 RAG:提升大语言模型性能的指南
RAG:提升大语言模型性能的指南





一、大语言模型的困境:从“鹦鹉学舌”到“知识饥渴”
在人工智能领域,大语言模型(LLMs)的出现曾让我们惊叹于其语言能力——它们能流畅对话、撰写文章,甚至模仿人类的逻辑推理。然而,随着应用场景的深入,这些“超级智能鹦鹉”的局限性逐渐暴露:
- 时效性缺失
模型训练数据往往截止到某个固定时间点,无法回答“昨晚比赛结果”“最新政策变化”等实时问题。
- 知识边界模糊
面对企业内部文档、专业领域知识等私有数据时,传统LLMs因缺乏访问权限而无法准确响应。
- 幻觉风险
当模型对未知领域信息缺乏可靠依据时,可能会“编造事实”,导致回答不可信。
这些问题的核心,在于传统LLMs的知识更新依赖静态训练,无法动态获取外部信息。正如让一位渊博的历史学家评论最新社交媒体趋势,其知识体系的“时差”使其无法有效应对。为突破这一困境,检索增强生成(Retrieval-Augmented Generation,RAG)技术应运而生,成为连接LLMs与实时、私有知识的桥梁。
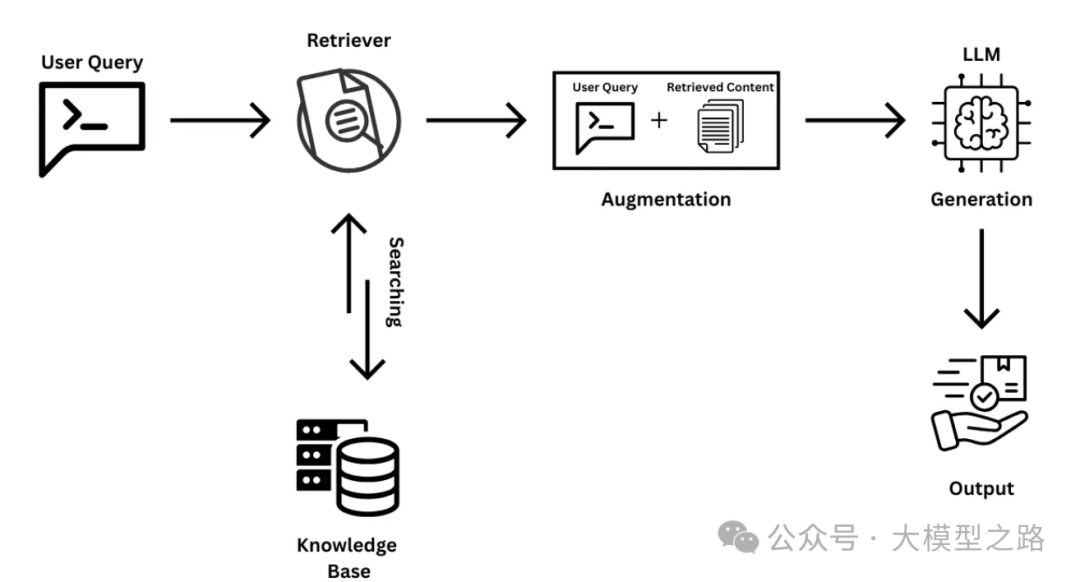
二、RAG的核心逻辑:给模型装上“动态知识库”
RAG的本质,是将检索(Retrieval)与生成(Generation)相结合,让LLMs在回答问题时不再依赖“记忆”,而是通过实时检索外部知识库获取最新信息。其核心优势可类比为:
- 从“死记硬背”到“活学活用”
传统LLMs如同“考前突击的学生”,依赖训练数据中的记忆;RAG则像“带教材进考场的考生”,可随时查阅最新资料。
- 从“单一知识库”到“多元信息网”
RAG支持接入企业内部文档、行业数据库、实时新闻等多源数据,打破传统模型对公开数据的依赖。
- 从“模糊猜测”到“有据可依”
通过检索验证信息来源,显著降低模型幻觉风险,提升回答可信度。
(一)RAG的三大应用场景
-
企业知识管理在大型企业中,海量知识分散在员工头脑、历史文件或内部系统中。当新问题出现时,传统方式需耗费大量时间查找资料,而RAG可作为“企业级大脑”:
-
实时检索产品手册、技术文档、过往解决方案,辅助员工快速定位答案;
-
整合跨部门知识,避免重复劳动,提升决策效率。
-
-
智能客服升级传统客服机器人依赖预设FAQ,无法处理复杂或个性化
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1886
1886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











