








 超级会员免费看
超级会员免费看

 本文介绍了Python爬虫框架Scrapy的详细内容,包括Scrapy的架构、运作流程、安装方法、制作爬虫的步骤、入门案例、Scrapy Shell的使用、选择器选择器、Item Pipeline的实现、Spider的使用以及自动翻页爬取的原理。通过实例展示了如何在Scrapy中创建项目、编写爬虫和存储数据,并提供了设置配置的建议。
本文介绍了Python爬虫框架Scrapy的详细内容,包括Scrapy的架构、运作流程、安装方法、制作爬虫的步骤、入门案例、Scrapy Shell的使用、选择器选择器、Item Pipeline的实现、Spider的使用以及自动翻页爬取的原理。通过实例展示了如何在Scrapy中创建项目、编写爬虫和存储数据,并提供了设置配置的建议。
Scrapy 框架
关注公众号“轻松学编程”了解更多。
一、简介
- Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
- 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
- Scrapy 使用了 Twisted(其主要对手是Tornado)多线程异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
二、Scrapy架构图(绿线是数据流向)
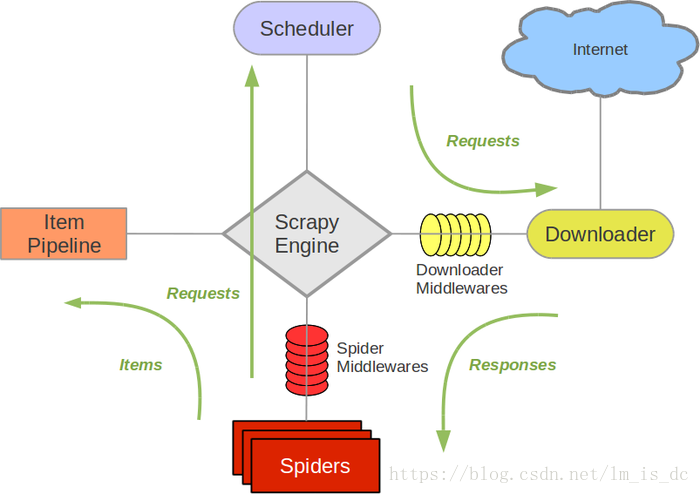
- Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downlo

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 65万+
65万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











