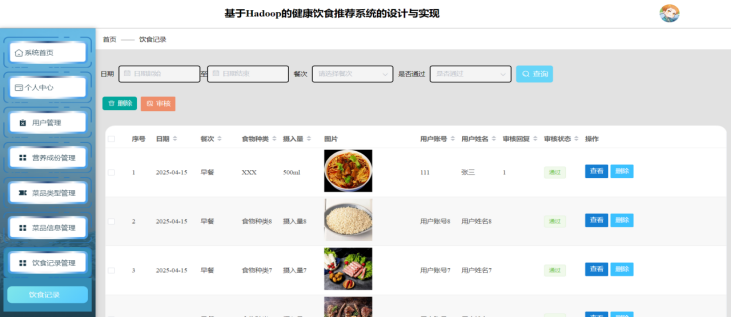
图5-12 管理员饮食记录页面
管理员社区交流页面依托Hadoop生态实现高效社区管理:系统通过Kafka收集用户社区互动数据(如帖子、评论),利用Spark Streaming实时分析话题热度与违规内容,存储至HBase。管理员可通过Hive查询接口筛选敏感信息,借助MapReduce批量处理用户举报数据,并通过前端页面执行内容审核、话题管理操作,确保社区健康交流环境。如图5-13所示:
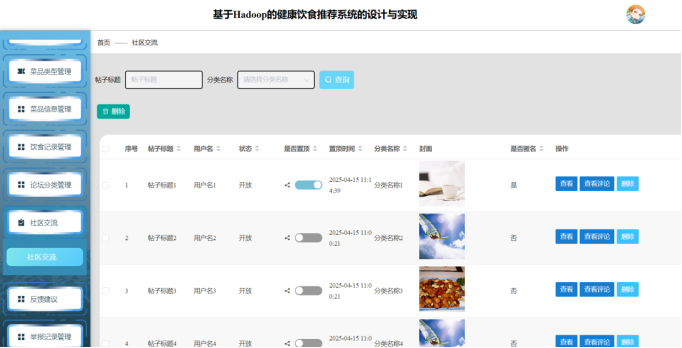
图5-13 管理员社区交流页面
管理员推荐算法优化模块允许管理员调整和优化个性化推荐算法的参数。管理员可以通过管理后台设置不同的权重和规则,影响推荐结果的精准度。系统提供可视化工具,帮助管理员直观地观察算法效果并进行微调。所有优化操作均记录在日志中,确保算法调整过程的透明性和可控性。图5-14 管理员推荐算法优化页面
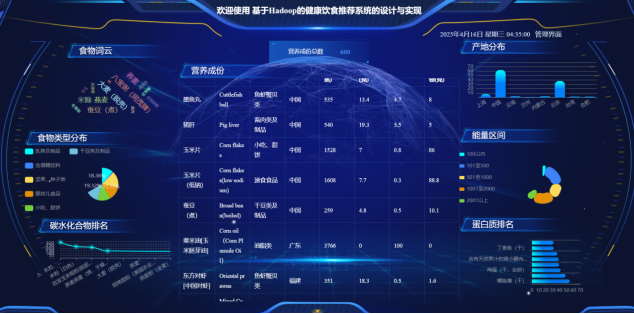
图5-14 管理员推荐算法优化页面
专注于大学生日常作业项目和毕设项目,讲解开发,答疑辅导
点击下方名片可以联系哦~

















 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









