




 Linux内核中的链表实现是一种通用的、不带数据域的链表结构,提高了代码的扩展性和通用性。链表节点仅包含两个指针,通过`list_head`结构体与数据结构相结合,允许从任何节点遍历链表。内核提供了初始化、添加、删除节点的函数。相比传统的链表实现,内核链表更灵活,适用于多种数据结构的链表操作。示例代码展示了如何在内核模块中使用这种链表结构。
Linux内核中的链表实现是一种通用的、不带数据域的链表结构,提高了代码的扩展性和通用性。链表节点仅包含两个指针,通过`list_head`结构体与数据结构相结合,允许从任何节点遍历链表。内核提供了初始化、添加、删除节点的函数。相比传统的链表实现,内核链表更灵活,适用于多种数据结构的链表操作。示例代码展示了如何在内核模块中使用这种链表结构。
一、链表
1.常用的链表结构
特点:每个链表的节点就是一个数据结构
struct common_fox {
unsigned long tail_length; //尾巴长度
unsigned long weight; //重量
bool is_fantastic; //这只动物奇妙吗?
struct common_fox *next;
struct common_fox *prev;
};
2.linux内核的链表结构
特点:链表的节点只是数据结构的一部分
优点:1.常用的带数据域的链表降低了链表的通用性,不容易扩展。linux内核定义的链表结构不带数据域,只需要两个指针完成链表的操作。将链表节点加入数据结构,具备非常高的扩展性,通用性。
2.每个fox节点都包含一个list_head指针,于是可以从任何一个节点起遍历链表。
struct list_head {
struct list_head *next;
struct list_head *prev;
};
struct linux_fox {
unsigned long tail_length;
unsigned long weight;
bool is_fantastic;
struct list_head list;
};
那么问题来了,其实一个指向链表结构的指针通常是无用的,我们需要的是一个指向包含list_head结构体的指针。以linux_fox为例,我们执行链表操作使用的是list_head类型的数据,但是信息都包含在linux_fox中,需要一种途径由list_head获得linux_fox。
使用宏container_of()我们可以很方便的从链表指针找到副结构中包含的任何变量。这是应为在c语言中,一个给定的结构体的变量偏移地址在编译时就被ABI固定下来了。
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
3.linux内核链表的操作函数
1)初始化头结点
通过宏定义#define LIST_HEAD(name)来实现头结点的初始化,linux内核中头结点一般只当做头结点不初始化数据。
LIST_HEAD(dog)等同于struct list_head dog; foo.next = &dog; dog.prev = &dog;
struct list_head {
struct list_head *next, *prev; //双向链表
};
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
2)向链表中添加一个节点
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
if (!__list_add_valid(new, prev, next)) //判断合法
return;
next->prev = new;
new->next = next;
new->prev = prev;
WRITE_ONCE(prev->next, new);
} 这个函数在prev和next间插入一个节点new。
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next); //添加元素
}
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head); //在尾部添加元素
}
3)从链表中删除一个节点
当执行删除操作时,被删节点的prev和next指针被指向一个固定的位置。其中,宏定义LIST_POISON1和LIST_POISON2定义在poison.h头文件中,是内核空间的两个地址。
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
————————————————
版权声明:本文为优快云博主「菜菜的狗子」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/weixin_43211535/article/details/105976325
1、双循环链表传统实现:
在传统的双循环链表实现中,如果创建某种数据结构的双循环链表,通常采用的办法是在这个数据结构的类型定义中加入两个(指向该类型对象的)指针next和prev。
这里给出了对应的节点结构、空的双循环链表和非空的双循环链表示意图。
2、Linux内核中双循环链表实现
在linux内核中,有大量的数据结构需要用到双循环链表,例如进程、文件、模块、页面等。若采用双循环链表的传统实现方式,需要为这些数据结构维护各自的链表,并且为每个链表都要设计插入、删除等操作函数。因为用来维持链表的next和prev指针指向对应类型的对象,因此一种数据结构的链表操作函数不能用于操作其它数据结构的链表。
在Linux源代码树的include/linux/list.h文件中,采用了一种类型无关的双循环链表实现方式。其思想是将指针prev和next从具体的数据结构中提取出来构成一种通用的"双链表"数据结构list_head。如果需要构造某类对象的特定链表,则在其结构(被称为宿主数据结构)中定义一个类型为list_head类型的成员,通过这个成员将这类对象连接起来,形成所需链表,并通过通用链表函数对其进行操作。其优点是只需编写通用链表函数,即可构造和操作不同对象的链表,而无需为每类对象的每种列表编写专用函数,实现了代码的重用。
.内核链表和普通链表的区别
内核链表是一个双向链表,但是与普通的双向链表又有所区别。内核链表中的链表元素不与特定类型相关,具有通用性。
我们先来看一幅图
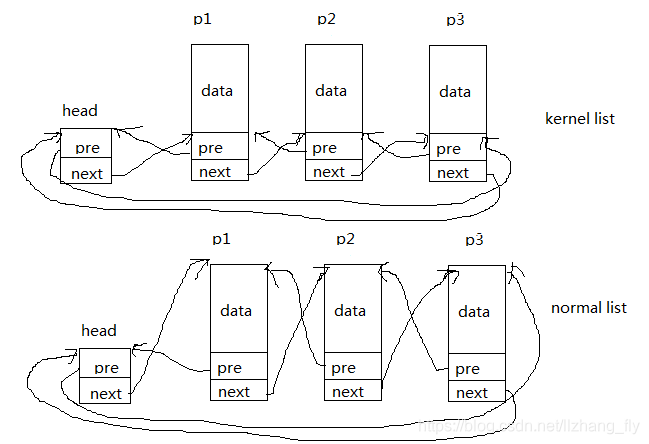
 转存失败
转存失败kernel list展示的是内核链表的结构,normallist展示的是普通链表的结构。head是链表头,p1,p2,p3是链表节点。从图中可以看出普通链表的p1的next指针是指向的结构体p2的地址,p2的pre指针指向p1结构体的地址。而内核链表的p1的next指向的是p2结构体中包含pre和next部分的地址,的p2的pre指向的是p1结构体中包含pre和next部分的地址。依此类推,这就是区别。内核结构元素不与特定类型结构相关,任何结构体都可通过内核的添加成为链表中的节点。
- #include <linux/kernel.h>
- #include <linux/module.h>
- #include <linux/init.h>
- #include <linux/slab.h>
- #include <linux/list.h>
- MODULE_LICENSE("GPL");
- MODULE_AUTHOR("David Xie");
- MODULE_DESCRIPTION("ListModule");
- MODULE_ALIAS("List module");
- struct student
- {
- char name[100];
- int num;
- struct list_head list;
- };
- struct student *pstudent;
- struct student *tmp_student;
- struct list_head student_list;
- struct list_head *pos;
- int mylist_init()
- {
- inti = 0;
- INIT_LIST_HEAD(&student_list);
- pstudent= kmalloc(sizeof(struct student)*5,GFP_KERNEL);
- memset(pstudent,0,sizeof(structstudent)*5);
- for(i=0;i<5;i++)
- {
- sprintf(pstudent[i].name,"Student%d",i+1);
- pstudent[i].num= i+1;
- list_add(&(pstudent[i].list), &student_list);
- }
- list_for_each(pos,&student_list)
- {
- tmp_student= list_entry(pos,struct student,list);
- printk("<0>student%d name: %s\n",tmp_student->num,tmp_student->name);
- }
- return0;
- }
- void mylist_exit()
- {
- inti ;
- for(i=0;i<5;i++)
- {
- list_del(&(pstudent[i].list));
- }
- kfree(pstudent);
- }
- module_init(mylist_init);
- module_exit(mylist_exit);
1、在Linux内核中经常能够看到 struct list_head 这样的一个结构体,这个就是内核中的一个链表,内核链表
struct list_head {
struct list_head *next, *prev;
};
这个结构体中只有两个指向链表结构体的指针,分为前向指针和后向指针,因为可以用来构建一个双向链表,但是这个链表的用法与我们普通的链表的用法不一样,
我们的一般的链表结构体中都会包含两部分:一个是指针(前向指针和后向指针)部分,还有就是有效数据部分。将我们链表需要存放的数据放在结构体中的有效数据
区中,通过两个节点分别指向上一个节点和下一个节点。这是一般的链表的使用方法。
(1)但是内核链表的结构体中只有两个指针,并没有有效数据区,所以内核链表的用法和我们的普通链表的用法是不一样的,我们使用内核链表的方法就是:
自己建立一个结构体去包含这个内核链表,将整个结构体作为一个链表的节点,然后使用内置的链表的前向指针指向下一个结构体中内置的链表,使用内置的链表的
后向指针指向上一个结构体中内置的链表。
例如:
struct A{
struct list_head list;
.........
};
struct A a;
struct A b;
struct A c;
a.list.next = b.list;
b.list.prev = a.list, b.list.next = c.list;
c.list.prev = b.list;
————————————————
版权声明:本文为优快云博主「bandaoyu」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/bandaoyu/article/details/89878604

















 2032
2032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









