




 本文介绍了PyTorch库中的L1Loss函数,它是计算预测值与真实值之间L1距离的常用工具,适用于减少异常值影响的回归任务。L1Loss的特点在于对异常值不敏感,与L2损失相比,对较大误差的权重更低。文章还展示了如何在PyTorch中实例化和使用L1Loss进行训练过程中的损失计算。
本文介绍了PyTorch库中的L1Loss函数,它是计算预测值与真实值之间L1距离的常用工具,适用于减少异常值影响的回归任务。L1Loss的特点在于对异常值不敏感,与L2损失相比,对较大误差的权重更低。文章还展示了如何在PyTorch中实例化和使用L1Loss进行训练过程中的损失计算。
nn.L1Loss() 是 PyTorch 中的一个损失函数,属于 torch.nn 模块的一部分。它计算预测值和真实值之间差的绝对值的平均值,也就是 L1 距离(或曼哈顿距离)。这个损失函数常用于回归任务,特别是当你希望减少异常值对总体损失的影响时。L1 损失的一个特点是它对异常值不那么敏感,因为它不像平方误差损失(L2 损失)那样对较大的误差值赋予更高的权重。
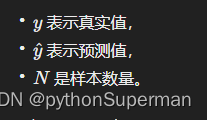
L1 损失的数学表达式是:

其中:
在 PyTorch 中使用 nn.L1Loss() 非常简单。首先,你需要实例化这个损失函数,然后在训练循环中调用它,将模型的预测输出和真实标签作为参数传入。例如:
import torch
import torch.nn as nn
# 假设 output 是模型的预测输出,target 是真实的标签
output = torch.randn(10, 2, requires_grad=True)
target = torch.randn(10, 2)
# 实例化 L1Loss 对象
criterion = nn.L1Loss()
# 计算损失
loss = criterion(output, target)
# 使用损失进行反向传播等
loss.backward()



















 1245
1245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









