








 超级会员免费看
超级会员免费看

 本文介绍了确定k-means聚类中最佳k值的两种方法:手肘法和轮廓系数法。通过计算误差平方和(SSE)和轮廓系数,分析得出在给定数据集上,k=11时达到最优聚类效果。
本文介绍了确定k-means聚类中最佳k值的两种方法:手肘法和轮廓系数法。通过计算误差平方和(SSE)和轮廓系数,分析得出在给定数据集上,k=11时达到最优聚类效果。
1、手肘法
获取最佳的k值
1、手肘法的核心指标是SSE(sum of the squared errors,误差平方和),
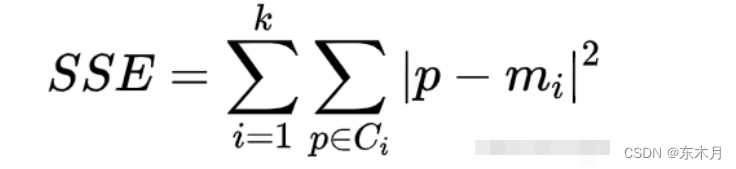
其中,Ci是第i个簇,p是Ci中的样本点,mi是Ci的质心(Ci中所有样本的均值),SSE是所有样本的聚类误差,代表了聚类效果的好坏。
手肘法的核心思想是:随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,
那么误差平方和SSE自然会逐渐变小。并且,当k小于真实聚类数时,由于k的增大会大幅增加每个簇的聚合程度,
故SSE的下降幅度会很大,而当k到达真实聚类数时,再增加k所得到的聚合程度回报会迅速变小,
所以SSE的下降幅度会骤减,然后随着k值的继续增大而趋于平缓,也就是说SSE和k的关系图是一个手肘的形状,
而这个肘部对应的k值就是数据的真实聚类数。
当然,这也是该方法被称为手肘法的原因。
代码:
from sklearn.cluster import KMeans
from matplotlib 
 订阅专栏 解锁全文
订阅专栏 解锁全文



















 6451
6451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











