







 超级会员免费看
超级会员免费看
 K-means算法是一种无监督聚类方法,用于将相似对象分组。它依赖于初始种子点的选择,易受初始值影响。算法包括选择k个初始中心点,分配数据点到最近的中心,更新中心点,直至收敛。实战部分展示了在足球队分类和图片压缩中的应用。
K-means算法是一种无监督聚类方法,用于将相似对象分组。它依赖于初始种子点的选择,易受初始值影响。算法包括选择k个初始中心点,分配数据点到最近的中心,更新中心点,直至收敛。实战部分展示了在足球队分类和图片压缩中的应用。
K均值算法(K-means)聚类
【数据下载】(链接:https://pan.baidu.com/s/1ctCgW6aze256SZd3Oib1HQ
提取码:1111)
【关键词】K个种子,均值
一、K-means算法原理
聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中。
K-Means算法是一种聚类分析(cluster analysis)的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。
K-Means算法主要解决的问题如下图所示。我们可以看到,在图的左边有一些点,我们用肉眼可以看出来有四个点群,但是我们怎么通过计算机程序找出这几个点群来呢?于是就出现了我们的K-Means算法

这个算法其实很简单,如下图所示:
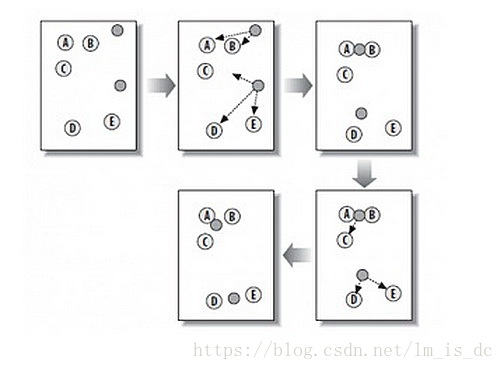
从上图中,我们可以看到,A,B,C,D,E是五个在图中点。而灰色的点是我们的种子点,也就是我们用来找点群的点。有两个种子点,所以K=2。<

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











