



graphrag最近引起了极大的关注,我在之前的两篇文章中分别介绍了GraphRag-知识图谱结合LLM 的检索增强的原理及GraphRag安装部署及简单测试,有兴趣的同学可以自行查看。今天重点聊一下GraphRag实战,将GraphRag与Neo4j集成实现一个简单的查询案例。
简单来讲,graphrag是从非结构化文本中提取实体及其关系,通过提取这些结构化信息来构建知识图谱,然后将这些实体通过Leiden算法进行社区划分并总结

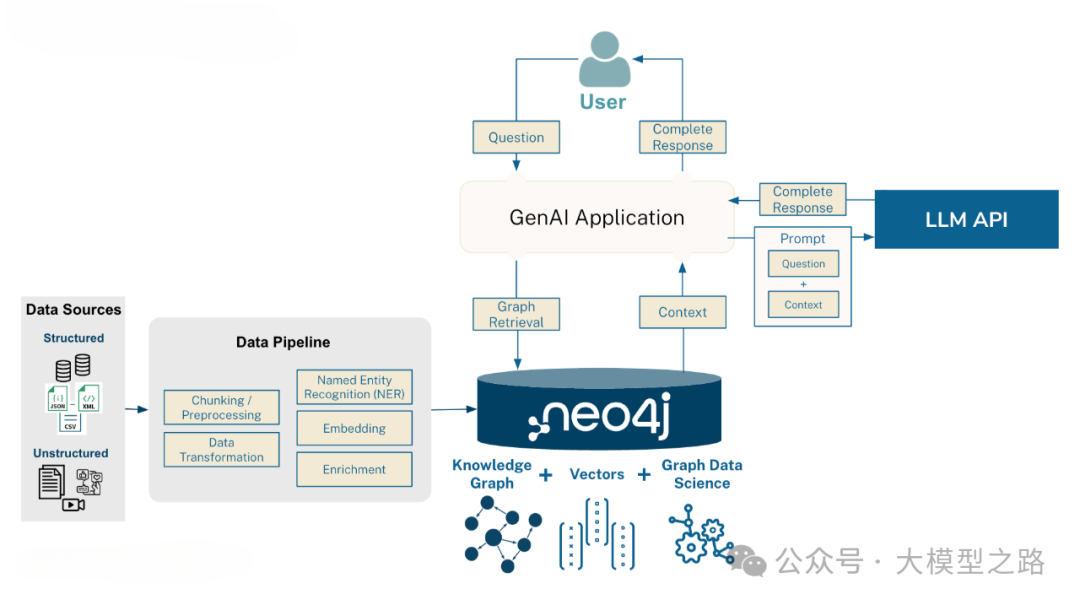
这篇文章的重点是:将graphrag输出的结果存储到Neo4j,然后通过langchain和llamaindex等框架实现基于Neo4j的检索能力
本次GraphRag实战使用的数据是Charles的“A Christmas Carol” (圣诞颂歌),之所以用这篇来测试,因为这篇文章的实体比较明确突出,提取起来简单准确,提取的过程这里不再赘述,可以参考上一篇文章GraphRag安装部署及简单测试,配置一下相关的模型参数,依然友情提示一下提取费用还是比较贵的,测试下来gpt-4o-mini相对性价比最高,成本也比较低,准确性也比较高。
graphrag结果导入Neo4j
graphrag生成的结果文件都是parquet文件,首先将这些文件导入到neo4j
import pandas as pdfrom neo4j import GraphDatabaseimport timeNEO4J_URI="bolt://localhost"NEO4J_USERNAME="neo4j"NEO4J_PASSWORD="password"NEO4J_DATABASE="neo4j"driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USERNAME, NEO4J_PASSWORD))
批量导入方法
def batched_import(statement, df, batch_size=1000):"""Import a dataframe into Neo4j using a batched approach.Parameters: statement is the Cypher query to execute, df is the dataframe to import, and batch_size is the number of rows to import in each batch."""total = len(df)start_s = time.time()for start in range(0,total, batch_size):batch = df.iloc[start: min(start+batch_size,total)]result = driver.execute_query("UNWIND $rows AS value " + statement,rows=batch.to_dict('records'),database_=NEO4J_DATABASE)print(result.summary.counters)print(f'{total} rows in { time.time() - start_s} s.')return total
然后依次导入文本、文本块、节点、节点关系、社区、社区总结,详情可以参考 https://github.com/tomasonjo/blogs/blob/master/msft_graphrag/ms_graphrag_import.ipynb
这里展示导入节点,其它信息类似导入
entity_df = pd.read_parquet(f'{GRAPHRAG_FOLDER}/create_final_entities.parquet',columns=["name","type","description","human_readable_id","id","description_embedding","text_unit_ids"])entity_df.head(2)entity_statement = """MERGE (e:__Entity__ {id:value.id})SET e += value {.human_readable_id, .description, name:replace(value.name,'"','')}WITH e, valueCALL db.create.setNodeVectorProperty(e, "description_embedding", value.description_embedding)CALL apoc.create.addLabels(e, case when coalesce(value.type,"") = "" then [] else [apoc.text.upperCamelCase(replace(value.type,'"',''))] end) yield nodeUNWIND value.text_unit_ids AS text_unitMATCH (c:__Chunk__ {id:text_unit})MERGE (c)-[:HAS_ENTITY]->(e)"""batched_import(entity_statement, entity_df)
全部数据导入完成后,在neo4j可以打开查看图形界面
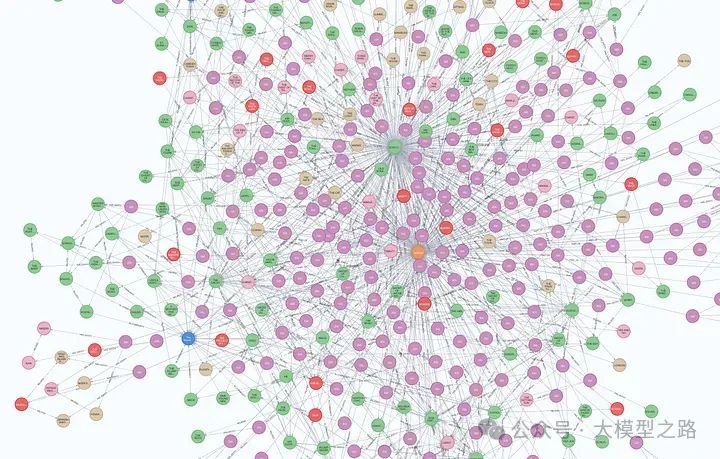
导入到neo4j我们就可以通过Cypher语句进行相关的查询,大家对Cypher语句感兴趣的可以自行查找资料,这里不过多介绍
结合langchain、llamaindex实现检索
在GraphRag-知识图谱结合LLM 的检索增强一文中我们介绍了graphrag提供了local search及global search,这里分别介绍一下二者的查询实现
local search
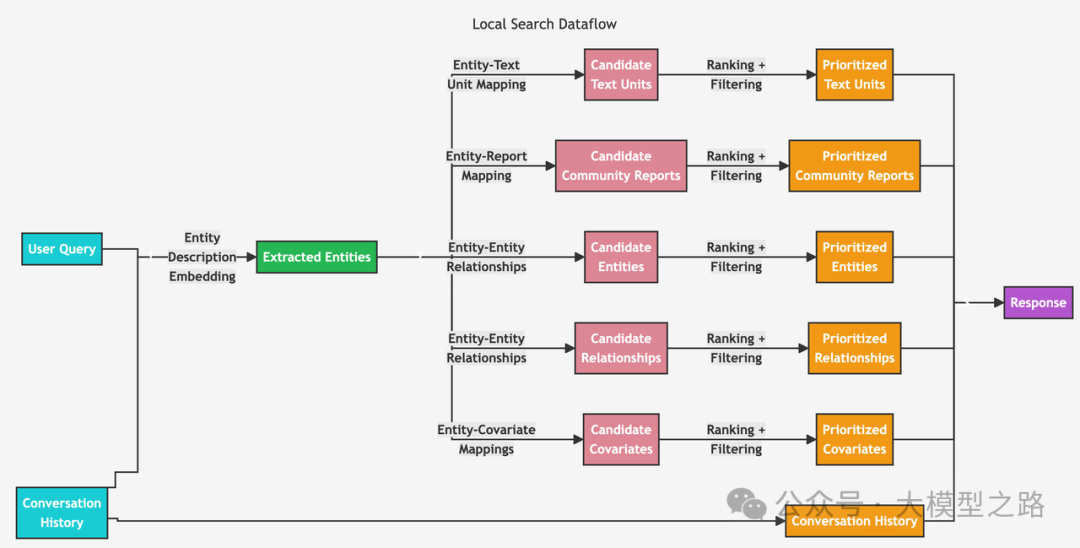
首先是基于langchain来实现local search,其实比较简单我们只需要实现retrieval_query即可
lc_retrieval_query = """WITH collect(node) as nodes// Entity - Text Unit MappingWITHcollect {UNWIND nodes as nMATCH (n)<-[:HAS_ENTITY]->(c:__Chunk__)WITH c, count(distinct n) as freqRETURN c.text AS chunkTextORDER BY freq DESCLIMIT $topChunks} AS text_mapping,// Entity - Report Mappingcollect {UNWIND nodes as nMATCH (n)-[:IN_COMMUNITY]->(c:__Community__)WITH c, c.rank as rank, c.weight AS weightRETURN c.summaryORDER BY rank, weight DESCLIMIT $topCommunities} AS report_mapping,// Outside Relationshipscollect {UNWIND nodes as nMATCH (n)-[r:RELATED]-(m)WHERE NOT m IN nodesRETURN r.description AS descriptionTextORDER BY r.rank, r.weight DESCLIMIT $topOutsideRels} as outsideRels,// Inside Relationshipscollect {UNWIND nodes as nMATCH (n)-[r:RELATED]-(m)WHERE m IN nodesRETURN r.description AS descriptionTextORDER BY r.rank, r.weight DESCLIMIT $topInsideRels} as insideRels,// Entities descriptioncollect {UNWIND nodes as nRETURN n.description AS descriptionText} as entities// We don't have covariates or claims hereRETURN {Chunks: text_mapping, Reports: report_mapping,Relationships: outsideRels + insideRels,Entities: entities} AS text, 1.0 AS score, {} AS metadata"""lc_vector = Neo4jVector.from_existing_index(OpenAIEmbeddings(model="text-embedding-3-small"),url=NEO4J_URI,username=NEO4J_USERNAME,password=NEO4J_PASSWORD,index_name=index_name,retrieval_query=lc_retrieval_query)
然后进行查询即可
docs = lc_vector.similarity_search("What do you know about Cratchitt family?",k=topEntities,params={"topChunks": topChunks,"topCommunities": topCommunities,"topOutsideRels": topOutsideRels,"topInsideRels": topInsideRels,},)# print(docs[0].page_content
llamaindex类似,llamaindex使用 f-string 而不是参数来传递top参数,代码如下
retrieval_query = f"""WITH collect(node) as nodes// Entity - Text Unit MappingWITHnodes,collect {{UNWIND nodes as nMATCH (n)<-[:HAS_ENTITY]->(c:__Chunk__)WITH c, count(distinct n) as freqRETURN c.text AS chunkTextORDER BY freq DESCLIMIT {topChunks}}} AS text_mapping,// Entity - Report Mappingcollect {{UNWIND nodes as nMATCH (n)-[:IN_COMMUNITY]->(c:__Community__)WITH c, c.rank as rank, c.weight AS weightRETURN c.summaryORDER BY rank, weight DESCLIMIT {topCommunities}}} AS report_mapping,// Outside Relationshipscollect {{UNWIND nodes as nMATCH (n)-[r:RELATED]-(m)WHERE NOT m IN nodesRETURN r.description AS descriptionTextORDER BY r.rank, r.weight DESCLIMIT {topOutsideRels}}} as outsideRels,// Inside Relationshipscollect {{UNWIND nodes as nMATCH (n)-[r:RELATED]-(m)WHERE m IN nodesRETURN r.description AS descriptionTextORDER BY r.rank, r.weight DESCLIMIT {topInsideRels}}} as insideRels,// Entities descriptioncollect {{UNWIND nodes as nRETURN n.description AS descriptionText}} as entities// We don't have covariates or claims hereRETURN "Chunks:" + apoc.text.join(text_mapping, '|') + "\nReports: " + apoc.text.join(report_mapping,'|') +"\nRelationships: " + apoc.text.join(outsideRels + insideRels, '|') +"\nEntities: " + apoc.text.join(entities, "|") AS text, 1.0 AS score, nodes[0].id AS id, {{_node_type:nodes[0]._node_type, _node_content:nodes[0]._node_content}} AS metadata"""
然后开始查询
neo4j_vector = Neo4jVectorStore(NEO4J_USERNAME,NEO4J_PASSWORD,NEO4J_URI,embed_dim,index_name=index_name,retrieval_query=retrieval_query,)loaded_index = VectorStoreIndex.from_vector_store(neo4j_vector).as_query_engine(similarity_top_k=topEntities, embed_model=OpenAIEmbedding(model="text-embedding-3-large"))response = loaded_index.query("What do you know about Scrooge?")print(response.response)#print(response.source_nodes[0].text)# Scrooge is an employee who is impacted by the generosity and festive spirit# of the Fezziwig family, particularly Mr. and Mrs. Fezziwig. He is involved# in the memorable Domestic Ball hosted by the Fezziwigs, which significantly# influences his life and contributes to the broader narrative of kindness# and community spirit.
global search
global search比较简单,它主要通过指定层级的社区摘要进行相似度匹配,但是决策使用哪一层级是一个比较困难的选择,级别越高社区越大,社区的概括摘要就越泛,同理社区越小摘要概括就越精细,这需要根据实际的业务场景进行合理的决策
def global_retriever(query: str, level: int, response_type: str = response_type) -> str:community_data = graph.query("""MATCH (c:__Community__)WHERE c.level = $levelRETURN c.full_content AS output""",params={"level": level},)intermediate_results = []for community in tqdm(community_data, desc="Processing communities"):intermediate_response = map_chain.invoke({"question": query, "context_data": community["output"]})intermediate_results.append(intermediate_response)final_response = reduce_chain.invoke({"report_data": intermediate_results,"question": query,"response_type": response_type,})return final_responseprint(global_retriever("What is the story about?", 2))
这篇文章主要是和大家分享一次GraphRag实战案例,如何将graphrag结果集成到neo4j中,并通过langchain和llamaindex等框架实现local search及global search,希望对大家有帮助


















 1205
1205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











